Mac上tesseract-OCR的安装配置
tesseract简介
OCR(Optical Character Recognition)即光学字符识别技术,专门用于对图片文字进行识别,并获取文本。
tesseract-ocr引擎先由HP实验室研发,后来成为一个开源项目,主要由google进行改进优化。
安装步骤
安装homebrew
Homebrew是MacOS上的包管理器,类似于ubuntu中的apt-get,centos中的yum,Homebrew安装很简单
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"安装完毕后可以用brew -v测试
Homebrew 1.3.1
Homebrew/homebrew-core (git revision 0290; last commit 2017-08-23)安装tesseract
brew install --with-training-tools tesseract #同时安装附加组件,后面自定义字库会用到安装完毕后用tesseract -v测试
tesseract 3.05.01
leptonica-1.74.4
libjpeg 9b : libpng 1.6.31 : libtiff 4.0.8 : zlib 1.2.8基本用法
tesseract test.png output #识别test.png的图片,把结果放到output.txt中test.png
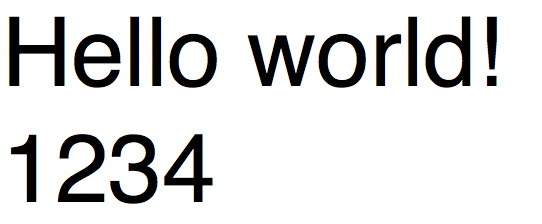
output.txt自动生成

更多可选参数的用法可以通过tesseract -h查询
python接口
python有着更加优雅的方式调用系统的tesseract工具,首先安装pytesseract模块
sudo pip install pytesseractpytesseract是对tesseract的封装,要和PIL联合使用,基本用法如下:
import pytesseract
from PIL import Image
img = Image.open('./test.png') #先创建image对象
text = pytesseract.image_to_string(img) #直接转化成string,更多参数可以查看文档
repr(text) #"u'Hello world!\\n1234'"验证码识别
网页截图保存,裁取需要识别的图片:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
import time
import sys
import pytesseract
import requests
from PIL import Image
import util.DbReboot as Reboot
from util.StringUtil import *
reload(sys)
sys.setdefaultencoding('utf8')
class MeibaoSubmit:
global windowCount
windowCount = 0
def submit(sa, ip):
# global windowCount
# windowCount = 0
# # while 1:
# windowCount += 1
# print '打开窗口:' + str(windowCount)
# chromeOptions = webdriver.ChromeOptions()
# # 设置代理
# # 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152
# # proxyStr = "--proxy-server=" + ip
# # print ('baidu prox =', proxyStr)
# # chromeOptions.add_argument(proxyStr)
# driver = webdriver.Chrome(chrome_options=chromeOptions)
# driver.implicitly_wait(30)
# try:
# driver.get("http://www.baidu.com/")
# except Exception, e:
# print '加载会话错误。。关闭窗口'
# try:
# driver.quit()
# except Exception, e:
# print '关闭窗口错误...'
# return
# print '窗口已打开'
# time.sleep(3)
# phone = MyUtil.createPhone()
# driver.execute_script(
# "document.getElementById('callbF_text').value='" + phone + "'")
# send = driver.find_element_by_id('callbF_sub')
# send.click()
# driver.get_screenshot_as_file('homepage.png')
# 打开刚刚保存的图片
img = Image.open('homepage.png')
# 设置要裁剪的区域(验证码所在的区域)
box = (1280, 500, 1500, 600)
# 截图,生成只有验证码的图片
region = img.crop(box)
# 保存到本地路径
region.save("image_code.png")
print 'cutsuccess'
# time.sleep(100)
# d = pq(driver.page_source)
# lastContent = d('.msg-sub:last .title').text();
# print '333'
# # 用Image模块打开上一步保存的验证码
# image = Image.open('code.png')
# # 识别验证码
# optCode = pytesseract.image_to_string(image)
# # 打印出验证码
# print("验证码:", optCode)
meibaosub = MeibaoSubmit()
meibaosub.submit("")
结束语
默认的tesseract-ocr工具识别能力有限,很多地方需要个性化定制(如中文),复杂验证码图片无法识别
