零基础掌握python网络爬虫
目前,本人初学网络爬虫,记忆一些爬虫所遇到的问题和解决方法。对于一些环境的配置仅凭回忆,仅供参考。
零基础:需要有些基本的编程思想例如 ifelse 和配置环境 运行程序的能力
如果有任何错误,例如需要在何处报错安装某某模块或者配件,请提醒博主,因为博主安装过 所以没报错 就忘记提起。
环境
python3.8(语言环境) 下载与配置
python-3.8.1-amd64.exe 下载链接
若失效自行百度搜索下载即可(链接为windows 64位系统,其他系统也自行百度下载即可)
安装注意事项:
1、勾选Add Python 3.7 to PATH
把Python的安装路径添加到系统环境 变量的Path变量中,否则需要自己配置环境变量
2.选择Install Now(默认安装到C盘下)/ Customize installation(自定义安装路径)
3。自定义安装可根据需要勾选,如果不知道默认就可以。
检验安装成功;
在cmd命令行中输入python命令
如果成功进入python交互式命令行,则安装成功。安装成功的话可以看到版本信息并进入编程模式
开始中搜索IDLE(在python3.8中)
运行
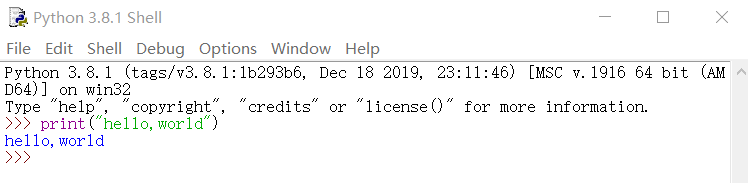
如果你输入法是在中文下输入,这时就会解读成各种快捷键,十分麻烦。
为此,我们再下载更方便的编辑器prcharm。
pycharm2019 3.3(编写器) 下载与运行
pycharm-community-2019.3.3.exe下载链接
上面为64位windows 社区版的链接 失效或需要其他版本自行搜索下载
安装注意事项:
1、在Install options中仅勾选 :
64bit launcher(创建桌面快捷方式) 和.py(py文件以后默认由pycharm打开)
2、其他一路确定,然后Do not import settings,之后选择OK,一路确定 完成安装。
创建new project 再右键项目名添加Python文件即可运行python程序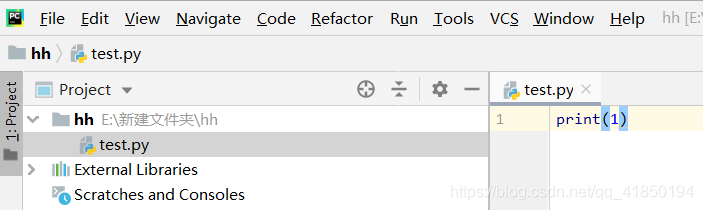
实例说明python编程语言特点
def add(a,b):
return a+b # 1.递进:按照递进 来控制范围 如下的a与b的定义必须对齐
a = "123"
b = '456' #2.单引号与双引号等价
print(add(a,b)) # 3.无分号 还是按照递进来辨别
if a == "666":
print(a)
else:
print("666") # 4.仅通过递进程序才得知 if与下面的else 是同一个判断语句
输出为:
123456
666
至此,具备基本编程能力就可以边学边写python爬虫程序。
等等,下面的错误是什么鬼?
unindent does not match any outer indentation level 又是什么鬼错误?

原因在于python对与缩进的变态严格要求
可以看第一个print前面的小符号是>:利用tab键进行的缩进
而第二个print前面符号是.....:纯粹用四个空格对齐的缩进
what the hell?而且pycharm默认是不显示空格符号和tab符号的,也就是你们要在两个空白中找不同。
所以如何显示空格符号和tab符号?
