目录
下载Python环境包 https://www.python.org/
浮点数转整数、字符串转整数、字符串转浮点数、任意类型转字符串
center(int) 往左右两边填空格,补足int个数字符
count(element[, start, end]) 获取element出现个数
endswith(element[, start, end]) 判断字符串是否以element结尾
expandtabs() 将\t转换成空格,默认是与前面的字符串共同构成8个占位符
find(element [, start, end]) 寻找element所在的开始索引值
startswith(prefix[,start,end])
列表、元组和字符串的共同点,它们的实现都有序列(迭代器)概念。
sorted(iterable, key=None, reverse=False)
下载Python环境包 https://www.python.org/
一、监听输入、字符串转整数、分支、打印、循环
import random
secret = random.randint(1,10)
print("-----------------------笑嘻嘻---------------")
temp = input("猜猜是哪个数字,输入数字:")
guess = int(temp)
if guess == secret: #加: 回车下一行进行缩进Tab,若没有缩进相当于在if{}外面而非里面
print("猜中!")
else:
if guess > secret:
print("大了 大了 猜想值比这个小!")
else:
print("小了小了 小小小")
i = 0
while guess != secret and i < 2:
i = i + 1
temp = input("猜错了,请再次输入数字:")
guess = int(temp) #input获取到的是string,这里转整数(int)
if guess == secret: #加: 回车下一行进行缩进Tab,若没有缩进相当于在if{}外面而非里面
print("猜中!")
else:
if guess > secret:
print("大了 大了 猜想值比这个小!")
else:
print("小了小了 小小小")
print("游戏结束~")#这里就已经跳出到else{}外面了二、Python数据类型(注意Python对大小写敏感)
数据类型
整数int、浮点数float、布尔类型bool、字符串str
类型转换内置函数
转整数int() 转浮点数float() 转字符串str()
布尔类型:True和False (在数学运算里True为1,False为0)(注意Python对大小写敏感,如果写成是true就无效了)

浮点数转整数、字符串转整数、字符串转浮点数、任意类型转字符串


![]()

Python允许使用int、float、str作为变量名,此时它们会赋予另一个身份而不再是内置函数,例如

获取变量类型 type()

判断变量是否属于某个类型 isinstance()
![]()
三、算术运算
算术操作符
+、-、*、/、%、**、//
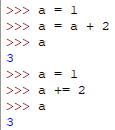


关于/运算,它是真正的除法运算,即使2个数是整数类型,它依然能返回的是浮点数,例如: 3/2 = 1.5,而C#是返回1


关于//运算,它是C#中的/即整数除法,目前观察是会将结果向下取整返回。注意3.3 // 2也是将结果向下取整的!
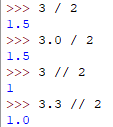
求幂运算

多重赋值
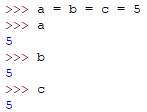
逻辑操作符
and、or、not

3 < 4 < 5 等于 3<4 and 4<5

三元操作符
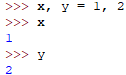

运算符优先级
除了**求幂,其他都是与传统上优先级一样理解
**的优先级会高于左侧任意运算符,低于右侧任意运算符
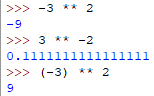
四、循环体
while循环
while 条件:
循环体
PS:需注意Python是根据Tab来进行约束语句块{}的,例如上方的代码块必须比上一行多一个Tab才正确!for循环
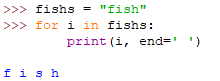

range([start,] stop [,step=1])
start开始索引,stop结束索引(注意不包含结束索引自身),step步长



break和continue语句


注意:continue案例的 i+=2 并不会影响到遍历的i变量。这可能是py的特殊机制,即每次i都是从range(10)的迭代器里面取值,而 i += 2 即 i = i + 2实际上已经是新的一个变量i了,并不会影响到迭代器里的数据。
五、数据结构
列表

append函数 尾部追加元素

extend函数 尾部扩展列表

[关联知识点] 列表的运算操作
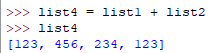

insert函数 插入第一个参数指定的索引位置,从0开始。
![]()
查询和交换元素操作

移除元素

根据索引值删除元素

删除整个列表

pop移除列表元素,默认移除尾部元素,可指定移除索引值

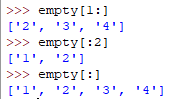
列表分片 list[start:end] 不会影响原列表数据,即它类似深拷贝出一个列表对象返回。

