Tensorflow2.0之LeNet-5实战
LeNet-5 神经网络讲解
1990 年代,Yann LeCun 等人提出了用于手写数字和机器打印字符图片识别的神经网络,被命名为LeNet-5 [4]。LeNet-5 的提出,使得卷积神经网络在当时能够成功被商用,广泛应用在邮政编码、支票号码识别等任务中。下图 10.30 是LeNet-5 的网络结构图,它接受32 × 32大小的数字、字符图片,经过第一个卷积层得到[b,28,28,6] 形状的张量,经过一个向下采样层,张量尺寸缩小到 ,[b,14,14,6]经过第二个卷积层,得到 形状的张量,同样经过下采样层,张量尺寸缩小到[b,5,5,6] ,在进入全连接层之前,先将张量打成 的张量,送入输出节点数分别为120、84 的2 个全连接层,得到 8 的张量,最后通过Gaussian connections 层。
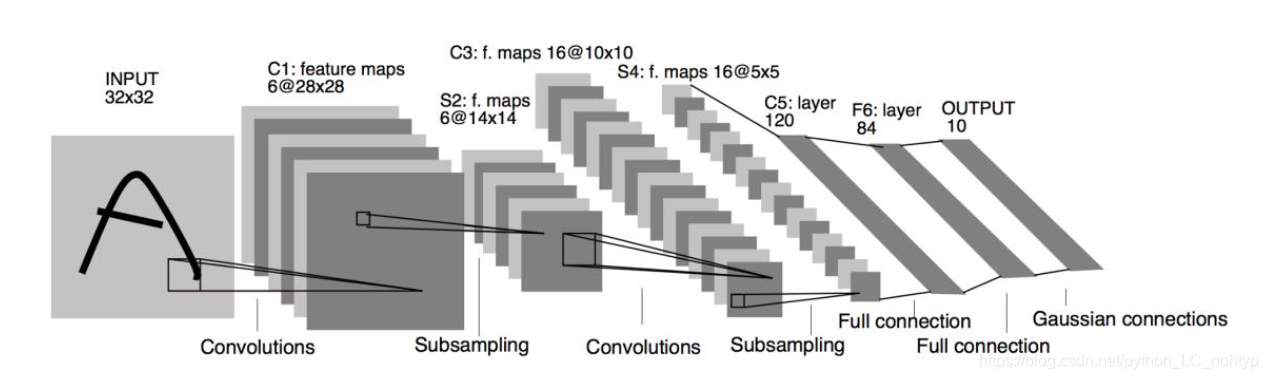
现在看来,LeNet-5 网络层数较少(2 个卷积层和2 个全连接层),参数量较少,计算代价较低,尤其在现代GPU 的加持下,数分钟即可训练好LeNet-5 网络。
我们在LeNet-的基础上进行少许的调整,使他更容易在现代深度学习的框架上实现。首先我们将输入X形状由32X32调整为28X28,然后将2个下采样层实现为最大池化层,最后利用全连接层替换掉Gaussian connections层。下文统一称修改的网络也为LeNet-5 网络。

我们基于MNIST手写数字图片数据集训练LeNet-5网络,并测试其最终准确度。
代码部分(完整代码在最后):
导入相关的包
import tensorboard
import tensorflow as tf
from tensorflow.keras import Sequential, layers, losses, optimizers, datasets
import datetime
加载训练集并进行预处理:
在进行训练之前先加载训练姐并进行预处理:
# 加载手写数据集文件
def preprocess(x, y):
"""
预处理函数
"""
# [b, 28, 28], [b]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
(x, y), (x_test, y_test) = datasets.mnist.load_data() # 加载手写数据集数据
batchsz = 1000
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 转化为Dataset对象
train_db = train_db.shuffle(100000) # 随机打散
train_db = train_db.batch(batchsz) # 批训练
train_db = train_db.map(preprocess) # 数据预处理
train_db = train_db.repeat(30) # 复制30份数据
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(1000).batch(batchsz).map(preprocess)
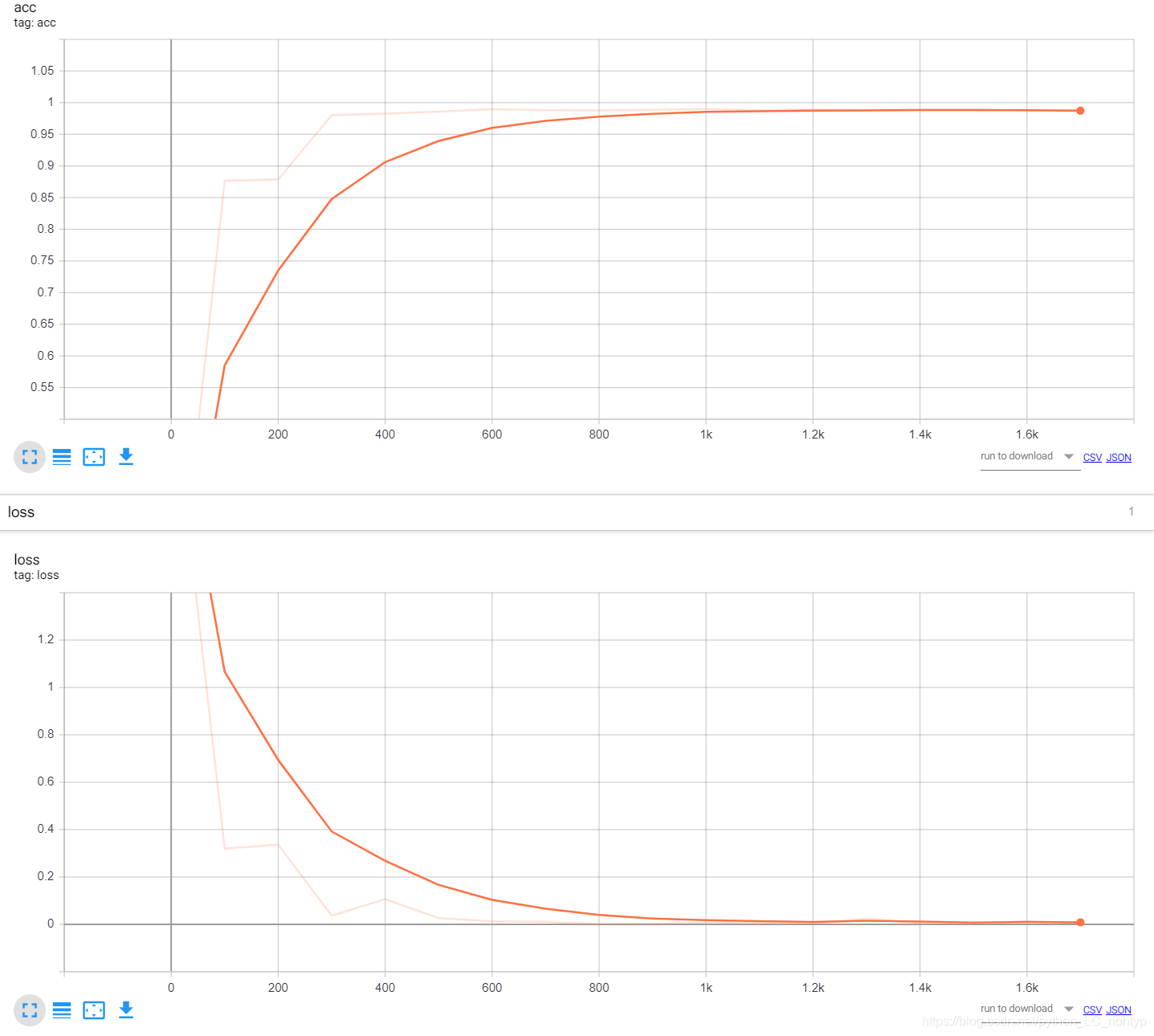
这样训练集和测试集就准备完毕了,这里我批训练的数量设置的是1000是因为我的电脑还可以,如果配置不行的可以调小批训练的个数,至于为什么是1000,类似于这种超参数的调节都是根据结果一步步调节的。我的这个网络从一开始的80%的准确度,不停的调节批训练的个数和学习率这两个超参数最后网络的准确度达到了98.61%
创建tensorboard环境:
current_time = datetime.datetime.now().strftime(('%Y%m%d-%H%M%S'))
log_dir = 'logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir)
当然了在运行代码的时候不要忘了,打开代码所在位置的终端并启动tensorboard哦
创建网络层
网络层在前面已经介绍过了,这里直接搭建就ok了
# 通过Sequnentia容器创建LeNet-5
network = Sequential([
layers.Conv2D(6, kernel_size=3, strides=1), # 第一个卷积核,6个3X3的卷积核,
layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积核,16个3X3的卷积核,
layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Flatten(), # 打平层,方便全连接层处理
layers.Dense(120, activation='relu'), # 全连接层,120个结点
layers.Dense(84, activation='relu'), # 全连接层,84个结点
layers.Dense(10, activation='relu') # 全连接层,10个结点
])
# build 一次网络模型,给输入X的形状
network.build(input_shape=(1000, 28, 28, 1))
# 统计网络信息
print(network.summary)
模型训练和保存:
optimizer = tf.keras.optimizers.RMSprop(0.01)
# 训练20个epoch
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# 插入通道维度 =》[b,28,28,1]
x = tf.expand_dims(x, axis=3)
# 前向计算,获取10类别的概率分布 [b,784]=>[b,10]
out = network(x)
# 计算交叉熵损失函数,标量
loss = criteon(y, out)
# 自动计算梯度
grads = tape.gradient(loss, network.trainable_variables)
# 自动更新参数
optimizer.apply_gradients(zip(grads, network.trainable_variables))
if step % 100 == 0:
with summary_writer.as_default():
tf.summary.scalar('loss', float(loss), step=step)
# 计算准确度
if step % 100 == 0:
correct, total = 0, 0
for x, y in test_db:
# 插入通道维度 =>[b,28,28,1]
x = tf.expand_dims(x, axis=3)
# 前向计算,获得10类别的预测分布 [b,784] => [b,10]
out = network(x)
# 真实的流程时先经过softmax,再argmax
# 但是由于softmax不改变元素的大小相对关系,故省去
pred = tf.argmax(out, axis=-1)
y = tf.cast(y, tf.int64)
y = tf.argmax(y, axis=-1)
# 统计预测正确的数量
correct += float(tf.reduce_sum(tf.cast(tf.equal(pred, y), tf.float32)))
# 统计预测样本的总数量
total += x.shape[0]
with summary_writer.as_default():
tf.summary.scalar('acc', float(correct / total), step=step)
tf.saved_model.save(network, 'model-savedmodel')
tensorboard的图像
完整的代码:
"""
LetNet-5 实战
"""
import tensorboard
import tensorflow as tf
from tensorflow.keras import Sequential, layers, losses, optimizers, datasets
import datetime
devices = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(devices[0], True)
# 加载手写数据集文件
def preprocess(x, y):
"""
预处理函数
"""
# [b, 28, 28], [b]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
current_time = datetime.datetime.now().strftime(('%Y%m%d-%H%M%S'))
log_dir = 'logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir)
(x, y), (x_test, y_test) = datasets.mnist.load_data() # 加载手写数据集数据
