一、基本概念
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Google爬虫它要判断。哪些网页是被爬过来了的。
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路,但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。
不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构(有一个动态数组+ 一个hash函数)。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
总结起来说:
bloomfilter,布隆过滤器:迅速判断一个元素是不是在一个庞大的集合内,但是他有一个
弱点:它有一定的误判率误判率:原本不存在于该集合的元素,布隆过滤器有可能会判断说它存在,但是,如果布隆过滤器判断说某一个元素不存在该集合,那么该元素就一定不在该集合内。
二、布隆过滤器的优缺点
1、优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。
(1)布隆过滤器存储空间和插入/查询时间都是常数。
(2)另外, Hash函数相互之间没有关系,方便由硬件并行实现。
(3)布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
(4)布隆过滤器可以表示全集,其它任何数据结构都不能;
(5)k和m相同,使用同一组Hash函数的两个布隆过滤器的交并差运算可以使用位操作行。
(6)能快速的判断元素存在不存在,远远的缩小存储数据的规模。
2、缺点
但是布隆过滤器的缺点和优点一样明显。
(1)误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
(2)另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。
(3)另外计数器回绕也会造成问题。在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
3、使用场景考量
(1)存在一定的误判率,那么在你不能容忍有错误率的情况,布隆过滤器不适用;
(2)布隆过滤器不支持删除操作
三、实现原理
布隆过滤器需要的是一个位数组(跟位图(bitmap)类似, bytes数组)和K个映射函数(跟Hash表类似),在初始状态时,对于长度为m的位数组array,它的所有位被置0。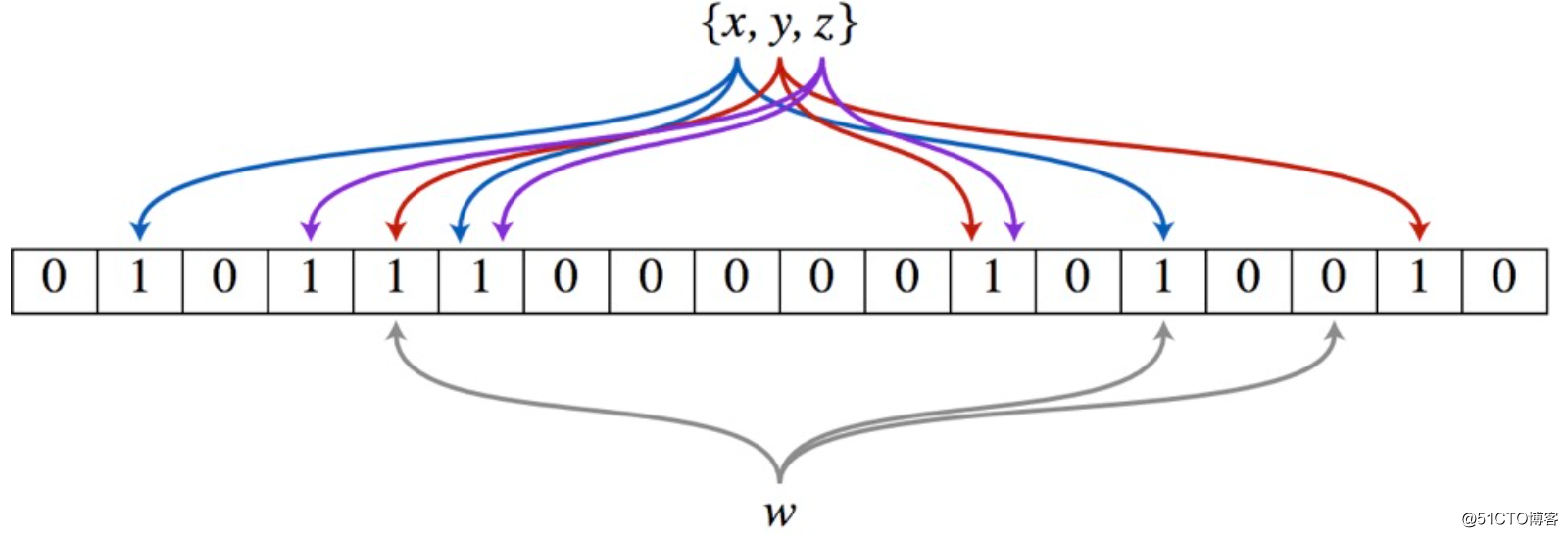
1、布隆过滤器添加元素
(1)对于有n个元素的集合S={S1,S2...Sn},通过k个映射函数{f1,f2,......fk};
(2)将集合S中的每个元素Sj(1<=j<=n)映射为k个值{g1,g2...gk},
(3)然后再将位数组array中相对应的array[g1],array[g2]......array[gk]置为1。
2、布隆过滤器查询元素
(1)查询W元素是否存在集合中的时候,将W通过哈希映射函数{f1,f2,......fk},得到集合g
(2)得到集合g的K个值{g1,g2...gk},对应位数组上的k个点。
(3)如果k个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果k个点都为1,则该元素可能存在集合中。
注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
3、自定义一个布隆过滤器的时候需要做的事情
(1)初始化一个位数组
(2)实现K个hash函数
(3)实现查询和插入操作
查询和插入操作需要做的事情:对插入进来的值进行hash计算,有几个hash函数,就计算几次,每次计算出来的结果值,都根据这个值,去位数组里面把相应位置的0变成1;
对查询操作来说,只需要把你要查询的这个key值进行k个hash函数的调用,然后再判断计算出来的这个k个值对应的维数组上的值是不是有一个为0,如果有一个为0,那就表示,该key不在这个集合里面。
四、哈希函数/哈希表
1、概念
哈希表中元素是由哈希函数确定的。将数据元素的关键字K作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址,也即一个元素在哈希表中的位置是由哈希函数决定的。
2、特点
(1)如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
(2)散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的。但也可能不同,这种情况称为 “散列碰撞”(或者 “散列冲突”)。
