- 下载
需要手动安装一下Tesseract-OCR ,这是安装包下载路径:
http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
下载好了随便放到你喜欢的路径下。
-
安装
然后就是安装了:
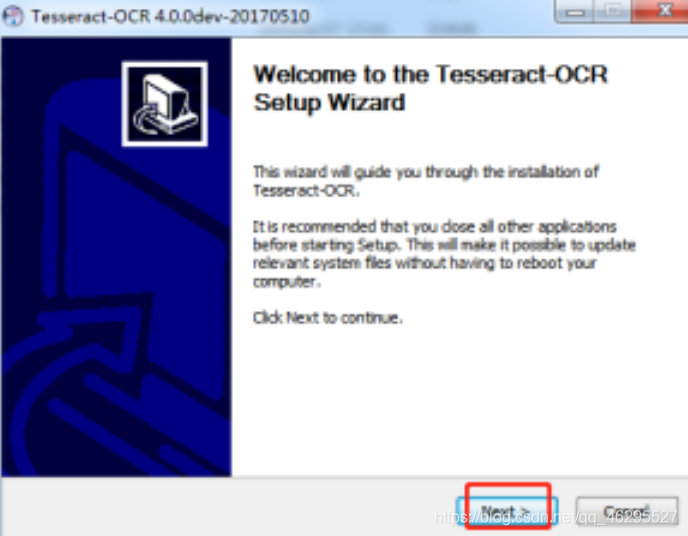
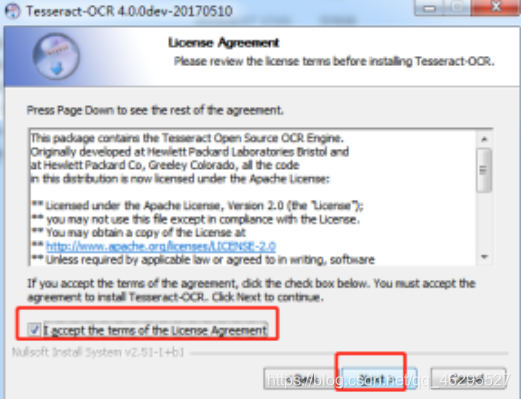
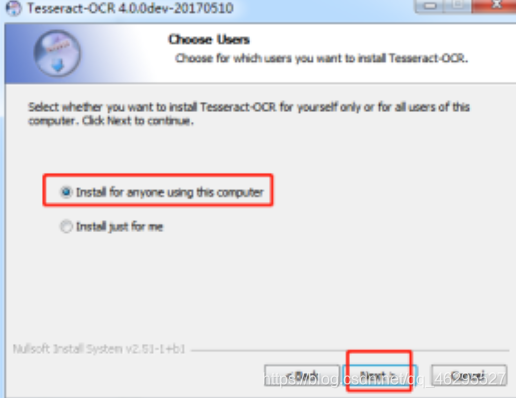 选择下载包
选择下载包
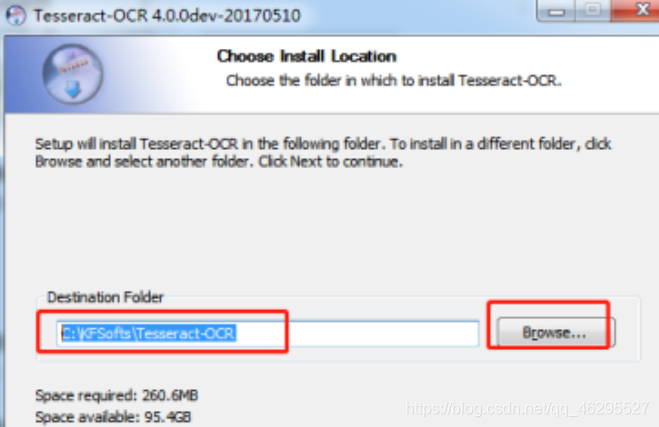
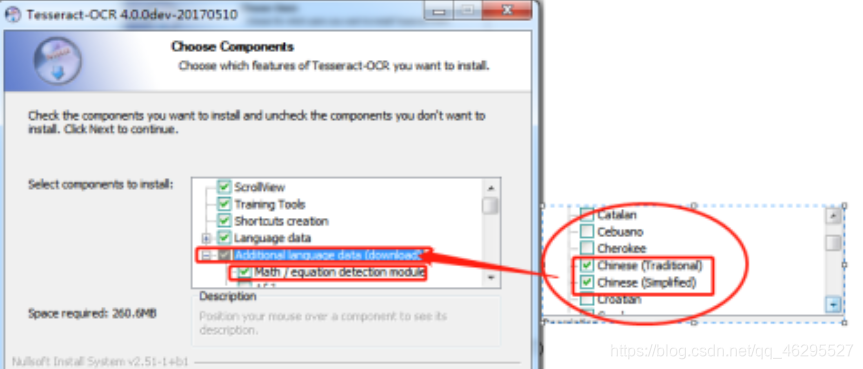 选择合适的安装路径,个人建议不要安装在C盘