batchsz = 1000
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 转化为Dataset对象
train_db = train_db.shuffle(100000) # 随机打散
train_db = train_db.batch(batchsz) # 批训练
train_db = train_db.map(preprocess) # 数据预处理
train_db = train_db.repeat(30) # 复制30份数据
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(1000).batch(batchsz).map(preprocess)
# 通过Sequnentia容器创建LeNet-5
network = Sequential([
layers.Conv2D(6, kernel_size=3, strides=1), # 第一个卷积核,6个3X3的卷积核,
layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积核,16个3X3的卷积核,
layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Flatten(), # 打平层,方便全连接层处理
layers.Dense(120, activation='relu'), # 全连接层,120个结点
layers.Dense(84, activation='relu'), # 全连接层,84个结点
layers.Dense(10, activation='relu') # 全连接层,10个结点
])
# build 一次网络模型,给输入X的形状
network.build(input_shape=(1000, 28, 28, 1))
# 统计网络信息
print(network.summary)
# 创建损失函数的类,在实际计算时直接调用类实例
criteon = losses.CategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.RMSprop(0.01)
# 训练20个epoch
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# 插入通道维度 =》[b,28,28,1]
x = tf.expand_dims(x, axis=3)
# 前向计算,获取10类别的概率分布 [b,784]=>[b,10]
out = network(x)
# 计算交叉熵损失函数,标量
loss = criteon(y, out)
# 自动计算梯度
grads = tape.gradient(loss, network.trainable_variables)
# 自动更新参数
optimizer.apply_gradients(zip(grads, network.trainable_variables))
if step % 100 == 0:
with summary_writer.as_default():
tf.summary.scalar('loss', float(loss), step=step)
# 计算准确度
if step % 100 == 0:
correct, total = 0, 0
for x, y in test_db:
# 插入通道维度 =>[b,28,28,1]
x = tf.expand_dims(x, axis=3)
# 前向计算,获得10类别的预测分布 [b,784] => [b,10]
out = network(x)
# 真实的流程时先经过softmax,再argmax
# 但是由于softmax不改变元素的大小相对关系,故省去
pred = tf.argmax(out, axis=-1)
y = tf.cast(y, tf.int64)
y = tf.argmax(y, axis=-1)
# 统计预测正确的数量
correct += float(tf.reduce_sum(tf.cast(tf.equal(pred, y), tf.float32)))
# 统计预测样本的总数量
total += x.shape[0]
with summary_writer.as_default():
tf.summary.scalar('acc', float(correct / total), step=step)
tf.saved_model.save(network, 'model-savedmodel')