列表count(element)内置函数
获取列表element数值的个数
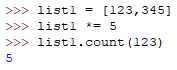
列表index(element [,start,end])
从列表搜索出element数值所在的索引值,默认为0开始到列表最后一个元素,可指定开始索引和结束索引(搜索区域不包含结束索对应的身元素)


列表reverse()
反转列表, 注意它是改变了自身的

列表sort()
升序排序

倒序排序
![]()
归并排序(留坑补全)
list3.sort(func, key)
func是比较函数,key是比较函数所需的关键字
六、列表的一些常用操作符
比较操作符
列表比较类似字符串比较,从左到右依次对应比较,当有一个满足得出小于或大于结果时返回,当相同时继续比较,若全相同则代表相同。

逻辑操作符
![]()
连接操作符
将2个列表拼接在一起返回
重复操作符
![]()
成员关系操作符
in 操作符只判断列表首层的元素,不会继续从嵌套列表里找。


七、元组
1、元组不可操作,初始化后就无法对它进行增删改!查是可以查的。
2、元组可使用()创建,列表可使用[]创建
3、元组的其他操作与列表基本一样。
空元组

仅有一个元素的元组

元组的重复操作

元组的插入操作
注意它并没有操作元组数组(增删改),而是拷贝元组和拼接成一个新的元组。
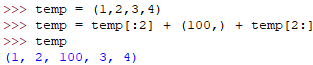
元素的删除操作
同插入一样的原理使用分片方式进行实现

八、字符串内置函数
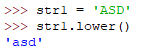
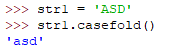
lower 大写字符转小写
casefold() 大写转小写
capitalize() 大写开头其余小写

center(int) 往左右两边填空格,补足int个数字符
![]()
count(element[, start, end]) 获取element出现个数
![]()
endswith(element[, start, end]) 判断字符串是否以element结尾
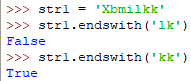
expandtabs() 将\t转换成空格,默认是与前面的字符串共同构成8个占位符
例如: I后面有7个空格,与'I'构成8个占位符,而love后面有4个空格,与'love'构成8个占位符
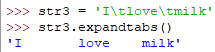
find(element [, start, end]) 寻找element所在的开始索引值
注意 是从左到右寻找的,若没找到则返回-1

index(element [, start, end])
与find函数一样,但若找不到则会报异常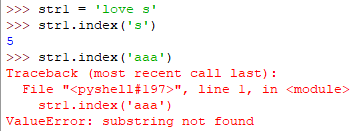
isalnum()
如果字符串至少有一个字符且所有字符是(数字或字符)则返回True,否则返回False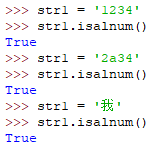
![]()
isalpha()
如果字符串至少有一个字符且都是数字则返回True,否则返回False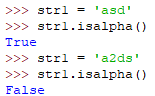
isdecimal()
如果字符串只包含"+"正整数数字则返回True,否则返回False
isdigit()
如果字符串只包含'+'正整数数字则返回True,否则返回False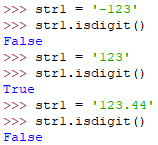
islower()
如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写则返回True,否则返回False![]()
isnumeric()
如果字符串中只包含"+"正整数数字字符,则返回True,否则返回False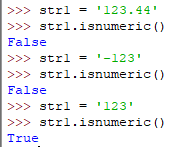
isspace()
如果字符串中只包含空格,则返回True,否则返回False
istitle()
如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回True,否则返回False

isupper()
所有字符都是大写的返回True,否则返回False
join(sub)
以字符串为分隔符,插入到sub中所有的字符之间
ljust(width)
返回一个左对齐的字符串,并使用空格填充至长度为width的新字符串。
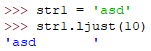
lstrip()
去掉字符串首部的所有空格
![]()
rstrip()
去掉字符串末尾的所有空格
partition(sub)
从左边开始找到子字符串sub,把字符串分成一个3元组(pre_sub, sub, fol_sub), 如果字符串中不包含sub则返回('原字符串', ' ' , ' ')
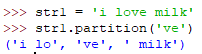
replace(old,new[,count])
替换old为new,替换count次停止替换,若没指定count则一直替换
rfind(sub[,start,end])
从右边开始查找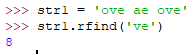
rindex(sub[,start,end])
从右边开始获取索引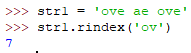
rjust(width)
返回一个右对齐的字符串,并使用空格填充至长度为width的新字符串。![]()
rpartition(sub)
从右边开始找到子字符串sub,把字符串分成一个3元组(pre_sub, sub, fol_sub), 如果字符串中不包含sub则返回('原字符串', ' ' , ' ')
split(sep=None, maxsplit=-1)
默认不指定sep时以空格作为分隔符切割字符串, 指定maxsplit确定切割次数。![]()

