
目录
1 项目介绍——什么是车道偏离预警?
在法国图卢兹曾经举行过一场智能车比赛,参赛者需要编写程序让自制的小车巡线跑圈。通常我们会想到识别车道线,然后用逻辑控制小车保持在线上,这种方法在一般速度时可行,但当车辆加速后,如果仅在应该大弯处转弯,则会因为车速过快而偏离车道。
能否用提前转弯的方式保证车辆不 “出轨” 呢?答案是肯定的,那么如何控制小车转弯的时机呢? ———— 机器学习!
2 项目实施框架
在这个项目中,我们需要经过三个阶段,分别是 视频处理、数据处理和模型训练。我们将收集小车转弯和执行时拍摄的图片,并根据这些图片数据训练一个线性回归模型,并在完整的小车跑圈中预测小车的转弯时机。

3 项目实施具体步骤
3.1 获取视频流
为了模拟跑车的场景,本项目事先提供了 2 段智能车跑圈的截取视频,它们分别是小车在高速走直线时的视频片段和小车在高速提前转弯时的视频片段。
在第一阶段中,将完成对这两段视频的预处理,将视频中的黄色车道线作为关注点。
将使用 OpenCV 作为视频读取工具,OpenCV 是一个基于 BSD 许可(开源)发行的跨平台计算机视觉库,它轻量级而且高效,附带的算子可以帮我们解决图像预处理的问题。
使用 OpenCV 的 VideoCapture 函数读取视频流
straightLaneVideo = cv.VideoCapture('data/StraightLane.mp4')
turnRightVideo = cv.VideoCapture('data/TurnRightLane.mp4')使用 IPython 的插件 ipywidgets 显示视频测试图片以及视频流,定义视频流显示函数 imshow
maxWidth = 640
maxHeight = 480
windowsObj = {}
def imshow(name, img):
if(not name in windowsObj):
windowsObj[name] = widgets.Image(format='jpg', height=maxHeight, width=maxWidth)
display(windowsObj[name])
windowsObj[name].value = cv.imencode('.jpg', img)[1].tobytes()定义名为 currentTime 的变量,并初始化为当前时间
currentTime = time.time()while 1:
if(time.time() - currentTime > 0.033):
currentTime = time.time()
ret, frame = straightLaneVideo.read()
if(ret):
imshow('straightLaneFrame1', frame)
rgbImg = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
imshow('straightLaneFrame2', rgbImg)
else:
print('视频已播放完毕')
Break

3.2 颜色识别
根据车道线的特点,且基于本项目的关注点,先进行一次黄色识别。
但黄色在 RGB 三通道中没有稳定的规律,因此不能直接做颜色筛选。
所以选择在 HSV 三通道的图像进行颜色筛选。在 HSV 三通道的图像中,H 表示色调,即主色调,S 表示饱和度,即颜色深浅,V 表示对比度,即亮度。
不同的颜色的 HSV 区间如下表:

代码设计思路:
①使用 OpenCV 的 cvtColor 函数进行图像通道转换,该函数可以将 RGB 三通道图像通过内置公式近乎无损转换为 HSV 三通道。
②根据黄色的 HSV 空间表,定义高地阈值。
③在每次获取完图像帧之后调用 colorDetector 函数执行颜色筛选,并使用 imshow 函数查看筛选结果。
def colorDetector(image, lowerThreshold, upperThreshold):
hsvImg = cv.cvtColor(image, cv.COLOR_RGB2HSV)
maskImg = cv.inRange(hsvImg, lowerThreshold, upperThreshold)
return maskImg
while 1:
if(time.time() - currentTime > 0.033):
# 保留前面的程序
if(ret):
