什么是布隆过滤器
布隆过滤器:一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。
如下所示:

原理
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
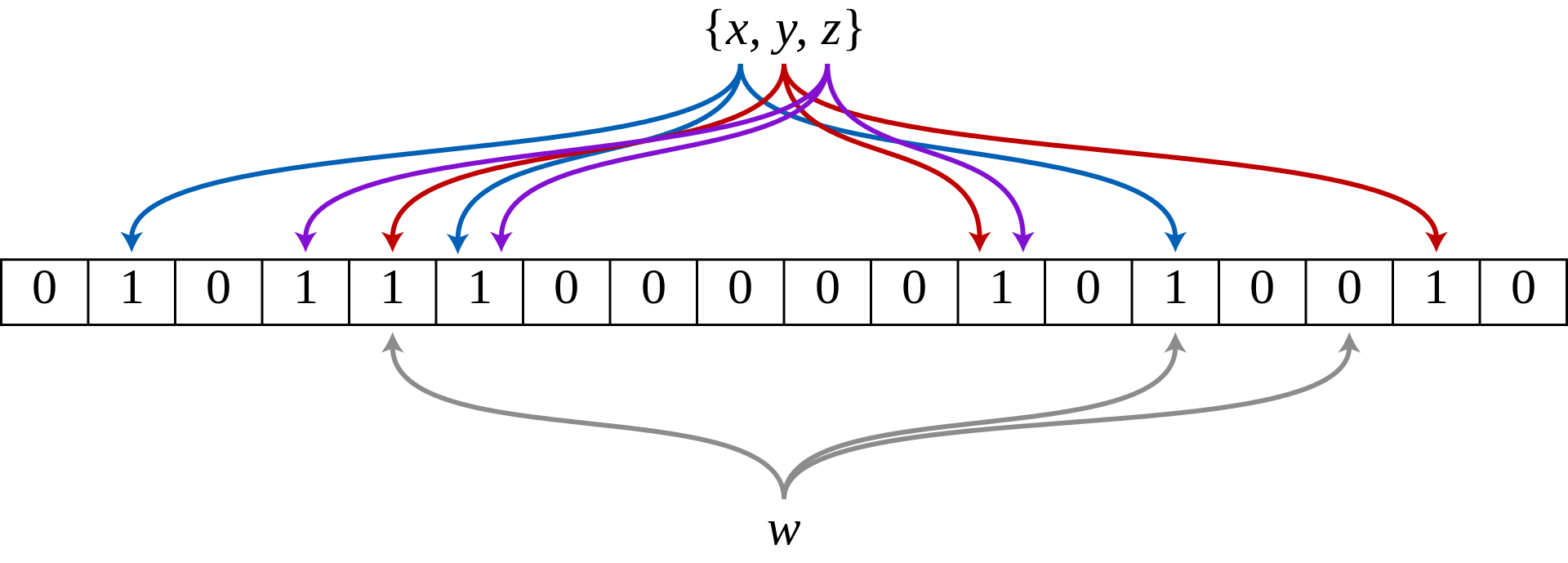
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中。
优缺点与用途
BF的优点是显而易见的:
不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
时间效率也较高,插入和查询的时间复杂度均为O(k);
哈希函数之间相互独立,可以在硬件指令层面并行计算。
但是,它的缺点也同样明显:
存在假阳性的概率,不适用于任何要求100%准确率的情境;
只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
所以,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,本文第一句话提到的用途即属于此类。另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓冲,防止缓存穿透。
应用场景
统计用户在线人数、解决缓存穿透问题、爬虫url去重、阅读列表去重等;
本文具体介绍解决缓存穿透的问题
什么是缓存穿透?