File-Settings-Editor-Apperance-show whitespaces(三个小选项默认全选)
编写第一个爬虫:下载猫咪图片
安装好以上的环境以后,我们尝试从猫咪图片中将可爱的猫咪下载到电脑中
废话不多说,复制粘贴跑一下试试
import urllib.request
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
# 获取网页内容
cat_img = response.read()
# 读取网页内容 也就是一个图片
fp = open('cat_500_600.jpg','wb')
fp.write(cat_img)
# fp是一个文件对象,open方法第一个属性是文件名称,第二个属性是write-bytes也就是写文件模式 本地不存在则创建
# 写文件 属性为刚读取的图片cat_mig
如果你环境没有问题,不报错的你就可以去python目录下找到这个图片了。
另附加获取工作目录的代码
import os
print (os.getcwd())#获得当前目录
下面来解释上面爬虫用到的模块并逐句解释上面的爬虫程序
urllib包(主要使用parse和request模块)
用来访问网页并获取内容,是刚刚设计的爬虫程序的核心
import urllib.request #引入该包的request 也就是请求(和响应)模块
parse模块
urlencode():将字典转换为url格式
request模块:打开url网页,并返回响应对象(也就是网页内容)
最主要的方法:urlopen(url,data)
打开URL网址,返回响应对象(http.client.HTTPResponse对象)
url参数可以是一个字符串url,也就是网页地址。
urlopen的第二个参数data是控制网页是获取还是提交的参数
data为None时用get获取,data赋值时为post提交。所以不赋值就是默认获取,至于何时用post提交以及两者区别,暂且不论。
也就是说request是一种请求获取网页内容的方法,参数即为网页地址,so easy
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
# 调用request模块来获取网页内容
# response为网页的响应对象,其中包含网页的所有内容。
response 响应对象包括许多种方法,其中最重要的是read()方法
使用read()函数 返回未解码的网页内容(如字节流或图片)
read()得到内容后用decode()函数使用对应的解码方式,返回相应的对象(如utf-8 返回字符串)
cat_img = response.read()
# 读取未解码的网页内容 此处就是一个图片
Request:信息更完善的请求对象,包括headers(请求头)等信息
仅仅使用 urlopen(网页),似乎有些过于局限,因为随着爬虫技术的进展,反爬虫技术也在发展。
许多网页当判断出网页请求是来自python时就会拒绝你的访问请求。如果网页不让我获取数据怎么办?
伪装成你不是python 而是真实用浏览器访问的用户。
在这里我们主要是给python的网页请求增加了许多属性,例如可以将网页请求的用户端(反爬虫用来判断是否是python请求的的属性)User-Agent
获取User-Agent:
1)随便打开网页(后期根据你想要访问的网页来选择),如百度
鼠标右键 - 检查 - Network - 从下面几个数据栏中随意点击一个 - 下拉到Request Headers - 下拉到User-Agent
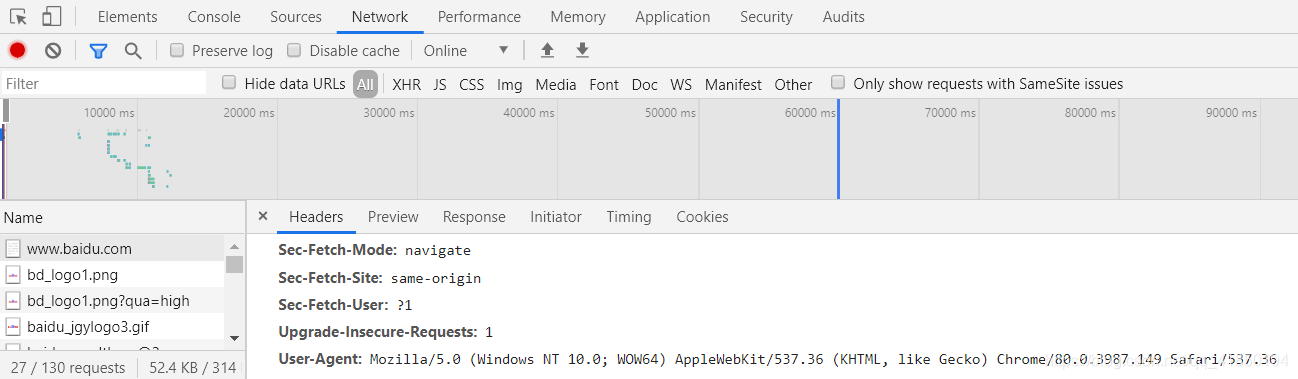
此处建议使用Chrome浏览器。
因此,request模块中又引入了Request模块,就是请求网页的信息更完善的请求对象,包括headers(请求头)等信息
我们可以给Request对象设置一些更多的信息,然后
urllib.request.urlopen(Reqeust对象)
# 属性是信息更完善的请求对象,当然其中要包括网页地址。
# 而不再只是一个网页地址
尝试一下
import urllib.request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
url = 'http://placekitten.com/g/500/600'
R1 = urllib.request.Request(url=url,headers=headers)
# R1 是Request的一个对象 其中赋值了地址和信息头
# 对于该网页来说,对python没有阻拦,所以只是示范,信息头可以不加
response = urllib.request.urlopen(R1)
cat_img = response.read()
# 读取未解码的网页内容 此处就是一个图片
fp = open('cat_500_600.jpg','wb')
fp.write(cat_img)
# fp是一个文件对象,open方法第一个属性是文件名称,第二个属性是write-bytes也就是写文件模式 本地不存在则创建
# 写文件 属性为刚读取的图片cat_mig
Request对象构造 属性如下
Request(url = url,data = data, headers = headers,method = ‘POST’)
data参数:访问网页携带的数据,暂且不论。
要求bytes(字节流)类型,如果是一个字典,先用urllib.parse.urlencode()编码。