选择合适的安装路径,个人建议不要安装在C盘
 点击install安装直到结束。
点击install安装直到结束。
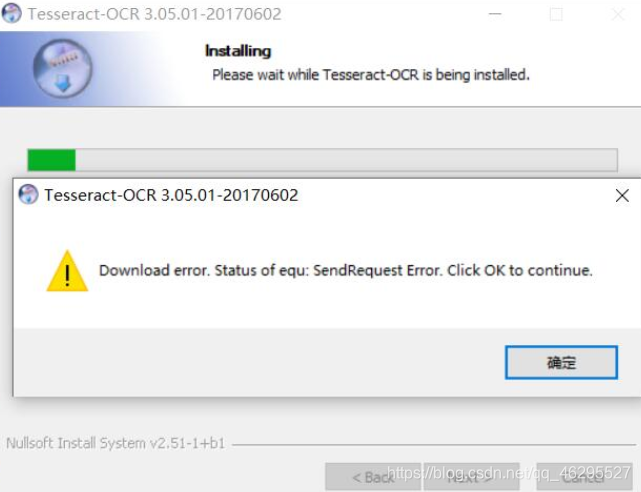
 中间可能会报这个错,就是说安装错误了,就是说前面勾选的那两个语言包下载出问题了,不过不影响我后来的使用。
中间可能会报这个错,就是说安装错误了,就是说前面勾选的那两个语言包下载出问题了,不过不影响我后来的使用。
-
环境配置
找到你的安装路径:B:\Tesseract-OCR(我的是这个)
打开高级系统设置,配置环境变量:
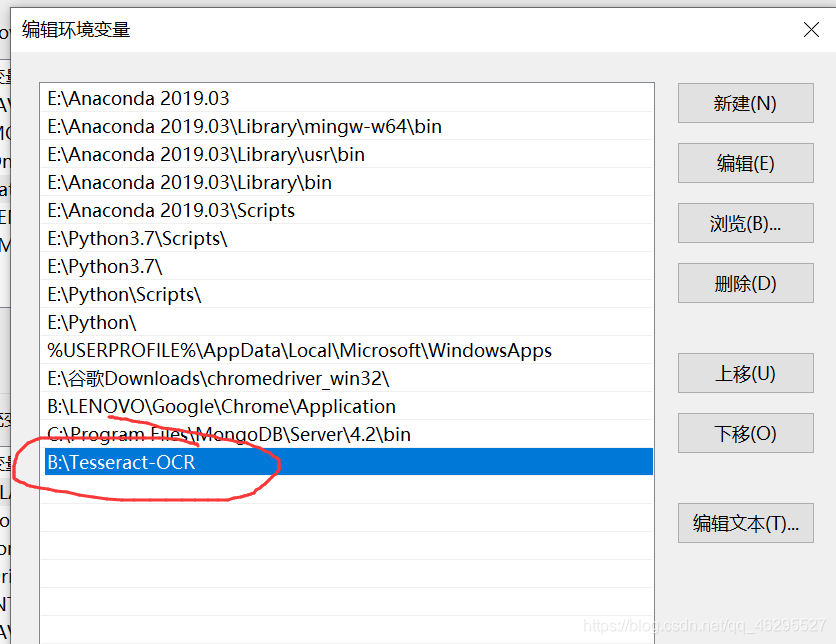