# 保留前面的程序
lowerThreshold = np.array([11, 80, 90])
upperThreshold = np.array([35, 255, 255])
maskImg = colorDetector(rgbImg, lowerThreshold, upperThreshold)
imshow('straightLaneMask', maskImg)
else:
# 保留后面的程序
3.3 图像去噪
噪声在后续做直线拟合的轮廓识别时可以被忽视,但为了提高识别的速度,需要提前将其清除。
在图像处理中有两个最基本的图像形态学变换:腐蚀和膨胀。这两种方法的原理就是对原始图像进行卷积操作,顾名思义,腐蚀即为求局部最小值,卷积核区域的图像值过少时,输出的区域中的像素点的值即为 0。可以用这种方式去除白色细小点形式的噪声。
腐蚀操作是针对整个图像来说的,因此目标区域中的像素同样会被经过腐蚀,这可能导致后续无法识别轮廓,因此需要在图像腐蚀之后做一次膨胀操作。图像膨胀和腐蚀相反,即为求局部最大值,将最大值赋予指定像素。
通常我们会采用,先腐蚀后膨胀的操作,这种方法被称为开操作。
进行图像形态学变换需要额外传入一个参数作为卷积核,在 return maskImg 之前定义卷积核大小,本项目所采用的图像大小为 640*480,通常卷积核大小为 5*5,并用 1 进行填充。
在解决了白色小点的噪声之后,紧接着又出现了新的问题。视频中车道线外的地毯颜色同样也趋近黄色,在筛选时并未被筛选出来,同样也无法用开操作去除。
通过观察视频可以发现,视频的下半部分中不会出现地毯,因此如果只对视频的下半部分进行黄色识别,即可保证识别出的蒙版图仅包含车道区域。
def colorDetector(image, lowerThreshold, upperThreshold):
hsvImg = cv.cvtColor(image, cv.COLOR_RGB2HSV)
maskImg = cv.inRange(hsvImg, lowerThreshold, upperThreshold)
kernel = np.ones((5,5), np.uint8)
maskImg = cv.morphologyEx(maskImg, cv.MORPH_OPEN, kernel
roiPoints = np.array([[0, maxHeight],
[maxWidth, maxHeight],
[maxWidth, maxHeight / 2],
[0, maxHeight / 2]], np.int32)
roiMask = np.zeros((maxHeight, maxWidth), np.uint8)
cv.fillPoly(roiMask, [roiPoints], (255))
maskImg = cv.bitwise_and(maskImg, roiMask)
maskImg = cv.medianBlur(maskImg,5)
return maskImg
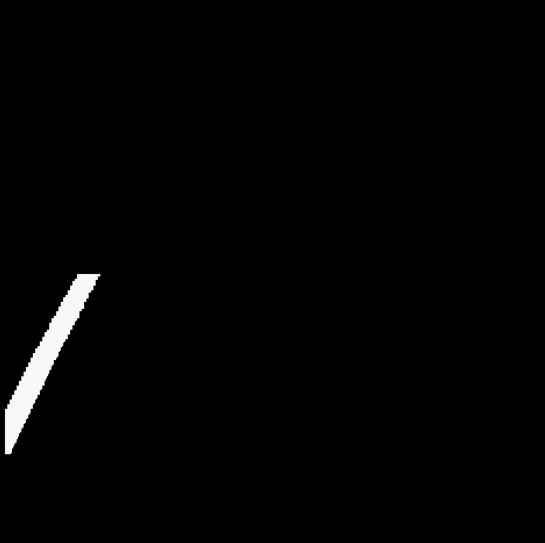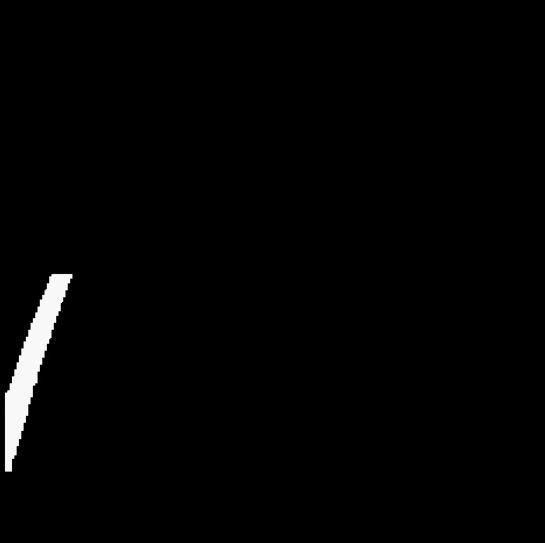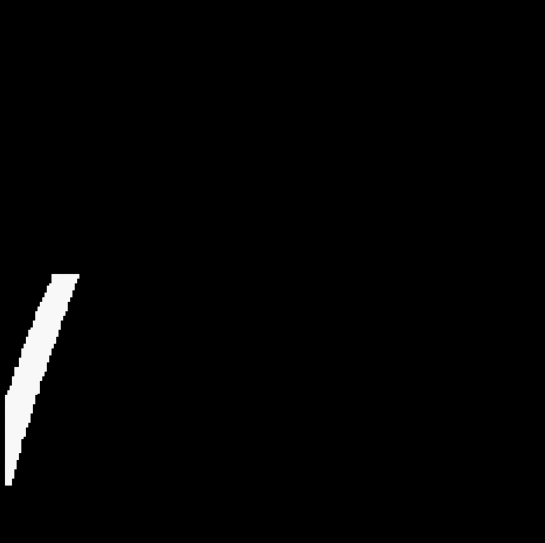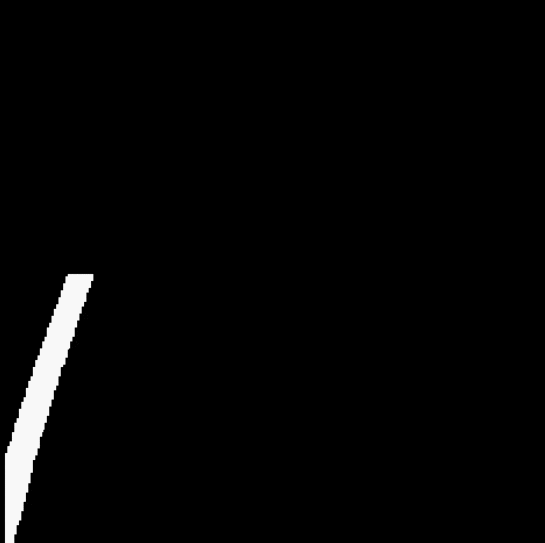
3.4 拟合直线
颜色筛选的返回图像并不能直接作为模型的输入,一个点和斜率可以确定一条直线,我们希望能将黄色车道线的斜率和与屏幕左端的交点横坐标作为输入值(即 W 和 b 值)。因此在第二阶段,将完成数据集预处理的过程。
代码设计思路:
①使用 OpenCV 的 Canny 函数检测车道线的轮廓,该函数会检测图像中灰度值变化较大的点,并将这些点连接起来从而形成轮廓。
②我们将车道轮廓图的几何学中心作为车道线的中心点。
③使用 OpenCV 的 moments 函数计算多边形的特征矩,得出中心点坐标和最终拟合出的直线 W 和 b 值。
def fitLine(maskImg):
lineEdgesImg = cv.Canny(maskImg, 20, 60)
lineContours, _ = cv.findContours(lineEdgesImg, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
W = 0
b = -999
if(len(lineContours) > 0):