data = urllib.parse.urlencode(字典).encode('utf-8')
data为空时,method默认为get,也就是获取。
data不为空时,method默认为pos,也就是提交。
第一次使用框架
Scrapy 1.8.0 安装与配置
暂无,建议网上搜索教程。
第一次使用框架:下载自己想要的网页数据
建立scrapy项目
cd你想要创建项目的目录,此处为桌面
C:\Users\15650>cd desktop
C:\Users\15650\Desktop>scrapy startproject hello
使用Pycharm打开项目(File-open)hello并操作,如图,
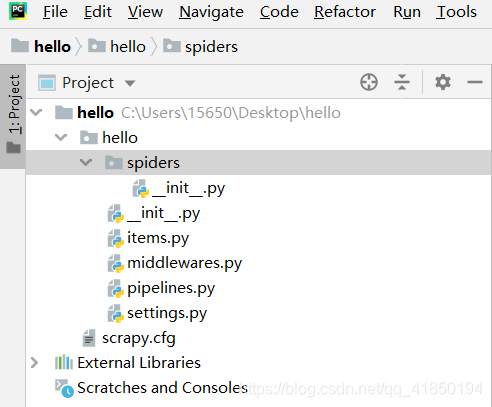
序号一:在spiders模块(spiders文件夹)中创建python文件编写爬虫程序*
import scrapy
class Number1Spider(scrapy.Spider):
name = "number1" # 必须唯一 ,可以理解为给爬虫起名字,以后直接叫名字 它就工作
allowed_domains = ['dmoztools.net'] # 设定域名 允许爬取的域名列表,不设置表示允许爬取所有
# 填写起始爬取地址 爬虫一开始工作就自动访问并返回信息
start_urls = [
"http://dmoztools.net/Computers/Programming/Languages/Python/Books/"
]
# 以上为爬虫启动后的第一步,自动访问网页然后返回response响应对象(网页信息)
# 此处为自动执行的回调函数parse,也就是处理response信息的函数,为处理数据部分
def parse(self, response):
with open("Book", 'wb') as f:
f.write(response.body) # response.body 是网页前端的所有信息
序号二:主函数(随便创建一个py文件,代执行cmd语句,运行爬虫)
from scrapy import cmdline
cmdline.execute('scrapy crawl number1'.split())
# 引号内 本来是cmd下执行的语句,此处引入cmd模块来代执行
# 意思为 执行scrapy 的爬虫 爬虫名为number1
查看项目中是否生成Book的文件,文件内容为网页全部前端信息,建议从电脑内存中用记事本方式打开
序号三:item模块,建立数据容器,筛选数据
如果我们只想保留刚才获取的网页的标题、链接和说明。
在items.py中定义一个Item容器,其中自己声明几个想要的属性,此处我们想要三个属性。
import scrapy
class HelloItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
序号四:添加item后的回调函数parse
# 此处为自动执行的回调函数parse,也就是处理response信息的函数,为处理数据部分
def parse(self, response):
# response是 htmlresponse对象
sel = scrapy.selector.Selector(response)
#sel 选择器,是一个可以被xpath查找到选择器
sites = sel.xpath('//div[@class="title-and-desc"]')
items = []
for site in sites:
item = HelloItem() # 创建一个该Scrapy项目 item容器的一个对象
item['title'] = site.xpath('a/div/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('div/text()').extract()
items.append(item) #将该item对象添加到items列表
return items
lxml与xpath:用于确定文档中某部分位置
lxml库是Python的一个解析库,支持HTML和XML的解析,支持XPath
安装,cmd下:pip install lxml
引入etree:from lxml import etree
将字符串等转换为html对象,并自动补全结点:html = etree.HTML(text)
读取文件为html对象:html = etree.parse('./test.html',etree.HTMLParser())
将html文件转为字符串并解码输出:
result = etree.tostring(html)
print(result.decode('UTF-8'))
XPath即为XML路径语言,它是一种用来确定XML/HTML文档中某部分位置的语言。
html对象就是xpath解析对象,返回一个列表
extract():
item['name'] = each.xpath("./a/text()").extract()[0]
each html文档
each.xpath("./a/text()") xpath解析返回的是一个选择器列表
extract() 转换为Unicode字符串
[0] 列表第一个位置
序号五:主函数中执行cmd语句直接保存筛选完的数据
from scrapy import cmdline
cmdline.execute('scrapy crawl number1 -o item.json'.split())
查看项目中是否生成Book的文件,文件内容为筛选完的信息,建议从pycharm直接读