startswith(prefix[,start,end])
检查字符串开头是否存在prefix字符串,若有则返回True,否则返回False![]()
strip([chars])
默认删除字符串首尾所有空格字符,chars参数用于指定删除字符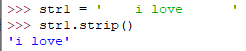
swapcase()
翻转字符串中的大小写字符
title()
返回标题化的字符串![]()
translate(table)
根据table的规则(可以由str.maketrans('a', 'b')定制) 转换字符串中的字符
即将字符串中的'a'转成'b'
upper()
字符串小写转大写![]()
zfill(width)
返回长度为width的字符串,原字符串右对齐,前边用0填充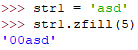
字符串格式化
![]()
{0}对应'I' {1}对应'Milk'
![]()
{a}对应'I' {b}对应'Milk' 使用关键字参数指定
![]()
混合使用两种,但要确保{0}索引指定必须在关键字指定之前进行,否则会报错![]()
格式化打印{}的方法,即加多一个{ 或 }进行翻译出真实的 { 和 } 字符
保留1位小数 四舍五入格式化![]()
%c 将ASCII码转为字符![]()
![]()
%s 将内容格式化为字符串![]()
%d 格式化为整数![]()
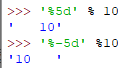
%5d是指最小5个占位符,若不足用空格从左边补足
%-5d是指最小5个占位符,若不足用空格从右边补足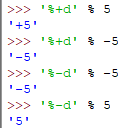
默认%d是属于%-d的情况,若需正数显示出'+'符号,则使用'%+d'![]()
%05d是用'0'字符来从左边补足占位符达到5个![]()
%0-5d不会出现用'0'从右边补足,因为防止出BUG
%o 格式化为8禁止![]()
![]()
%#o的#会显示出0o在输出的八进制数值前面,代表这个数字是八进制的
%x 无符号十六进制小写![]()
![]()
%#x的#会显示出Ox在输出的十六进制数值前面,代表这个数字是十六进制的
%X 无符号十六进制大写![]()
%f 格式化定点数,可指定小数点后的精度![]()
![]()
%5.1f的5是指格式化最小占位符为5,.1f是指四舍五入保留一位小数
%e 用科学计数法格式化定点数![]()
![]()
%.1是指将科学计数法的小数四舍五入保留一位小数,注意是将转化为科学技术法后的小数四舍五入的!
%E 作用同%e,用科学计数法格式化定点数![]()
%g 根据值的大小决定使用%f或%e![]()
![]()
%G 作用同%g,根据值的大小决定使用%f或%e![]()
![]()
九、序列!序列!(迭代器!)
列表、元组和字符串的共同点,它们的实现都有序列(迭代器)概念。
- 都可以通过索引得到每一个元素
- 默认索引值总是从0开始
- 可通过分片[:]的方法得到一个范围内的元素
- 有很多共同的操作符(重复操作符、拼接操作符、成员关系操作符)
list() 新建空列表
list(iterable)
根据iterable(迭代器)新建一个列表


tuple(iterable)
根据iterable(迭代器)新建一个元组(操作与list同理)
len(iterable)
返回iterable迭代器的存储元素个数
![]()
max(interable)
返回iterable迭代器的最大元素值(ASCII码最大值)

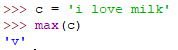
min(interable)
返回iterable迭代器的最小元素值(ASCII码最小值)
![]()
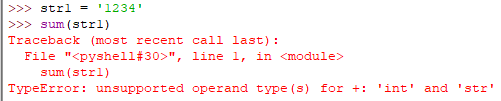
关于max、min、sum方法使用必须保证序列的元素类型统一,例如全部为int,若出现不统一会报错TypeError,并告知内部有具体什么类型冲突引起.
例如 下方例子是str()和int()2个类型的冲突.