3、哈希构造方法
(1)直接定址法
取关键字或关键字的某个线性函数值为哈希地址。即H(key)=key 或 H(key)=akey+b (a,b为常数)。
(2)数字分析法
若关键字是以r为基的数(如:以10为基的十进制数),并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
(3)平方取中法
取关键字平方后的中间几位为哈希地址,是比较常用的一种。
(4)折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。适用于关键字位数比较多,且关键字中每一位上数字分布大致均匀时。
(5)除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址(p为素数)
H(key)=key MOD p,p<=m (最简单,最常用)p的选取很重要
一般情况,p可以选取为质数或者不包含小于20的质因数的合数(合数指自然数中除了能被1和本身整除外,还能被其他数(0除外)整除的数)。
(6)随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址。即H(key)=rando(key),其中random为随机函数。适用于关键字长度不等时。
总结:实际工作中根据情况不同选用的哈希函数不同,通常,考虑因素如下:
(1)计算哈希函数所需时间(包括硬件指令的因素)
(2)关键字的长度
(3)哈希表的大小
(4)关键字的分布情况
(5)记录的查找频率
4、哈希碰撞
概念:即两个不同的关键字,通过同一个哈希函数计算得出的结果值一样的。
5、解决哈希碰撞
(1)拉链法
拉出一个动态链表代替静态顺序存储结构,可以避免哈希函数的冲突,不过缺点就是链表的设计过于麻烦,增加了编程复杂度。此法可以完全避免哈希函数的冲突。
(2)多哈希法
设计二种甚至多种哈希函数,可以避免冲突,但是冲突几率还是有的,函数设计的越好或越多都可以将几率降到最低(除非人品太差,否则几乎不可能冲突)。
(3)开放地址法
开放地址法有一个公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。
如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置。
如果di取值可能为1,-1,4,-4,9,-9,16,-16,...kk,-kk(k<=m/2)称二次探测再散列。
如果di取值可能为伪随机数列,称伪随机探测再散列。
(4)建域法
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
五、误判率估计
现在我们了解了布隆过滤器的大致工作原理了,那我们就来计算一下这个误判率。
数组的大小:m
总共的数据大小为:n
hash函数的个数为:k假设布隆过滤器中的hash function(哈希函数)满足simple uniform hashing(单一均匀散列)假设:每个元素都等概率地hash到m个slot中的任何一个,与其它元素被hash到哪个slot无关。若m为bit数,则:
对某一特定bit位,在一个元素调用了某个hash函数之后,被改成了1的概率是:
对某一特定bit位,在一个元素由某特定hash function插入时没有被置位为1的概率为:
则k个hash function中没有一个对其置位为1的概率,也就是该bit位在 k 次hash之后还一直保持为0的概率:
如果插入了n个元素,但都未将其置为1,也就是当所有的元素都被插入进来以后,某一个特定的bit位还没有被改成1的概率:
则此位置被置为1(被改成了1)的概率,也就是当所有的元素都被插入进来以后,某一个特定的bit位被改成1的概率: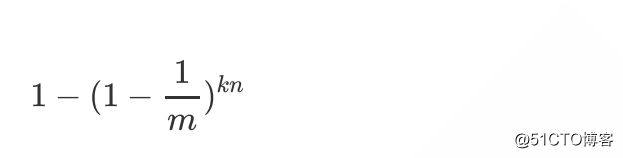
现在检测某一元素是否在该集合中。表明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),即k个位置都是1的概率以下公式确定:
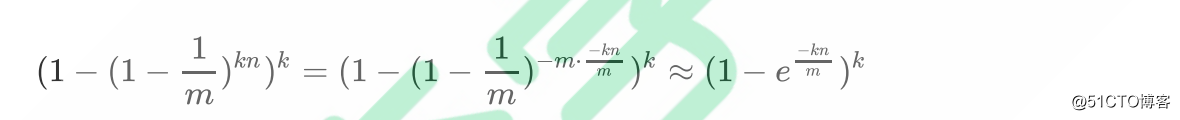
其实上述结果是在假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立为前提计算出来的,不难看出,随着 m(位数组大小)的增加,假正例(False Positives)的概率会下降,同时随着插入元素个数 n 的增加,False Positives的概率又会上升,对于给定的m,n。
(1)如何选择Hash函数个数 k 由以下公式确定:

推导过程:
由上面计算出的结果,现在计算对于给定的m和n,k为何值时可以使得误判率最低。设误判率为k的函数为:
翻译一下,也就是当m和n确定了以后,我们应该设置k为多少能使误判率最低呢?