用户变量: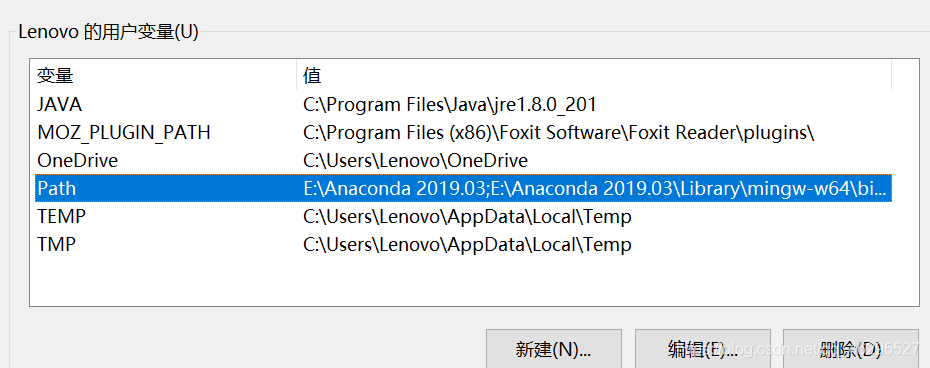 把路径加进去
把路径加进去
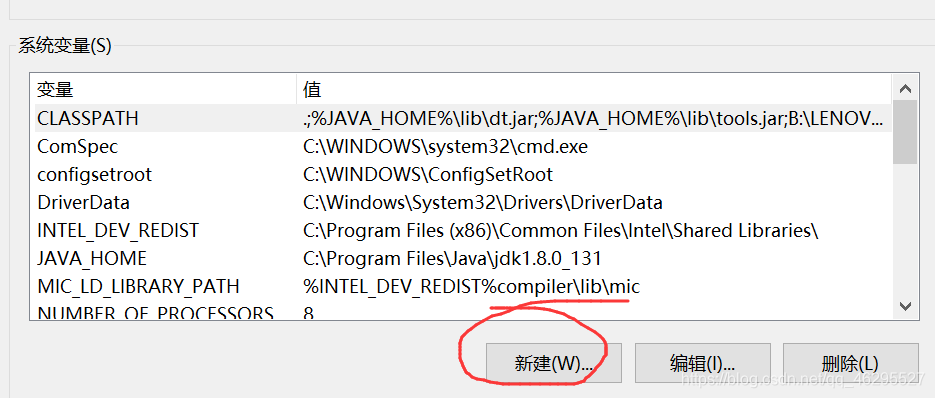
 系统变量:
系统变量:
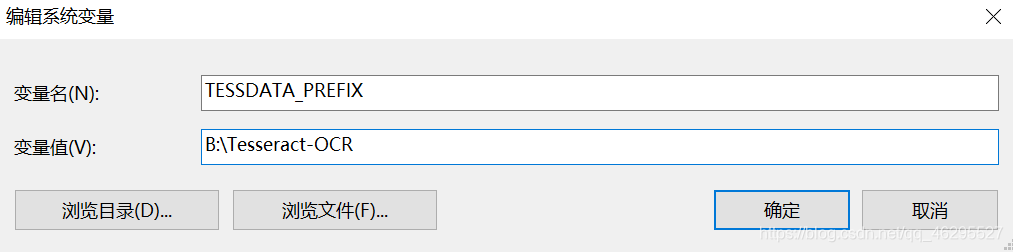
 变量名写和我一样,路径是你自己的。
变量名写和我一样,路径是你自己的。
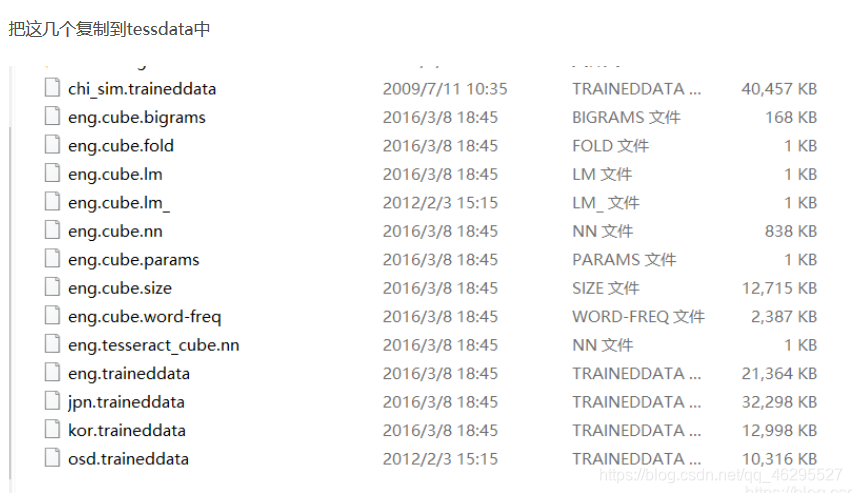
 另外,如果需要更多语言包可以在这个公众号里找:
另外,如果需要更多语言包可以在这个公众号里找:

这是看的别人的,如果需要就自行下载!不需要的话可以直接略过,这个东西安装好之后可以识别数字以及英文验证码,中文好像不可以!