sum(iterable [, start=0])
返回序列iterable迭代器和可选参数start的总和 ,sum()无法对字符串迭代器进行求总和.

sorted(iterable, key=None, reverse=False)
排序迭代器自身用法与list.sort一致

reversed(sequence)
反转迭代器,返回的是一个list_reverseinterator对象

enumerate(iterable[, start])
可选start开始索引值将迭代器的元素变成一个元组(索引+start, 元素)形式存储,最终返回一个enumerate对象

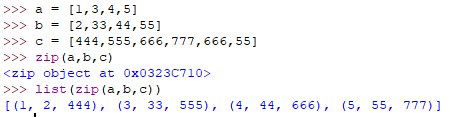
zip(iter1 [,iter2 [...]])
将多个iter迭代器组合成zip object内部是一个元组形式组合的,只组合公共部分,其余部分忽略。
十、方法(函数)
def 方法名():
执行代码块
方法名()无参 无返回值方法
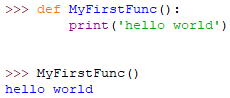

调用方法时必须保证方法名完全一致,它对大小写敏感。
有参 无返回值方法

有参 有返回值方法

方法文档描述

关键字参数

默认值参数

收集参数

注意若收集参数后,再接一个参数,则需要使用关键字参数的形式赋值,如下例子对temp参数的赋值

方法返回值细节
①无return时,方法返回值是啥?

上栗子,说明当没有return时,它仍然会返回一个NoneType类型的数据。
②方法能够返回多个值
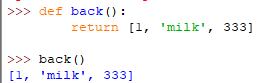

方法变量作用域(我的地盘听我的)
局部变量和全局变量


①在内部访问外部全局变量正常访问
②但在内部修改全局变量时,它会在内部创建一个同名的局部变量进行修改,而不是修改外面的全局变量,并且此后内部访问时都是一个新创的局部变量。
③在外部访问局部变量是会报错的。
④局部变量存储在栈内,全局变量存储在其他空间(堆)
global关键字
一般方式,在方法内部是无法修改全局变量的,因为它会“屏蔽”掉全局变量,而由方法内部创建了一个与全局变量同名的局部变量进行修改,并不会影响到全局变量自身。
此时需要global关键字进行确认需要修改的是全局变量而不是局部变量。

(*高级话题)内嵌方法(内嵌函数)和闭包
①内嵌方法



可发现内嵌方法能够访问其定义内嵌方法的方法变量,但仍然存在“屏蔽”修改这个变量(即使使用global来定义也不管用)【注意此时闭包已经产生】
②闭包

闭包是内嵌函数对外部变量捕获时产生的一个包体,类似C#闭包一样,上栗子funy内嵌函数捕获了funx的x局部变量,并将此函数对象返回给外部使用。
注意:C#闭包,我理解上就是一个用一个匿名对象包装捕获的变量,如果这个变量是引用类型的,那闭包的捕获变量就是指向同一个引用对象,上栗无法体现出闭包真正的效果。
闭包捕获的存放于栈的外部变量无法被修改,而容器变量则允许,例如:list(列表),如下:
利用nonlocal关键字实现闭包修改捕获的外部变量

lambda表达式
简化的匿名函数,作用是定义简单不需要def、不需要起函数名(想名字也很烦)

![]()
十一、递归

如上例子为错误的递归,它会一直不断套娃执行,直至堆栈溢出,可以按Ctrl键+C结束执行
可使用如下代码设定递归的套娃次数(层级)
import sys sys.setrecursionlimit(1000)
递归实现一个1*2*3*4*5*...的函数,传入5返回1*2*3*4*5的计算结果

关于递归更多的练习不再阐述哈,汉诺塔等经典递归问题可自行百度了解。
十二、字典
创建和访问字典
使用大括号{}定义字典,内部定义时以 key:value (键值对)形式代表字典的一个键值对元素

注意:字典并不是序列类型(数组、列表),它是映射类型。

如上例子,当字典存在相同key时,比如1和True是相同的,因为True会被翻译为1,最后一个key会覆盖掉前面的,例如:dict1[1]被dict1[True]覆盖。
字典内置方法
dict是一个工厂函数(类型),暂时可理解为一种内置方法。类似还有int(),str(),float()...均为工厂函数,每一个都是一个模块(目前还没了解模块概念)
dict(iterable)

