快速排序(Quick Sort)是对冒泡排序的一种改进。
基本思想:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,再对两部分记录分别进行继续排序,使得整个记录有序。
首先任选一个记录(通常选第一个记录)作为枢轴(或支点)privot。
一趟快速排序的做法:
附设两个指针low和high,它们的初始值分别为low和high,设枢轴记录的关键字为privotkey,
首先从high所指的位置起向前搜索找到第一个关键字小于privotkey的记录,和枢轴记录互换;
然后从low所指的位置起向后搜索找到第一个关键字大于privotkey的记录,和枢轴记录互换;
重复这两步直至low=high为止。
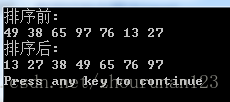
49 38 65 97 76 13 27 49
初始关键字:49 38 65 97 76 13 27 49
high 49 = 49
27 < 49 互换 27 38 65 97 76 13 49 49
low 38 < 49
65 > 49 互换 27 38 49 97 76 13 65 49
high 13 < 49 互换 27 38 13 97 76 49 65 49
low 97 > 49 互换 27 38 13 49 76 97 65 49
high 76 > 49
low = high 49 = 49 {27 38 13} 49 {76 97 65 49} 完成一趟排序
一次划分结果:{27 38 13} 49 {76 97 65 49}
两边分别进行快速排序: {13} 27 {38}
{49 65} 76 {97}
有序序列{13 27 38 49 49 65 76 97}
核心代码:
int Partition(int arr[], int low, int high){
// 选取第一个数作为基准数
int base = arr[low];
while(low < high){
//从high开始,向左遍历,直到找到小于基准数的元素,并将此数放到low位置
while(low < high && arr[high] >= base)
high --;
Swap(arr,low,high);
//从low开始,向右遍历,直到找到大于基准数的元素,并将此数放到high位置
while(low < high && arr[low] <= base)
low ++;
Swap(arr,low,high);
}
return low;
}
void QuickSort(int arr[], int low, int high){
int base;
if(low < high){
//将数组一分为二
base = Partition(arr, low, high);
//对低子表递归排序
QuickSort(arr, low, base-1);
//对高子表递归排序
QuickSort(arr, base+1,high);
}
}
完整代码:
#include<stdio.h>
#include<stdlib.h>
void Swap(int arr[] ,int low ,int high)
{
int tmp;
tmp=arr[low];
arr[low]=arr[high];
arr[high]=tmp;
}
int Partition(int arr[], int low, int high){
// 选取第一个数作为基准数
int base = arr[low];
while(low < high){
//从high开始,向左遍历,直到找到小于基准数的元素,并将此数放到low位置
while(low < high && arr[high] >= base)
high --;
Swap(arr,low,high);
//从low开始,向右遍历,直到找到大于基准数的元素,并将此数放到high位置
while(low < high && arr[low] <= base)
low ++;
Swap(arr,low,high);
}
return low;
}
void QuickSort(int arr[], int low, int high){
int base;
if(low < high){
//将数组一分为二
base = Partition(arr, low, high);
//对低子表递归排序
QuickSort(arr, low, base-1);
//对高子表递归排序
QuickSort(arr, base+1,high);
}
}
int main(){
int arr[] = {49,38,65,97,76,13,27};
int length=0;
length=sizeof(arr)/sizeof(arr[0]);
int i,j;
printf("排序前:\n");
for(i = 0; i < length; i++){
printf("%d ",arr[i]);
}
printf("\n排序后:\n");
QuickSort(arr, 0, length-1);
for(j = 0; j < length; j++){
printf("%d ",arr[j]);
}
printf("\n");
return 0;
}
算法性能

时间复杂度
当数据有序时,以第一个关键字为基准分为两个子序列,前一个子序列为空,此时执行效率最差。
而当数据随机分布时,以第一个关键字为基准分为两个子序列,两个子序列的元素个数接近相等,此时执行效率最好。
所以,数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差。
空间复杂度
快速排序在每次分割的过程中,需要 1 个空间存储基准值。而快速排序的大概需要 NlogN次的分割处理,所以占用空间也是 NlogN 个。
算法稳定性
不稳定。在快速排序中,相等元素可能会因为分区而交换顺序,所以它是不稳定的算法。