-
安装python需要的包!
安装pytesseract库:
pip install pytesseract
安装PIL库:
pip install pillow
装好之后,来到下载那个包的文件夹下:
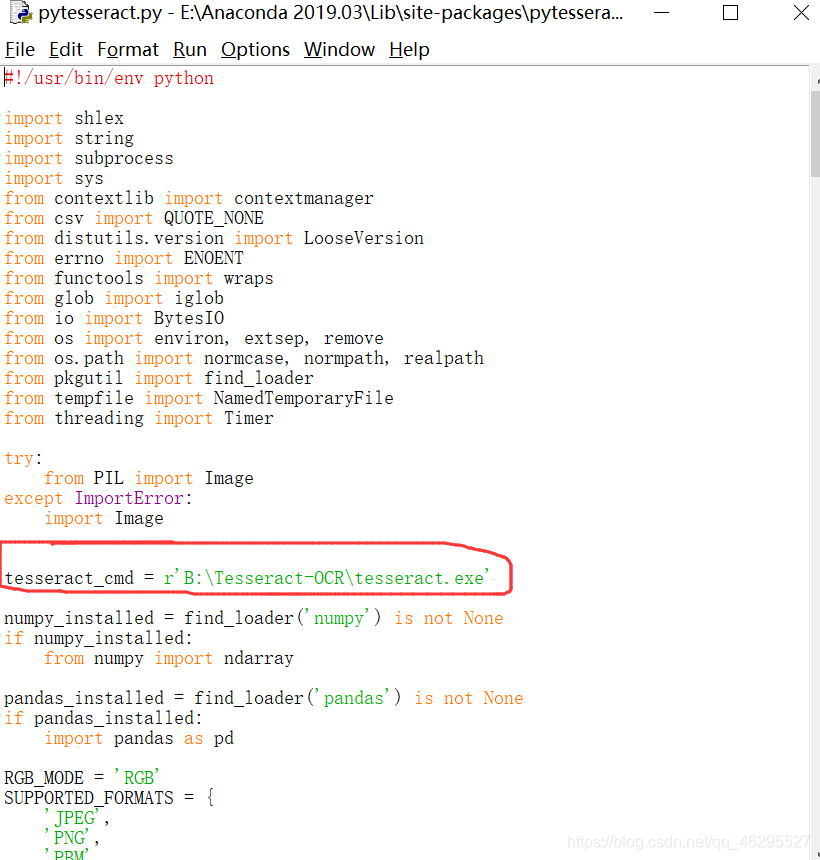
E:\Anaconda 2019.03\Lib\site-packages\pytesseract
(我的是这个)打开这个:
 这里,修改成你自己的,那个安装路径然后跟一个.exe文件,就在那个文件夹里,和我一样就可以。
这里,修改成你自己的,那个安装路径然后跟一个.exe文件,就在那个文件夹里,和我一样就可以。
- 测试:在Jupyter中输入如下代码,如能正确运行表示配置成功(注:需将’captcha.jpg’验证码图片与Jupyter文件放在同一文件夹)
import pytesseract
from PIL import Image
# 创建Image对象
image = Image.open('captcha.jpg')
# 将图片文件转化为字符串
text = pytesseract.image_to_string(image)
print(text)

运行成功即可提取出里面的验证码!!!
如果你成功了,记得给我点个赞哦!!!