传入的是一个元组,元组是用(),列表是用[],字典是用{}
dict(**kwargs)
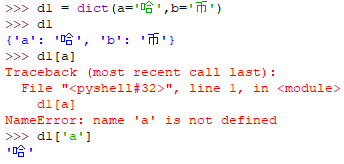
注意:a='哈'的a会变为'a'字符形式作为key

注意:以这种形式创建的字典,不允许key为字符串、数字、布尔值。
dict(mapping)
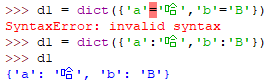
注意:{}大括号定义的字典内容是 key:value 形式,而不是key=value(lua用多了哎)
新增字典元素

fromkeys(iterable [,v])
根据iterable作为key,v作为所有key对应的值(意味着所有key的值都是v),若v不指定则为None,最终返回的是一个新的字典对象
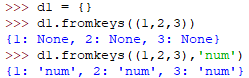
keys()
获取一个存储所有key的序列引用

values()
获取一个存储所有value的序列引用

items()
获取一个存储所有(key, value)的序列引用

get(key [, value])
一种安全的获取字典元素方法

第二个参数使用是当没有时返回的默认值,默认value是None
![]()
判断key是否存在于字典
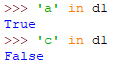
clear()
清空字典

注意:使用{}来置空是不安全的!

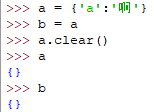
copy()
浅拷贝字典,拷贝会返回一下新的字典,如下栗子是解释拷贝和赋值的区别

pop(key)
弹出一个key的键值对

popitem()
弹出一个按优先级最高的元素?(观察发现是字典会按照某个规则随机元素,然后弹出的是第一个元素?)
![]()

setdefault(key [,value])

update(dict)
用一个dict字典去更新字典,例如 'a':'ccc'更新为 'a':'123'

十三、集合
集合里的元素是唯一的,会将重复的数据清理。
集合是无序的,无法使用索引形式获取集合元素
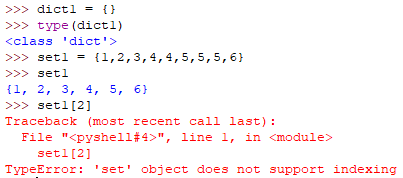
可使用{}或set()进行创建集合
![]()
可利用set进行将列表的重复元素筛选掉,但无法保证顺序还是保持原来一致,因为集合是无序的,它有自己的排序方法。
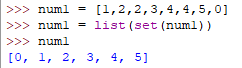

集合内置函数
add、remove

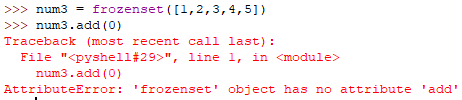
不可变集合 frozenset
冻结的 frozen, set集合 不可变集合指无法操作集合,例如增加元素。
十四、文件操作
open(...)
open(file, mode='r', buffering=-1, encoding=None,
errors=None, newline=None, closefd=True, opener=None) -> file object========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (for backwards compatibility; unneeded
for new code)
========= ===============================================================
- file:文件名,若不带路径则会从当前文件夹找到该文件名,否则根据路径查找。
- mode:文件打开模式 【实际默认mode='rt' 即r和t两个模式组合使用】
- 'r':以只读方式打开(默认)【常用】
- 'w':以写入方式打开,会覆盖已存在的文件 【常用】
- 'x':如果文件存在,使用此模式打开会引发异常
- 'a':以写入模式打开,如果文件存在,则在末尾追加写入 【常用】
- 'b':以二进制模式打开
- 't':以文本模式打开(默认)
- '+':可读写模式(可添加到其他模式中使用)
- 'U':通用换行符支持
- encoding:
read()
读取中文时可能会有报错,读取非中文文本时正常

解决读取带中文符号的UTF8格式的文本文件需要使用 encoding='utf-8'参数

或者 将中文文本文件的格式改为ANSI格式
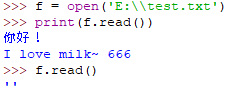
注意:read()是读取到文本尾部,之后再读取就是一个空的字符串''
读取任意个字符
![]()
tell()
返回当前游标在文件中的位置(以字节为单位)

上面的‘你好!’这是3个中文符号,每个中文占2字节,故共6字节,当前处于第六个字节后
seek(offset, from)
在文件中移动文件游标,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节