mID = 0
mA = 0
for i in range(len(lineContours)):
tmp = cv.contourArea(lineContours[i])
if(tmp > mA):
mA = tmp
mID = i
M = cv.moments(lineContours[mID])
if(M['m00']!=0):
cX = int(M['m10']/M['m00'])
cY = int(M['m01']/M['m00'])
rect = cv.minAreaRect(lineContours[mID])
box = cv.boxPoints(rect)
def calDist(p1, p2):
return math.sqrt((p1[0]-p2[0])*(p1[0]-p2[0])+(p1[1]-p2[1])*(p1[1]-p2[1]))
if(calDist(box[0],box[1]) > calDist(box[1], box[2]) and box[1][0] - box[0][0] != 0):
W = (box[1][1] - box[0][1]) / (box[1][0] - box[0][0])
elif(box[2][0] - box[1][0] != 0):
W = (box[2][1] - box[1][1]) / (box[2][0] - box[1][0])
b = cY - W * cX
return W,b
3.5 数据标注
收集获取的车道线表达式并对其进行数据标注,在 while 1 代码块前新建代码块,定义数据集。
每组数据中都包含车道线的斜率和偏重值,每组数据对应一个标签,用于表示当前处于直行状态还是转弯。
while 1:
if(time.time() - currentTime > 0.033):
currentTime = time.time()
ret, frame = turnRightVideo.read()
if(ret):
imshow('turnRightLaneFrame', frame)
rgbImg = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
lowerThreshold = np.array([11, 80, 90])
upperThreshold = np.array([35, 255, 255])
maskImg = colorDetector(rgbImg, lowerThreshold, upperThreshold)
imshow('turnRightLaneMask', maskImg)
W,b = fitLine(maskImg)
if(W != 0 and b != -999):
y1 = 0
x1 = int((y1 - b) / W)
y2 = maxHeight
x2 = int((y2 - b) / W)
cv.line(frame, (x1,y1), (x2,y2), (255), 3)
imshow('turnRightLane', frame)
cnt2 += 1
data = np.concatenate((data, np.array([[W, b]])), axis=0)
else:
print('视频已播放完毕')
break
if(cnt2 > 0):
label = np.full(cnt2, 1)
labels = np.append(labels, label)
turnRightVideo.release()3.6 训练模型
模型由 2 层全连接层组成:
第一层有16个神经元,会把输入的数据变成16个权重值;
最后一层有1个神经元,会把前面16个神经元进行一次计算,算出一个准确率(概率值,一般取0.5作为阈值用于分类)来判断是转弯还是直行。

代码设计思路:
数据集中按照先直道后弯道的规律分布,这会对训练造成误导性,因此对数据集和对应的标签进行打乱处理。先生成乱序的 1~2334 的数字数组,然后根据这个随机数组打乱数据集和对应的标签。
接下来按照 80% 训练集、20% 测试集的做法,将数据集分为训练集和测试集。
permutation = np.random.permutation(data.shape[0])
data = data[permutation, :]
labels = labels[permutation]