正常使用缓存查询数据的流程是,依据key去查询value,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
如果每次都查询一个不存在value的key,由于缓存中没有数据,所以每次都会去查询数据库;当对key查询的并发请求量很大时,每次都访问DB,很可能对DB造成影响;并且由于缓存不命中,每次都查询持久层,那么也失去了缓存的意义。
解决方法:
第一种是缓存层缓存空值
将数据库中的空值也缓存到缓存层中,这样查询该空值就不会再访问DB,而是直接在缓存层访问就行。
但是这样有个弊端就是缓存太多空值占用了更多的空间,可以通过给缓存层空值设立一个较短的过期时间来解决,例如60s。
第二种是布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,
当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
java简单实现布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
/**
* 预计插入数量
*/
private static int size = 1000;
/**
* 容错率
*/
private static double fpp = 0.001;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>();
//故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
结果:
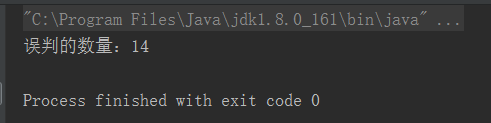
一万个数据中,14个误判了, 14 / 10000 = 0.0014, 和设置的容错率相近
在java中可实现布隆过滤器, 数据是存储的内存中的, 只有当前项目可用, 在别的项目中或许也有和当前项目使用重复的key, 这样是不是就做一些重复的工作, 还有就是项目重启则向量数组清除, 下次重启时,还需要再录入一次,这不是我们在真实的项目环境中的诉求, 下面介绍分布式布隆过滤器:
本文采用redis中string数据结构中bitmap实现分布式布隆过滤器
redis实现布隆过滤器两种方式
1、jedis或lettuce+谷歌的布隆过滤器算法实现
上代码:
1.1、pom依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
1.2、计算hash函数算法及offset
/**
* 计算hash函数算法及offset
*/
public class BloomFilterHelper<T> {
/**
* 散列函数
*/
private int numHashFunctions;
/**
* 二进制数组大小
*/
private int bitSize;
/**
* 过滤器
*/
private Funnel<T> funnel;
/**
* 预计插入数量
*/
private long expectedInsertions;
/**
* 容错率
*/
private double falseProbability;
public BloomFilterHelper(long expectedInsertions) {
this.funnel = (Funnel<T>) Funnels.stringFunnel(Charset.defaultCharset());
this.expectedInsertions = expectedInsertions;
bitSize = optimalNumOfBits(expectedInsertions, 0.03);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public BloomFilterHelper(Funnel<T> funnel, long expectedInsertions, double falseProbability) {
this.funnel = funnel;
this.expectedInsertions = expectedInsertions;
this.falseProbability = falseProbability;
bitSize = optimalNumOfBits(expectedInsertions, falseProbability);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
/**
* 计算在二进制数组中的位置
* @param value
* @return
*/
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
public int getNumHashFunctions() {
return numHashFunctions;
}
public int getBitSize() {
return bitSize;
}
public long getExpectedInsertions() {
return expectedInsertions;
}
public double getFalseProbability() {
return falseProbability;
}
}
1.3、redis实现布隆过滤器
/**
* 布隆过滤器redis实现
*/
@Service
public class RedisBloomFilter2<T> {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 布隆过滤器名称
*/
@Value("${spring.redis.boomFilter.name}")
private String boomFilterName;
@Autowired
private BloomFilterHelper<Object> bloomFilterHelper;
/**
* 删除布隆过滤器
*/
public void delete() {
redisTemplate.delete(boomFilterName);
}
/**
* 通过布隆过滤器计算出redisKey所在二进制数组的位置,设置所在位置的值为true,
* (批量添加的性能差,采用管道的方式)
* @param value 值 redis key
* @param <T> 泛型,可以传入任何类型的value
*/
public <T> void add( T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
redisTemplate.executePipelined(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection redisConnection) throws DataAccessException {
redisConnection.openPipeline();
for (int i : offset) {
redisConnection.setBit(boomFilterName.getBytes(), i, true);
}
return null;
}
});
}
/**
* 通过布隆过滤器计算出redisKey所在二进制数组的位置,设置所在位置的值为true,
* (批量添加的性能差,采用管道的方式)
* 使用pipeline方式(如果是集群下,请使用优化后RedisPipeline的操作)
*
* @param valueList 值,redis key列表
* @param <T> 泛型,可以传入任何类型的value
*/
public <T> void addList(List<T> valueList) {
redisTemplate.executePipelined(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (T value : valueList) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
connection.setBit(boomFilterName.getBytes(), i, true);
}
}
return null;
}
});
}
/**
* (根据给定的布隆过滤器判断值是否存在)
* 通过布隆过滤器计算出redisKey所在二进制数组的位置,判断所在位置上的值是否为true,
* 如果一个位置的值为false,则判断该值一定不存在
* 如果所有位置的值为true,则该值不一定存在(或许和其他key计算的hash相同)(有误差率)
*
* @param value 值 redis key
* @param <T> 泛型,可以传入任何类型的value
* @return 是否存在
*/