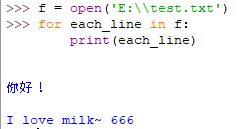
for遍历读取文件的每一行
可使用list()转换文件为列表,文件每一行会作为一个列表元素存放,再遍历读取。

推荐做法,直接遍历文件读取每一行
 .
.
write()
使用'w'模式打开文件,写入3个字符'123',返回的是3 代表写入字符个数,之后close文件,若没close则写入的内容是存储在缓存里,还未真正写入磁盘文件里的!


writelines(seq)
![]()

十五、模块
模块是一个包含所有定义的函数和变量的文件,其后缀名是py。模块可以被别的程序引入,以使用该模块中的函数等功能。
举一个引入模块并使用的小栗子

os模块(Operating System 操作系统)
getcwd()
返回当前工作目录路径
![]()
chdir(path)
切换工作目录
![]()
listdir(path='.')
列举指定path目录下的文件名

mkdir(path)
创建文件目录,注意必须要有父目录存在才允许创建,无法支持多层创建
![]()
makedirs(path)
递归创建多层文件目录,若目录已存在则抛出异常,注意:E:\\a\\b 和 E:\\a\\c并不会冲突
remove(path)
根据path删除文件
rmdir(path)
移除空目录,非空目录会引发异常

removedirs(path)
递归删除多层空目录,若遇到非空目录会抛出异常
可使用listdir找到文件名,再使用remove删除文件,从而达到清空目录
rename(old, new)
文件重命名将old换成new名
![]()
system(command)
运行系统的shell命令
![]() 打开cmd窗口
打开cmd窗口
![]() 打开系统计算器
打开系统计算器
curdir
当前目录'.' 注意:其他系统可能就不是'.'了,所以更推荐使用os.curdir作为当前目录

pardir
上一级目录'..'
sep
输出操作系统特定的路径分隔符(Win下为'\\', Linux下为'/')
linesep
当前平台使用的行终止符(Win下为'\r\n',Linux下为'\n')
name
当前使用的操作系统(包括:'posix', 'nt', 'mac', 'os2', 'ce', 'java')
os.path模块
os.path和os是两个不同的模块,但它被包含在os模块内,所以只需import os即可。
basename(path)
去掉目录路径,单独返回文件名
![]()
注意:我后面都会用path作为os.path, 因为我写了path = os.path
dirname(path)
去掉文件名,单独返回目录路径
![]()
join(path1[,path2[,...]])
将path1, path2各部分组合成一个路径名

这种带':'字符的拼接可能出现问题,需要用:\\才正常。
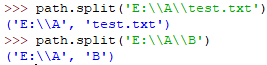
split(path)
分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或目录是否存在
splitext(path)
分离文件名与扩展名,返回(f_name,f_extension)元组
![]()
getsize(file)
返回指定文件的尺寸,单位是字节
![]()
getatime(file)
返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime(或localtime()函数换算)
![]()
getctime(file)
返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime)函数换算)
![]()
getmtime(file)
返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime)或localtime()函数换算)
![]()
![]()
![]()
以下函数返回True或False
exists(path)
判断指定路径(目录或文件)是否存在
isabs(path)
判断指定路径是否为绝对路径
isdir(path)
判断指定路径是否存在且是一个目录
isfile(path)
判断指定路径是否存在且是一个文件
islink(path)
判断指定路径是否存在且是一个符号链接
ismount(path)
判断指定路径是否存在且是一个挂载点(指盘目录根地址)

samefile(path1,paht2)
判断path1和path2两个路径是否指向同一个文件
pickle模块
主要功能是序列化和反序列化数据
序列化(写入磁盘)

反序列化(读入内存)

十六、异常处理
异常类型大全
https://www.runoob.com/python/python-exceptions.html
常见异常介绍
AssertionError
断言语句失败,即assert条件为false时引发异常
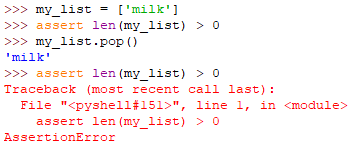
AttributeError
尝试访问未知的对象属性

