我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看 过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记 录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查 找呢?
1. 用哈希表存储用户记录,缺点:浪费空间。
2. 用位图存储用户记录,缺点:不能处理哈希冲突。
3. 将哈希与位图结合起来,即布隆过滤器。
1.布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结 构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函 数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
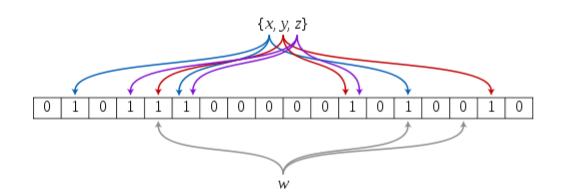
2.布隆过滤器的插入
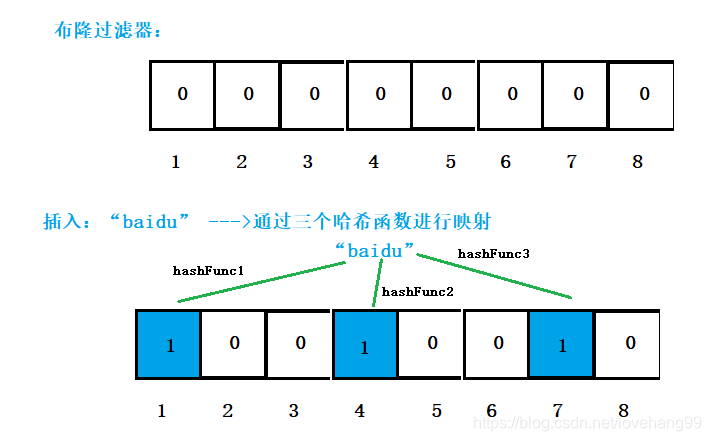
注意:在上面的插入中,hashFunc(哈希函数)的个数可以是多个,不一定是3个,上面仅仅是举例。
3.布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。 所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零, 代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因 为有些哈希函数存在一定的误判
误判的原因:
看例子:
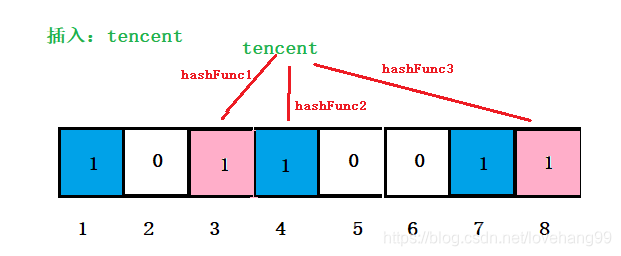
经过上面对过滤器中插入“baidu” 和 “tencent”后,过滤器中位置的情况如下:
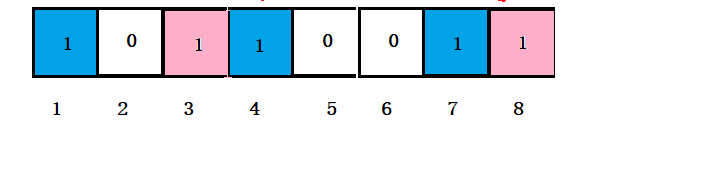
假如说“alibaba” 通过三个哈希函数映射的位置是 1 、 3 、7,但此时并没有将其插入到过滤器中,此刻我们去查找“alibaba”是否在过滤器中时会发现:1,3、7三个位置的值均为1,此时就会判断“alibaba”在过滤器中,然而事实并非如此。这就是产生误判的原因。
4.布隆过滤器的删除
大家都知道一个结构或者说是一个容器,都会支持插入和删除操作,而这次要留意的是,布隆过滤器是不支持删除操作的,原因很简单:
看上面的图我们看到:
插入“baidu” 时,1 、4、 7三个位置被置为了1。
插入“tencent” 时, 3、4、8三个位置被置为了1。
此时4的位置被不同的字符串同时映射到了,那么如果我们要把“baidu”从布隆过滤器中拿掉,我们怎么做?
按道理,应该将1、4、7三个位置重新置回0,但是如果这么做了,当我们查询“tencent”时,就会差不到,因为4的位置因为之前“baidu”的删除被值0了,因此就会产生误判。这只是简单两个数据映射到了同一个位置,在处理大量的数据时,一个位置可能会被很多数据映射到,贸然删除,必将引起较大的误判,因此布隆过滤器“不支持删除操作”。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
1. 无法确认元素是否真正在布隆过滤器中
2. 存在计数回绕
5.布隆过滤器的优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关 。
- 哈希函数相互之间没有关系,方便硬件并行运算。
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势。
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
6.布隆过滤器的缺陷
**1.有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白 名单,存储可能会误判的数据) 。
2.不能获取元素本身
7. 一般情况下不能从布隆过滤器中删除元素
8. 如果采用计数方式删除,可能会存在计数回绕问题
**
7.布隆过滤器的实现
实现代码:
布隆过滤器