当确定了m和n之后,我们要求出一个k使f(k)的值最小。
我们可以确定k,m,n三者之间的关系之后,我们可以保证误判率最小
首先,设
则上面的式子化简为: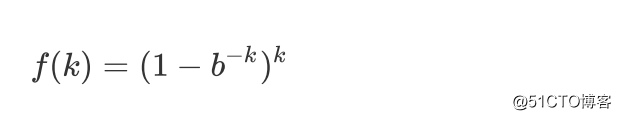
对两边都取对数,得出: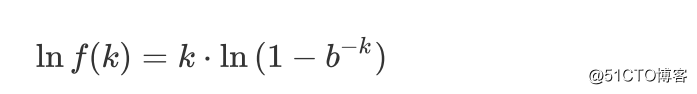
两边对k求导,得出: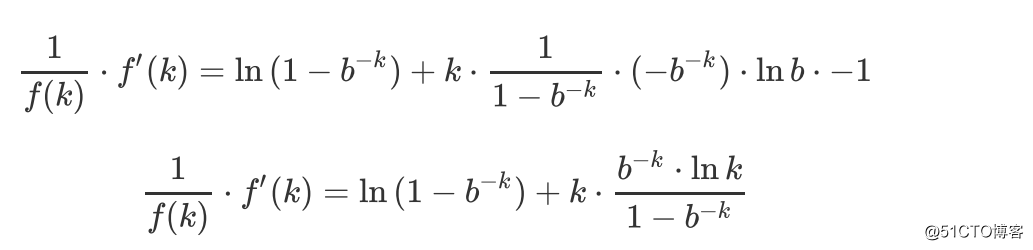
接着,来求最值: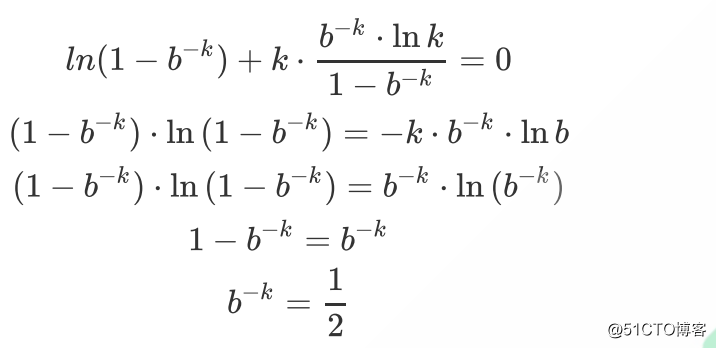
所以: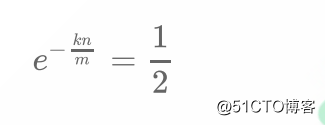
所以:
所以: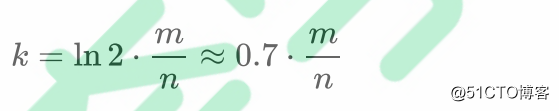
此时的误判率: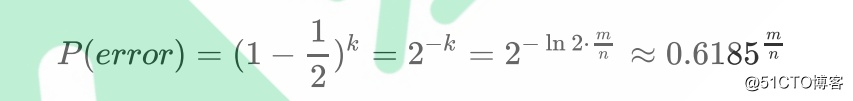
可以看出若要使得误判率≤1/2,则: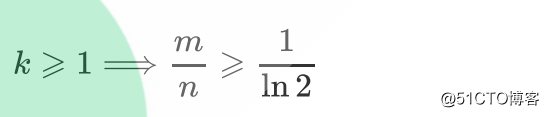
(2)而对于给定的False Positives概率 p,选择最优的位数组大小m的公式为:
上式表明,位数组的大小最好与插入元素的个数成线性关系,对于给定的 m,n,k,假正例概率最大为:

6、代码实现
(1)python代码实现
import mmh3
from bitarray import bitarray
# zhihu_crawler.bloom_filter
# Implement a simple bloom filter with murmurhash algorithm.
# Bloom filter is used to check wether an element exists in a collection, and it has a good performance in big data situation.
# It may has positive rate depend on hash functions and elements count.
BIT_SIZE = 5000000
class BloomFilter:
def init(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]```
# 7、总结
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
自从Burton Bloom在70年代提出Bloom Filter之后,Bloom Filter就被广泛用于拼写检查和数据库系统中。近一二十年,伴随着网络的普及和发展,Bloom Filter在网络领域获得了新生,各种Bloom Filter变种和新的应用不断出现。可以预见,随着网络应用的不断深入,新的变种和应用将会继续出现,BloomFilter必将获得更大的发展。