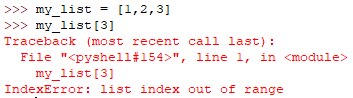
IndexError
索引超出序列范围
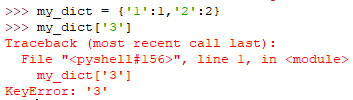
KeyError
字典中查找一个不存在的关键字,若用dict.get(...)方法查找则不会报错
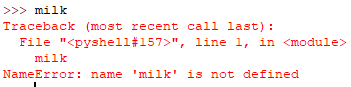
NameError
尝试访问一个不存在的变量
SyntaxError
Python语法报错
![]()
TypeError
类型报错

ZeroDivisionError
除数为零报错

OSError
操作系统错误,例如File文件操作相关报错,文件无法被找到

捕获异常
except用法①
检测到异常后,异常发生点之后的代码不会继续执行,而是直接跳转到相关except的代码块执行
try:
sum = 1 + '1'
f = open('我是文件.txt')
print(f.read())
f.close()
except OSError as reason:
print("出错了\n错误原因:" + str(reason))
except TypeError as reason:
print("类型出错了\n错误原因:" + str(reason))![]()
![]()
注意:其中一个异常先触发后,之后的异常就不会抛出。例如上栗中,只会提示类型出错了,而出错了是去掉sum=1+'1'这行代码才出现的
如下例子为若except没有处理ValueError异常,则正常报错.
try:
int('asd')
sum = 1 + '1'
f = open('我是文件.txt')
print(f.read())
f.close()
except OSError as reason:
print("文件出错了\n错误原因:" + str(reason))
except TypeError as reason:
print("类型出错了\n错误原因:" + str(reason))

except用法②
可以使用()元组形式组合捕获多个异常
try:
int('asd')
sum = 1 + '1'
f = open('我是文件.txt')
print(f.read())
f.close()
except (OSError, TypeError, ValueError):
print("出错了..")except用法③
处理任意异常(不推荐)
例如ctrl+c终止代码继续运行,这个'ctrl+c'操作也可能会引起KeyboardExceoption,从而不会正确执行终止代码。
try:
int('asd')
sum = 1 + '1'
f = open('我是文件.txt')
print(f.read())
f.close()
except:
print("出错了..")
finally
finally包含的代码块是无论如何都会执行的代码
例如: 防止文件流没有正常关闭
try:
f = open('我是文件.txt', 'w', encoding='utf-8')
print(f.write('我存在~'))
sum = 1 + '1'
except (OSError, TypeError):
print("出错了..")
finally:
f.close()
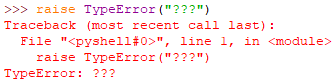
raise语句
自己引发异常
十七、关于else、with语句用法
else语句
if-else形式
num1 = input("输入一个数值:")
num1 = int(num1)
if num1 == 1:
print("是1")
else:
print("不是1")
if-elif-else形式
num1 = input("输入一个数值:")
num1 = int(num1)
if num1 == 1:
print("是1")
elif num1 == 2:
print("是2")
else:
print("非1非2")while-else形式
def showMaxFactor(num):
count = num // 2
while count > 1:
if num % count == 0:
print('%d最大的约数为%d' % (num, count))
break
count -= 1
else:
print('%d是素数!' % num)
num = int(input('输入一个数:'))
showMaxFactor(num)![]()
执行break后是不会进入到else:代码块内的,只有当while条件不成立时才会进入。
try-catch-else形式
try:
int('abc')
except ValueError as reason:
print('出错啦:' + str(reason))
else:
print("没有任何异常")
![]()
将int('abc')改为int('123')则会执行else:语句块的代码,即else是相对于except来说的,若except捕获到异常则不会执行else,否则反之。
with语句
类似C#的using()语句
try:
with open('data.txt', 'r') as f:
for each_line in f:
print(each_line)
except OSError as reason:
print('出错啦:' + str(reason))
![]()
如果使用finally形式来关闭文件流,那么此时f是不存在的,关闭一个不存在的文件流是会引发其他错误的,而使用with语句则能正常判断存在才关闭文件流。
二十、其他常用内置函数
断言 assert
assert断言操作用于检查数据是否正常,若检查条件返回false则代表异常,会抛出AssertionError异常并提示代码行报错,例如:如下的3>4条件返回false就报错了。

filter() 过滤器
filter(function or None, iterable) --> filter object
![]()
传递None时过滤掉所有非真和空的元素

传递function后会根据function过滤,如上奇数为1(真),偶数为0(假),所以把所有偶数过滤了。
![]()
lambda表达式简化
map() 映射
将序列每一个元素传入function处理后重新得到一个新的序列
![]()