这里介绍原版的LeNet-5,在《Gradient-Based Learning Applied to Document Recognition》中描述的LeNet-5。
LeNet-5用于识别手写字符图像。手写字符图像很大,有几百个像素。如果标准的全连接神经网络的第一层有几百个隐藏单元,那么第一层的权重就有成千上万个。这么多参数就需要更大的训练集,同时增加了神经网络的复杂度,就可能增大训练误差和测试误差之间的差距。而且,全连接架构会忽略图像中的拓扑结构,而图像中位置相关性特征是判断图中数字的重要依据。
卷积神经网络非常适合用于图像识别。图像的局部失真和位移会导致输入的数据会发生明显的变化,对标准的全连接神经网络有很大的影响。卷积神经网络的卷积操作会提取图像中的基础特征,比如边缘、角和端点等,这些基础特征在图片局部失真或位移后是相对不变的,因此卷积神经网络对相似的图片的预测结果不会有很大的变化。一旦基础特征被提取出来,特征的绝对位置信息就不那么重要了,甚至是有害的,重要的是这些基础特征之间的相对位置。例如,在手写数字识别的某个图像,我们知道在图像的左上部分有一个水平线的端点,右上部分有一个角,下部分有垂线端点,我们可以判断这张图片的数字是7。为了减低卷积得到的特征图的特征的绝对位置信息的影响,最简单的做法是缩小特征图。文中称这一步是次采样层,现在一般叫做池化层。
LeNet-5的架构如下图所示
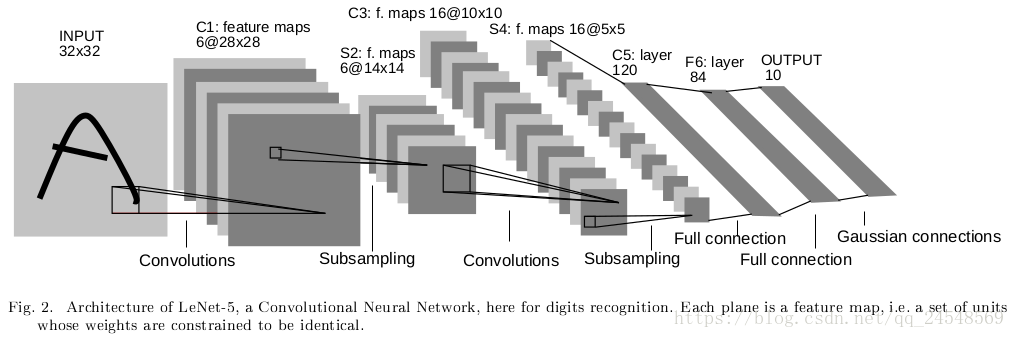
LeNet-5输入 的灰度图像。输入的像素要进行归一化处理。
网络第一层的卷积层 有6个特征图,即使用6个过滤器,每个过滤器大小为 ,步长为1。卷积后特征图大小为 。 包含156个训练参数和122304个连接。
网络第二层的池化层 有6个特征图,每个特征图大小为 。这里使用 的过滤器,步长为2。文中池化层也有参数。首先每个单元计算四个输入的平均值,将其乘以可训练的权重,加上可训练的偏差,并通过sigmoid函数传递结果。 有12个训练参数和5880个连接。
网络第三层的卷积层
有16个特征图,每个过滤器大小为
,步长为1。下表显示了
每个C3特征图连接的S2特征图集。
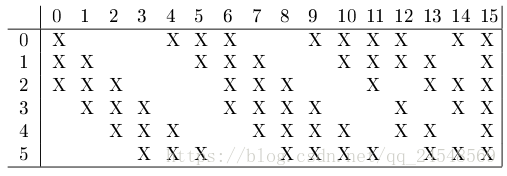
为什么不把
的所有特征图连接到
的每个特征图呢?因为,第一,非全连接结构在合理的范围内保持连接数。第二,这样打破网络的对称性。强迫不同的特征图提取不同的特征,因为它们有不同的输入。
的前6个特征图使用
中连续的3个特征图作为输入。接着的6个特征图使用
中连续的4个特征图作为输入。接着的3个特征图使用
中4个其中有些特征图连续的特征图作为输入。最后一个特征图使用
中所有特征图作为输入。
有1516个训练参数和151600个连接。
网络第四层的池化层 有16个特征图,每个特征图大小为 。这层的操作和 一样。 有32个训练参数和2000个连接。
网络第五层的卷积层 有120个特征图,过滤器大小为 ,所以特征图大小为 。 标记为卷积层,而不是全连接层,是因为如果输入图像的大小更大,特征图的大小就不是 了。 有3000个训练参数和48120个连接。
网络第六层的全连接层
,包含84个单元,有10164个训练参数。在这一层使用的激活函数是缩放双曲正切函数:
其中A是振幅,S控制斜率,z是输入与权重相乘加上偏差的值。文中A取值为1.7159。
最后的输出层由欧几里德径向基函数(Euclidean Radial Basis Function, RBF)单元组成。RBF单元的输出
是