vfoldSize = int(data.shape[0]/100*20)
xTrain = data[vfoldSize:data.shape[0], :]
yTrain = labels[vfoldSize:labels.shape[0]]
xTest = data[0:vfoldSize, :]
yTest = labels[0:vfoldSize]

定义一个空的模型作为模型框架。
model = keras.Sequential()调用 TensorFlow Keras 的 add 函数往模型中添加层,该函数中所使用的 Dense 函数通常需要传入 2 个值,分别是神经元数量 unit 和激活函数 activation。
通常在使用 Dense Layer 时,在最后一次分类前会使用 relu 作为激活函数,在最后一次分类时使用 softmax 或 sigmoid 作为激活函数。激活函数即为上层节点的值输入到下层节点的输入之前需要执行的操作,如果激活函数未指定则会直接往下传。对于二分类的模型,一般会采用 sigmoid。
model.add(keras.layers.Dense(16, input_shape =(2,), activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))在模型建立完毕后,为了训练这个模型,我们需要定义优化器。优化器即为在每一步训练之后,更新模型中每个神经元所包含的权重值,使下一次数据进来之后分类更加准确。
adam = keras.optimizers.Adam()使用 Sequential Model 的 compile 函数编译模型,该函数需要传入 3 个参数,分别是损失函数 loss,优化器 optimizer 和评估函数 metrics。
损失函数即对比真实标签和在每次预测时输出结果的方法,损失函数输出的值越小,模型的训练效果越好。在本项目中,我们采用 binary_crossentropy 作为损失函数。该损失函数可在二分类问题时使用通过计算二分类的交叉熵获取损失值。
评估函数即评价模型运行结果与实际结果的方法,评估方法并不会影响模型的训练,仅作为评估模型时用。在本项目中,我们采用 accuracy 作为评估函数,即直接判断识别准确率。
model.compile(loss='binary_crossentropy',
optimizer=adam,
metrics=['accuracy'])在模型训练时容易发生过拟合现象,即模型训练导致模型损失值不降反升,但何时发生过拟合在模型训练之前是未知的,因此为了更好的监控模型的训练过程,我们使用 Tensorboard 作为模型训练监视器。
使用 TensorFlow Keras 的 TensorBoard 函数定义 Tensorboard 变量,该函数需要传入 3 个值,分别是中间结果存储路径 path,是否可视化图像 write_graph,和是否计算模型层的激活和权重直方图 histogram_freq。
tensorBoard = keras.callbacks.TensorBoard(log_dir='kerasLog',
write_images=1,
histogram_freq=1) 使用 Sequential Model 的 fit 函数执行模型训练,该函数需要传入 7 个值,分别是模型训练集中的特征数据 xTrain,训练集中的标签值 yTrain,每个 batch 大小 batch_size,测试集 validation_data,训练的纪元数 epochs,回调函数 callbacks 和训练过程输出模式 verbose。



3.7 使用推理模型
本项目所构建的模型是一个二分类模型,模型的输出 shape 为 (None, 1),其数值的实际意义是一个概率,如果概率值小于 0.5 则结论为分类 0(直行),如果概率值大于等于 0.5 则结论为分类 1(紧急转弯)。
import tensorflow as tf
import tensorflow.keras as keras
import numpy as np
import math
import cv2 as cv
import time
import ipywidgets as widgets
from IPython.display import display
读取 data 目录下的 lane.mp4 文件。
laneVideo = cv.VideoCapture('data/lane.mp4')
