0、为什么需要二叉排序树
前面的查找我们都是静态查找,因为数据集是有序存放,查找的方法有多种,可以使用折半,插值,斐波那契等,但是因为有序,在插入和删除操作上的效率并不高。
这时我们就需要一种动态查找方法,既可以高效实现查找,又可以使得插入和删除效率不错,这时我们可以考虑二叉排序树
1、二叉排序树(Binary Sort Tree)
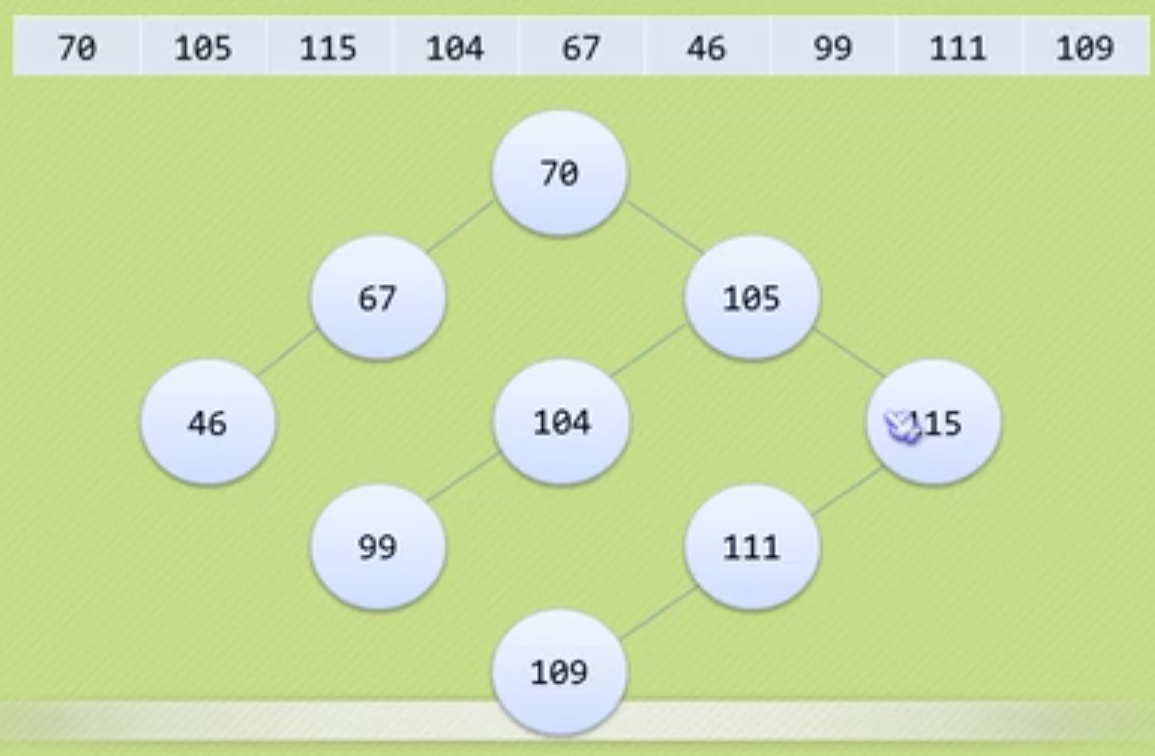
又称二叉查找树,它或者是一棵空树,或者是具有以下性质的二叉树:
1)若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值;
2)若它的右子树不为空,则右子树上所有结点的值均大于它的根结构的值;
3)它的左,右子树也分别为二叉排序树(递归)。
虽然我们得到的数据是无序的,但是我们按照二叉排序树的方式组织,中序遍历二叉树则是有序的。当然构造二叉排序树的目的更多的是未来方便查找,插入和删除关键字的速度。
1)查找:
/* BiTree T 我们要搜索的二叉树 ElemType key我们要搜索的关键字 BiTree F 记录下我们的当前搜索子树的双亲结点 BiTree* P 当我们插入之前,会先搜索是否存在数据,若存在,不插入,若不存在,我们通过这个可以获取我们要插入的位置,直接插入即可 */ Status SearchBST(BiTree T, ElemType key, BiTree F, BiTree* P) { if (!T) { *P = F; //若是未找到则返回父节点位置 return FALSE; } else { if (T->data == key) { *P = T; //若是找到则P返回该结点位置 return TRUE; } else if (T->data < key) return SearchBST(T->rchild, key, T, P); else return SearchBST(T->lchild, key, T, P); } }
2)插入
Status InsertBST(BiTree* T, int key) { BiTree P,s; if (!T) return ERROR; if (!SearchBST(*T, key, NULL, &P)) { //没有查找到有重复数据,获取到了应该插入的位置 s = (BiTree)malloc(sizeof(BiTNode)); s->data = key; s->lchild = s->rchild = NULL; if (!P) //空树 *T = s; else if (key < P->data) //插入左子树 P->lchild = s; else P->rchild = s; return OK; } else return ERROR; }
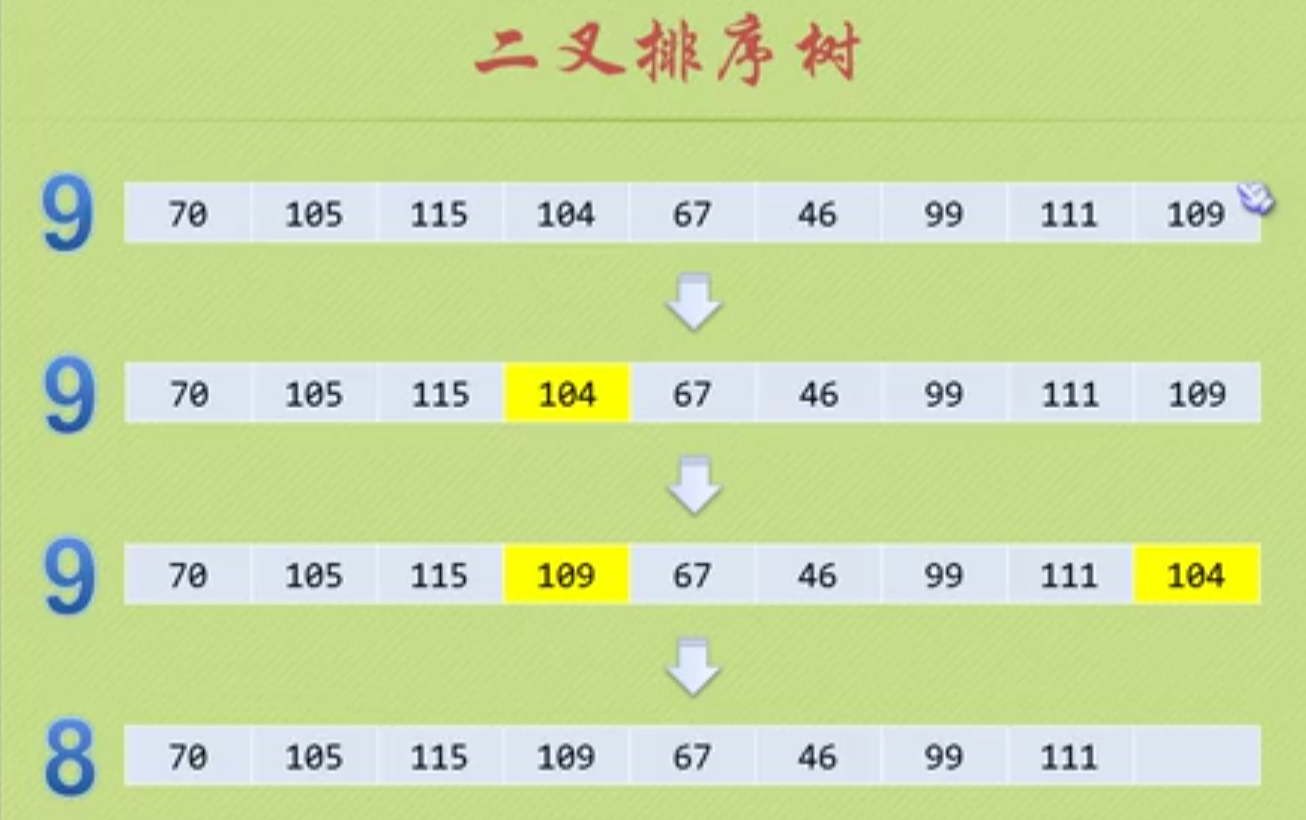
3)删除
如果是叶子结点,则直接删除;
如果结点只存在左子树或右子树,则直接补上;
如果同时存在左子树和右子树,则按照中序遍历的顺序将删除结点的前驱或者后继补上即可;
Status Delete(BiTree* T) { BiTree q,f; if (!*T) return ERROR; if (!(*T)->lchild) //若是左子树不存在,我们只需要接到右子树 { q = *T; *T = (*T)->rchild; free(q); } else if (!(*T)->rchild) //若右子树不存在,接入左子树 { q = *T; *T = (*T)->lchild; free(q); } else //两边都存在,我们可以选择将右子树最小,或者左子树最大接入,这里选择右子树最小 { f = *T; //f指向q的双亲结点 q = (*T)->rchild; while (q) { f = q; q = q->lchild; //找到右子树最小,注意其可能存在右子树,我们要进行保存,接入其父节点 } //将最小的数据更新到根节点处即可,然后记录最小点处,删除即可 (*T)->data = q->data; if (f != (*T)) f->lchild = q->rchild; else f->rchild = q->rchild; //当右子树是一个右斜树 free(q); } return TRUE; } Status DeleteBST(BiTree* T, int key) { if (!*T) return ERROR; else { if ((*T)->data == key) //找到了,开始删除 { //删除该结点,由于要分情况讨论,所以另外写一个函数 } else if ((*T)->data < key) DeleteBST(&(*T)->rchild, key); else DeleteBST(&(*T)->lchild, key); } }