python零基础入门爬虫
先说明一下,本人是iOS移动开发者。年假期间,受疫情影响闲来无事,写一点儿爬虫程序消磨时间,顺便爬一些喜欢的东西满足一下自己的好奇心。
闲话少说,自己入门爬虫一周时间遇到一些坑,写这篇文章的目的是给新手一些建议,少浪费时间。
**1.**环境支持:爬虫程序需要的软件支持这里不过多赘述,首先要有python环境。这里我建议使用Anaconda科学计算环境,Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项,后期做爬虫需要很多库,它们之间还会有很多依赖,稍微不留神就会出现看不懂的恶心问题,尤其是在Windows系统下,而使用Anaconda这些问题会变得很方便。该环境的安装方法网上有很多(随便拉一条:Anaconda 入门安装教程)这里再补充一句,Anaconda官网不翻墙无法访问,国内一般都用清华大学的开源软件镜像网站(附上链接:清华大学开源软件镜像站)
**2.**IDE:一般都用pycharm
**3.**上手先找个简单的静态网站(相反还有动态的网站,爬取相对复杂),比如说一个简单的小说网站:笔趣看
**4.**爬虫的本质是网络请求和数据处理,网络请求没啥可说的,用requests框架就可以。数据处理基本上就是对网页的HTML字符进行截取,这一项操作建议新手先学会基本的用正则表达式匹配自己想要提取的内容,然后再用库。
**5.**很多新手都说:网上的爬虫代码很多粘下来运行得不到想要的结果(之前我也没少干这事儿),总结下来有三方面原因:①年代久远,爬的网站不能访问了。②网站的结构发生了变化,原先代码的提取逻辑不适用了。③要知道当下互联网发展很快的,之前很多网站都是用的HTTP协议,但是它存在着安全隐患,如今大部分都是用的HTTPS协议。对爬虫程序来说的话就是需要在请求链接的基础上,加上headers参数:Cookie、User-Agent…依实际情况而定(User-Agent头域的内容包含发出请求的用户信息;Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息)
**6.**爬完了静态的简单网页,动态的复杂网页怎么爬取呢。动态网页与静态网页的区别就在于:
静态网页:
(1)静态网页不能简单地理解成静止不动的网页,他主要指的是网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html,.htm,或者.xml等。虽然静态网页的页面一旦做成,内容就不会再改变了。但是,静态网页也包括一些能动的部分,这些主要是一些GIF动画等
(2)静态网页的打开,用户可以直接双击,并且不管任何人任何时间打开的页面的内容都是不变的。
动态网页:
(1)动态网页是指跟静态网页相对的一种网页编程技术。动态网页的网页文件中除了HTML标记以外,还包括一些特定功能的程序代码,这些代码可以使得浏览器和服务器可以交互,所以服务器端根据客户的不同请求动态的生成网页内容。
即:动态网页相对于静态网页来说,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
(2)动态网页,与网页上的各种动画、滚动字幕等视觉上的动态效果没有直接关系,动态网页也可以是纯文字内容的,也可以是包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,只要是采用了动态网站技术(如PHP、ASP、JSP等)生成的网页都可以称为动态网页。
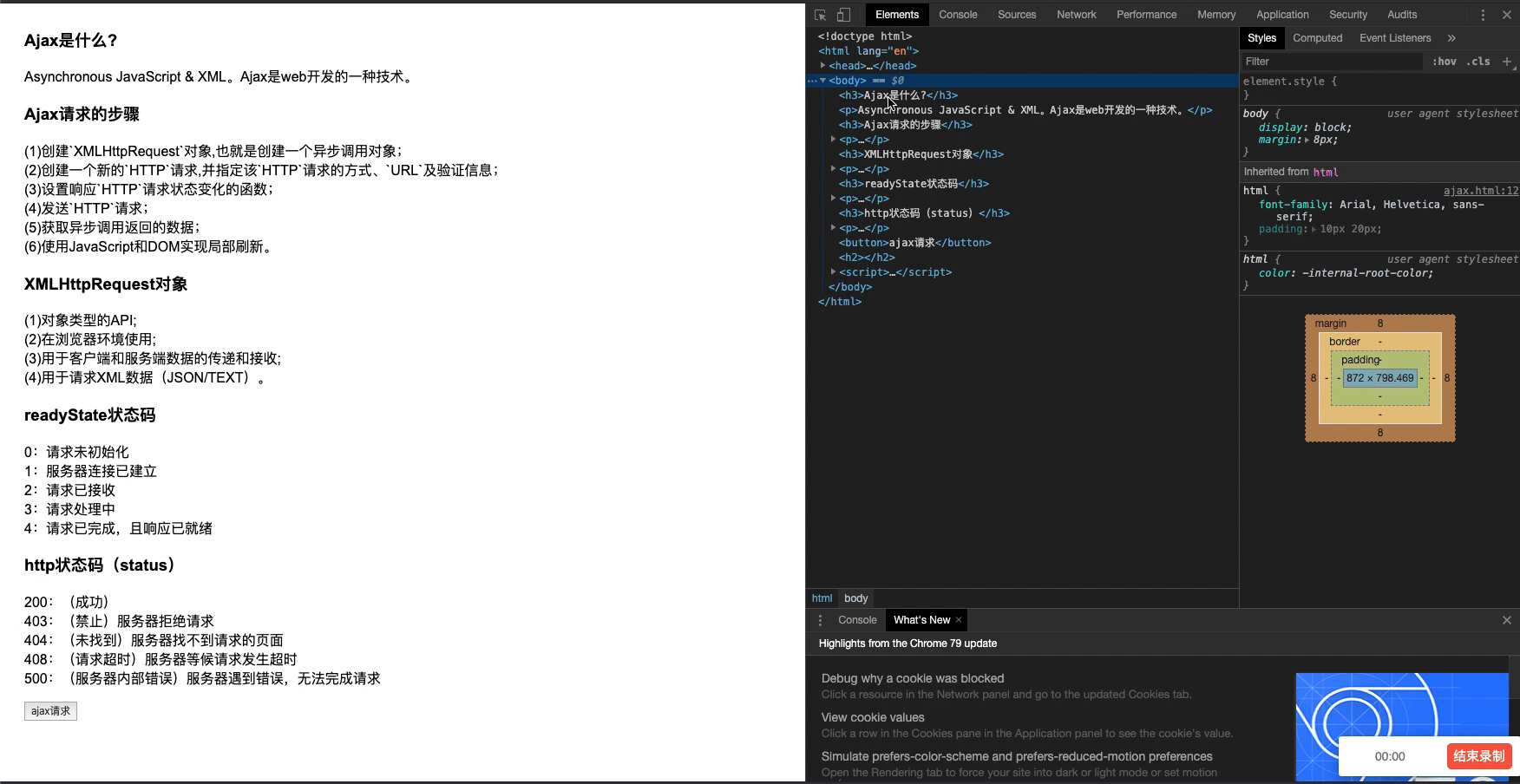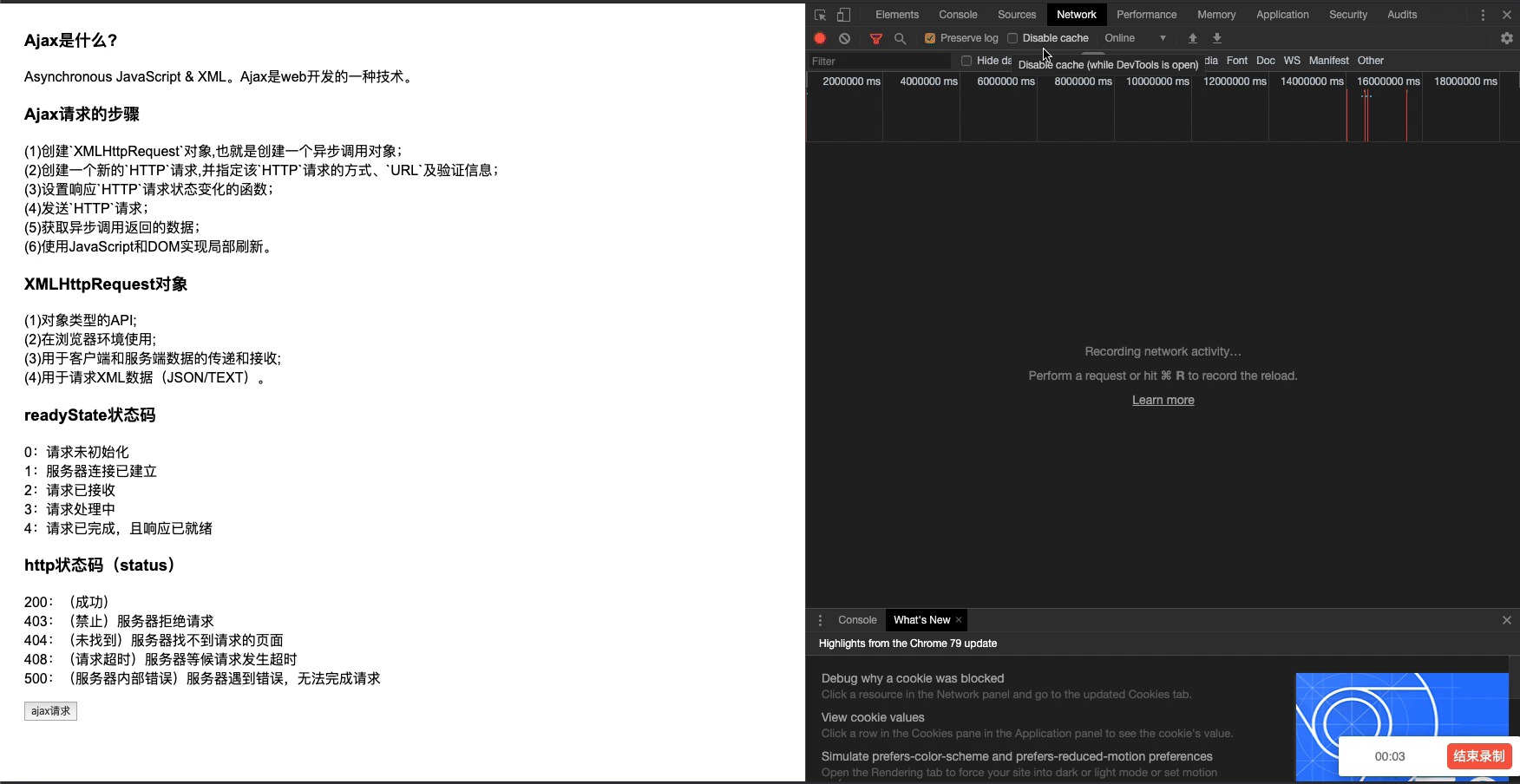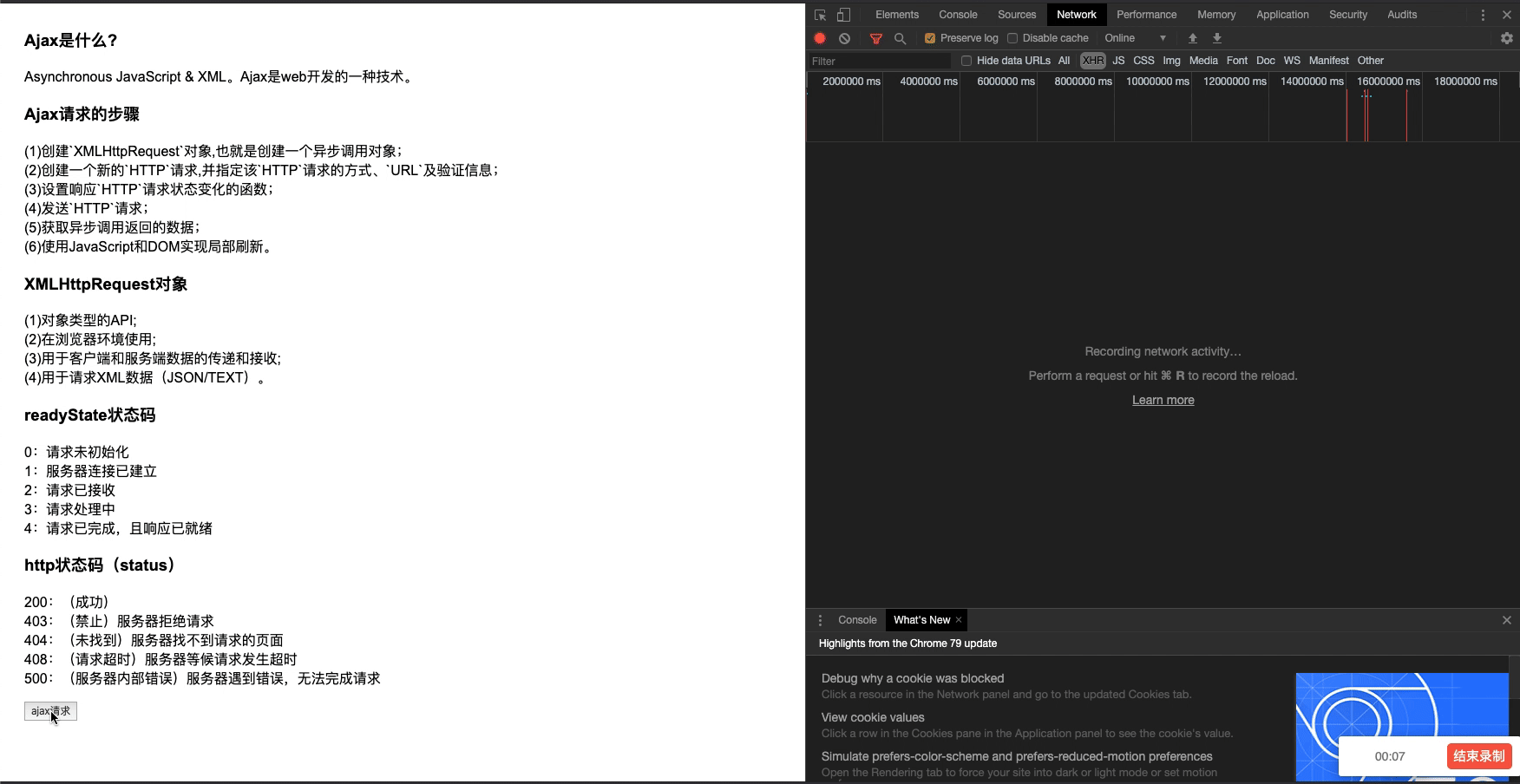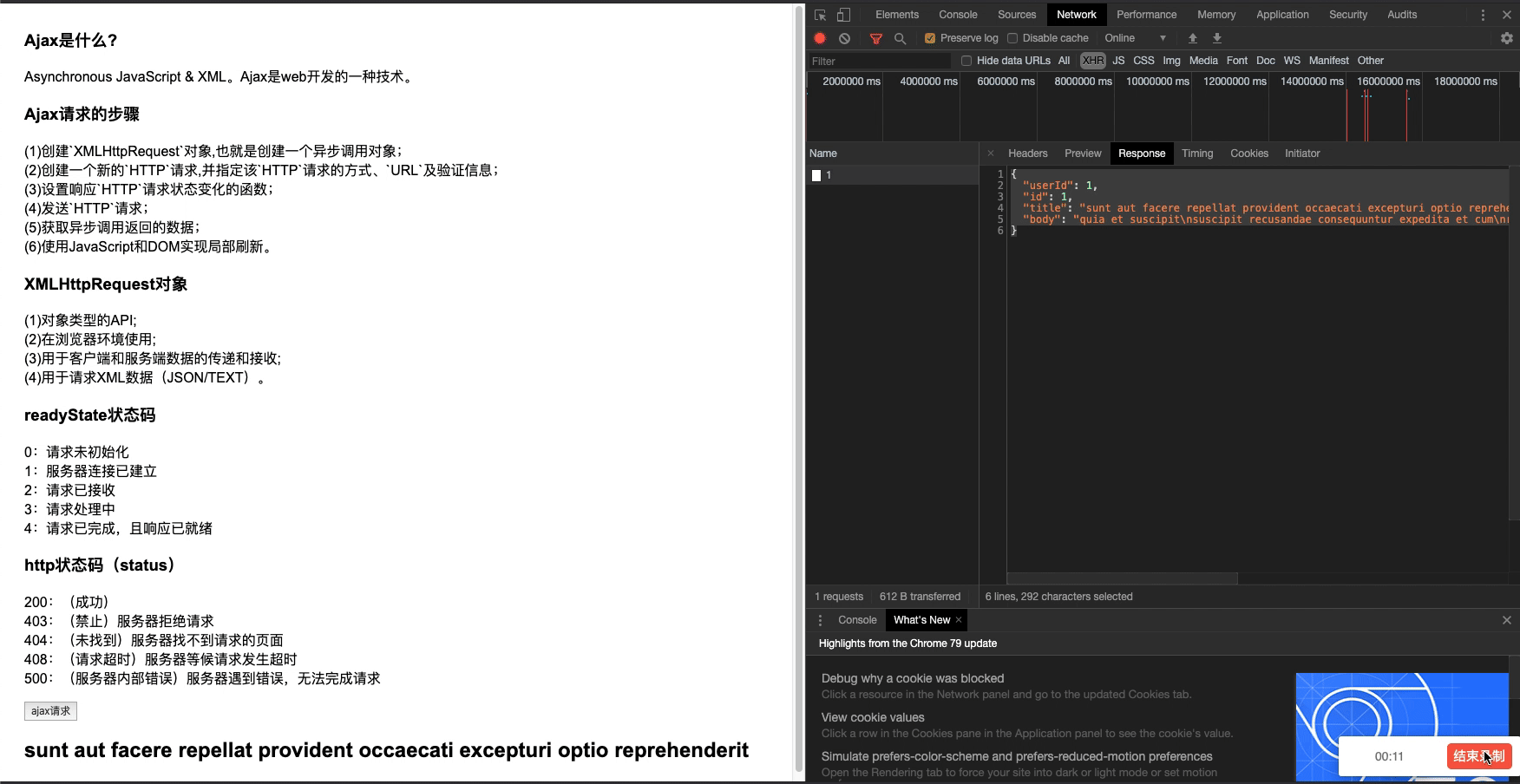
简单来说就是在python程序中请求网页地址下来内容和在网页上查看的html代码不一样,想要获取网页上的内容需要对其他的隐藏的数据请求进行分析。
下面举个栗子,告诉大家怎么分析、查找网页的Ajax请求(附上:什么是Ajax以及ajax请求的步骤)
先说这么多吧,后面肯定还会继续踩坑…