复制通用程序和处理函数到本使用推理模型文件中。
currentTime = time.time()
maxWidth = 640
maxHeight = 480
windowsObj = {}
def imshow(name, img):
if(not name in windowsObj):
windowsObj[name] = widgets.Image(format='jpg', height=maxHeight, width=maxWidth)
display(windowsObj[name])
windowsObj[name].value = cv.imencode('.jpg', img)[1].tobytes()
def colorDetector(image, lowerThreshold, upperThreshold):
hsvImg = cv.cvtColor(image, cv.COLOR_RGB2HSV)
maskImg = cv.inRange(hsvImg, lowerThreshold, upperThreshold)
kernel = np.ones((5,5), np.uint8)
maskImg = cv.morphologyEx(maskImg, cv.MORPH_OPEN, kernel)
roiPoints = np.array([[0, maxHeight],
[maxWidth, maxHeight],
[maxWidth, maxHeight / 2],
[0, maxHeight / 2]], np.int32)
roiMask = np.zeros((maxHeight, maxWidth), np.uint8)
cv.fillPoly(roiMask, [roiPoints], (255))
maskImg = cv.bitwise_and(maskImg, roiMask)
return maskImg
def fitLine(maskImg):
lineEdgesImg = cv.Canny(maskImg, 20, 60)
lineContours, _ = cv.findContours(lineEdgesImg, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
W = 0
b = -999
if(len(lineContours) > 0):
mID = 0
mA = 0
for i in range(len(lineContours)):
tmp = cv.contourArea(lineContours[i])
if(tmp > mA):
mA = tmp
mID = i
M = cv.moments(lineContours[mID])
if(M['m00']!=0):
cX = int(M['m10']/M['m00'])
cY = int(M['m01']/M['m00'])
rect = cv.minAreaRect(lineContours[mID])
box = cv.boxPoints(rect)
def calDist(p1, p2):
return math.sqrt((p1[0]-p2[0])*(p1[0]-p2[0])+(p1[1]-p2[1])*(p1[1]-p2[1]))
if(calDist(box[0],box[1]) > calDist(box[1], box[2]) and box[1][0] - box[0][0] != 0):
W = (box[1][1] - box[0][1]) / (box[1][0] - box[0][0])
elif(box[2][0] - box[1][0] != 0):
W = (box[2][1] - box[1][1]) / (box[2][0] - box[1][0])
b = cY - W * cX
return W,b
使用 TensorFlow Keras 的 load_model 函数导入上一步中训练完毕的模型,该函数需要传入本地模型的路径 path 函数返回 Sequential Model 类型的模型变量 model。
model = keras.models.load_model('model.h5')
获取视频流并进行车道线识别,计算出拟合直线的表达式。
while 1:
if(time.time() - currentTime > 0.033):
