写在前面
网上已经有很多文章对BERT的原理讲得很清楚了,今天我将以实战的方式(假装大家都懂原理≧◔◡◔≦)一步步带大家操作最近比较流行的BERT模型。源代码是pytorch版本。由于篇幅比较长我将分几个部分讲解。第一部分是数据的预处理。这一部分比较简单,但也很重要!
数据的预处理
对文本处理大致分为六个步骤,如图:
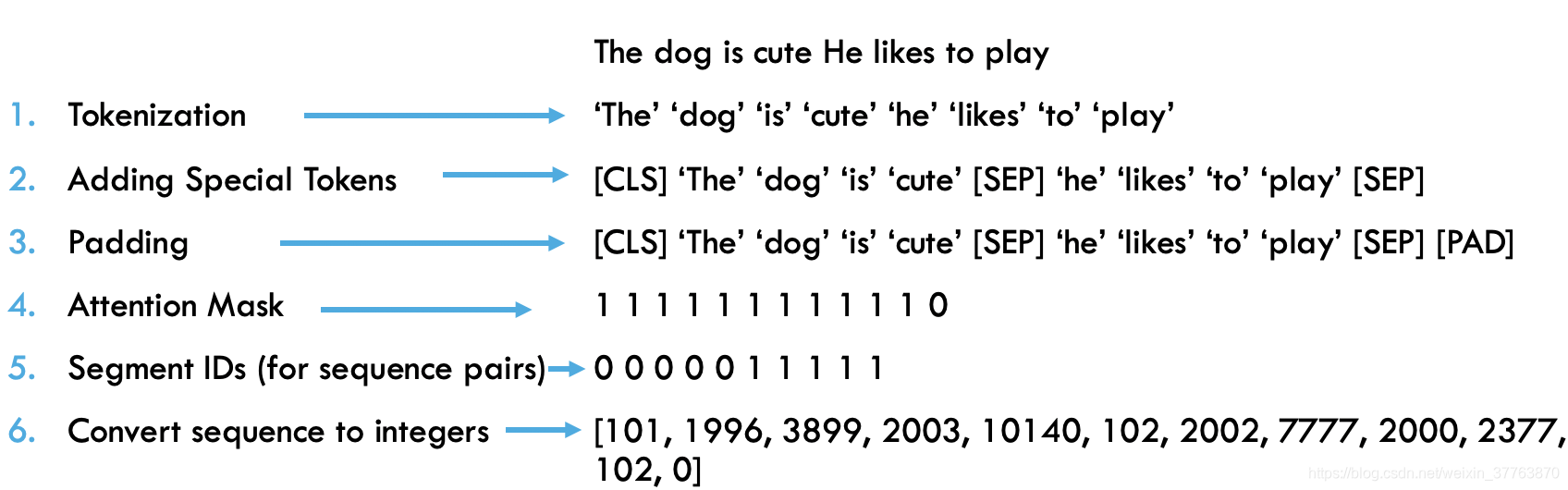
【注】本实验平台为Colab
预处理前需要导入的包:
!pip install transformers #注:此为使用Colab安装方法
import torch
from transformers import BertModel, BertTokenizer
预训练模型为bert-base-uncased,下载模型和分类器
bert_model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
【注】第一部分主要教大家如何对一个句子进行切分和转化为词向量。后面章节会用for循环直接对数据进行批量处理
Tokenization——把句子拆分成若干单词
sentence = 'hehidden likes to play'
#step1:Tokenize
tokens = tokenizer.tokenize(sentence)
print(tokens)
#效果如下,tokenize切分规则源码中有详细讲解

首尾分别添加[CLS]、[SEP]
tokens = ['[CLS]'] + tokens + ['[SEP]']
print(tokens)
#效果如下

用[PAD]填充句子(这里我设置句子长度为20)
padded_tokens = tokens + ['[PAD]' for _ in range(20 - len(tokens))]
print(padded_tokens)
#效果如下

注意力mask编码(即有单词的为1,用[PAD]的为0)
attn_mask = [1 if token != '[PAD]' else 0 for token in padded_tokens]
print(attn_mask)
#效果如下

分段segment编码(用去区分不同的句子,我们这里只有一个句子,故全设为0)
seg_ids = [0 for _ in range(len(padded_tokens))]
print(seg_ids)
#效果如下

把token转化为id
token_ids = tokenizer.convert_tokens_to_ids(padded_tokens)
print(token_ids)
#效果如下

把三部分编码转化为 tensors形式
token_ids = torch.tensor(token_ids).unsqueeze(0)
atten_mask = torch.tensor(attn_mask).unsqueeze(0)
seg_ids = torch.tensor(seg_ids).unsqueeze(0)
print(token_ids)
#效果如下,仅打印token_ids

把toke_ids、attn_mask、seg_ids喂入模型中,模型返回每个单词的向量表示hidden_reps,和第一个toekn([CLS])的向量表示。
hidden_reps, cls_head = bert_model(token_ids, attention_mask = attn_mask,\
token_type_ids = seg_ids)
print(hidden_reps)
print(cls_head)
#效果如下,每个token有768维

至此,数据的预处理部分已完毕,下面给出完整代码。
"""
Author : Mr.Luoj
Date : 2020.02.23
Blog : https://blog.csdn.net/weixin_37763870
"""
import torch
import numpy as np
import pandas as pd
from transformers import BertModel, BertTokenizer, BertForSequenceClassification
bert_model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
sentence = 'hehidden likes to play'
tokens = tokenizer.tokenize(sentence)
tokens = ['[CLS]'] + tokens + ['[SEP]']
padded_tokens = tokens + ['[PAD]' for _ in range(20 - len(tokens))]
attn_mask = [1 if token != '[PAD]' else 0 for token in padded_tokens]
seg_ids = [0 for _ in range(len(padded_tokens))] #Optional!
token_ids = tokenizer.convert_tokens_to_ids(padded_tokens)
token_ids = torch.tensor(token_ids).unsqueeze(0)
attn_mask = torch.tensor(attn_mask).unsqueeze(0)
seg_ids = torch.tensor(seg_ids).unsqueeze(0)
hidden_reps, cls_head = bert_model(token_ids, attention_mask = attn_mask,\
token_type_ids = seg_ids)
结语:
看完小伙伴们或多或少是否有点收获呢,如果您赞可的话,请给博主一个大大的赞,接下来我将讲解数据的加载、模型的建立等,敬请期待!!
参考资料:huggingface-bert