public <T> boolean contains(T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection redisConnection) throws DataAccessException {
redisConnection.openPipeline();
for (int i : offset) {
redisConnection.getBit(boomFilterName.getBytes(), i);
}
return null;
}
});
if (objects.contains(Boolean.FALSE)){
return false;
}
return true;
}
/**
* 预计插入数量
* @return
*/
public long getExpectedInsertions() {
return bloomFilterHelper.getExpectedInsertions();
}
/**
* 失误率
* @return
*/
public double getFalseProbability() {
return bloomFilterHelper.getFalseProbability();
}
/**
* hash函数个数
* @return
*/
public int getHashIterations() {
return bloomFilterHelper.getNumHashFunctions();
}
/**
* 二进制数组大小
* @return
*/
public int getSize() {
return bloomFilterHelper.getBitSize();
}
/**
* 所存对象的数量
* @return
*/
public long count() {
Long bitcCount = redisTemplate.execute(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection redisConnection) throws DataAccessException {
return redisConnection.bitCount(boomFilterName.getBytes());
}
});
return Math.round((double)(-getSize()) / (double)getHashIterations() * Math.log(1.0D - (double)(Long)bitcCount / (double)getSize()));
}
}
1.4、配置类
/**
* 配置类
*/
@Configuration
public class RedisBloomFilterConfig {
/**
* 预计大小
*/
@Value("${spring.redis.boomFilter.expectedInsertions}")
private long expectedInsertions;
/**
* 误差率
*/
@Value("${spring.redis.boomFilter.fpp}")
private double fpp;
@Bean
public BloomFilterHelper bloomFilterHelper(){
return new BloomFilterHelper<>(Funnels.stringFunnel(Charset.defaultCharset()), expectedInsertions, fpp);
}
}
1.5、客户端的使用请根据实际情况选择
1.6、使用
@Autowired
private RedisBloomFilter<Object> redisBloomFilter;
@RequestMapping("redisBoolmFilterSave")
@ResponseBody
public String save(String key){
long start = System.currentTimeMillis();
redisBloomFilter.add(key);
return "耗时:" + (System.currentTimeMillis() - start) + "ms";
}
@RequestMapping("query")
@ResponseBody
public String query(String key){
boolean contains = redisBloomFilter.contains(key);
return key + " 是否存在:" + contains;
}
2、redisson实现
2.1、redisson pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.1</version>
</dependency>
2.2、 配置
/**
* redisson配置
*/
@Configuration
public class RedissonClientConfig {
/**
* Redis 集群配置
*/
@Value("${spring.redis.cluster.nodes}")
private String clusterNodes;
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient(){
Config config = new Config();
ClusterServersConfig clusterServersConfig = config.useClusterServers();
String[] cNodes = clusterNodes.split(",");
//分割出集群节点
for (String node : cNodes) {
clusterServersConfig.addNodeAddress("redis://" + node);
}
return Redisson.create(config);
}
/**
* redisson哨兵模式配置
*/
/*@Autowired
private RedisProperties redisProperties;
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient(){
Config config = new Config();
SentinelServersConfig sentinelServersConfig = config.useSentinelServers();
sentinelServersConfig.addSentinelAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());
sentinelServersConfig.setPassword(redisProperties.getPassword());
return Redisson.create(config);
}*/
/**
* redisson单机配置
*/
/*@Autowired
private RedisProperties redisProperties;
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient(){
Config config = new Config();
SingleServerConfig singleServerConfig = config.useSingleServer();
singleServerConfig.setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());
singleServerConfig.setPassword(redisProperties.getPassword());
return Redisson.create(config);
}*/
}
2.3、 使用
@Autowired
private RBloomFilter<String> bloomFilter;
@RequestMapping("redisBoolmFilterSave")
@ResponseBody
public String save(String key){
long start = System.currentTimeMillis();
bloomFilter.add(key);
return "耗时:" + (System.currentTimeMillis() - start) + "ms";
}
@RequestMapping("query")
@ResponseBody
public String query(String key){
boolean contains = bloomFilter.contains(key);
return key + " 是否存在:" + contains;
}