currentTime = time.time()
ret, frame = laneVideo.read()
if(ret):
imshow('laneFrame', frame)
rgbImg = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
lowerThreshold = np.array([11, 80, 90])
upperThreshold = np.array([35, 255, 255])
maskImg = colorDetector(rgbImg, lowerThreshold, upperThreshold)
imshow('laneMask', maskImg)
W,b = fitLine(maskImg)
if(W != 0 and b != -999):
根据模型的定义,数据输入的 shape 为 [batch, 2],用 Numpy 定义预测用数据。其中 batch 为每次预测时数据集中的数据组数量。
while 1:
if(time.time() - currentTime > 0.033):
# 保留前面的程序
if(ret):
# 保留前面的程序
if(W != 0 and b != -999):
data = np.array([W, b])
通常在预测是每次预测都只预测一组数据,因此可以直接用 Numpy 的 expand_dims 函数扩充 shape。该函数需要传入 2 个参数,分别是带扩充的 Numpy 数组 data 和扩充的维度 axis。本 Codelab 中需要扩充第一个维度,因此 axis 值为 0。
while 1:
if(time.time() - currentTime > 0.033):
# 保留前面的程序
if(ret):
# 保留前面的程序
if(W != 0 and b != -999):
# 保留前面的程序
data = np.expand_dims(data, axis = 0)
调用 Sequential Model 的 predict 函数执行推理,该函数需要传入符合模型输入的数据 data,必须与模型训练时的输入 shape 相同。
while 1:
if(time.time() - currentTime > 0.033):
# 保留前面的程序
if(ret):
# 保留前面的程序
if(W != 0 and b != -999):
# 保留前面的程序
result = model.predict(data)
本项目所构建的模型是一个二分类模型,模型的输出 shape 为 (None, 1),其数值的实际意义是一个概率,如果概率值小于 0.5 则结论为分类 0(直行),如果概率值大于等于 0.5 则结论为分类 1(紧急转弯)。
使用 OpenCV 的 putText 函数绘制识别结果,该函数需要传入 8 个参数,分别是待绘制的图像 frame,绘制的文本 text,在图上绘制的坐标 point,绘制的字体 font,绘制字的大小 size,绘制字的颜色 color,绘制字的线条宽度 thickness 和字的线型 lineType。
while 1:
if(time.time() - currentTime > 0.033):
# 保留前面的程序
if(ret):
# 保留前面的程序
pX = int(maxWidth/2 + 10)
pY = int(maxHeight/2 + 10)
if(W != 0 and b != -999):
# 保留前面的程序
pX = int(maxWidth/2 + 10)
pY = int(maxHeight/2 + 10)
if(result[0] < 0.5):
cv.putText(frame, 'Straight',(pX,pY), cv.FONT_HERSHEY_SIMPLEX, 1, (255,0,0), 4, cv.LINE_AA)
else:
cv.putText(frame, 'TurnRight',(pX,pY), cv.FONT_HERSHEY_SIMPLEX, 1, (255,0,0), 4, cv.LINE_AA)
imshow('resultImg', frame)
else:
print('视频已播放完毕')
break
执行上述程序,即可在输出的图像中查看识别结果,识别结果用蓝色字体表示。

欢迎留言,一起学习交流~
感谢阅读