Natural Language Processing(NLP)包括自然语言理解和自然语言生成,自然语言理解的应用包括语义分析、机器客服、语音识别、机器翻译等。
transformer这一深度网络架构在NLP领域占有举足轻重的地位,BERT是基于transformer的自然语言模型,相比于同样基于transformer的GTP3自然语言模型,transformer最早于2017由谷歌研究团队论文《Attention is all You Need》中提出,这带来了NLP领域重大进步。BERT有很多变种架构,RoBERTa, ALBERT, SpanBERT, DistilBERT, SesameBERT, SemBERT, SciBERT, BioBERT, MobileBERT, TinyBERT and CamemBERT,这些都基于
谷歌在github上开源了BERTgithub开源工程。它们的核心结构也都是attention,见相关小节。
transformer (BERT)在NLP上的表现
本博文所有源码下载链接,以下分析均基于BERT模型。
NLP任务之 判决语句正面还是负面
这可以用在任何作品、商品等,比如根据新上映影评决定排片率、根据书籍评价判决其在同类图书中质量、再比如根据电商商品好评情况增加商品曝光率等。这使用BERT分析该语句输入正面还是负面的。
#Copy right [email protected]. All rights reserved.
from transformers import pipeline
import textwrap
wrapper = textwrap.TextWrapper(width=80, break_long_words=False, break_on_hyphens=False)
#Classifying whole sentences
sentence = 'Both of these choices are good if you’re just starting to work with deep learning frameworks. Mathematicians and experienced researchers will find PyTorch more to their liking. Keras is better suited for developers who want a plug-and-play framework that lets them build, train, and evaluate their models quickly. Keras also offers more deployment options and easier model export.'
classifier = pipeline('text-classification', model='distilbert-base-uncased-finetuned-sst-2-english')
c = classifier(sentence)
print('\nSentence:')
print(wrapper.fill(sentence))
print(f"\nThis sentence is classified with a {
c[0]['label']} sentiment")
对于上述sentence的分类输出是:
This sentence is classified with a POSITIVE sentiment
句子中单词分类
其将句子中的单词或者复合词按照组织、人名和地名分类,ORG是组织organization的缩写。
sentence = "Both platforms enjoy sufficient levels of popularity that they offer plenty of learning resources. Keras has excellent access to reusable code and tutorials, while PyTorch has outstanding community support and active development."
ner = pipeline('token-classification', model='dbmdz/bert-large-cased-finetuned-conll03-english', grouped_entities=True)
ners = ner(sentence)
print('\nSentence:')
print(wrapper.fill(sentence))
print('\n')
for n in ners:
print(f"{
n['word']} -> {
n['entity_group']}")
其输出如下:
Keras -> ORG
PyTorch -> ORG
问答
这一应用在谷歌搜索引擎中,亚运会将在杭州举行,亚运会的宗旨可以用谷歌搜索,
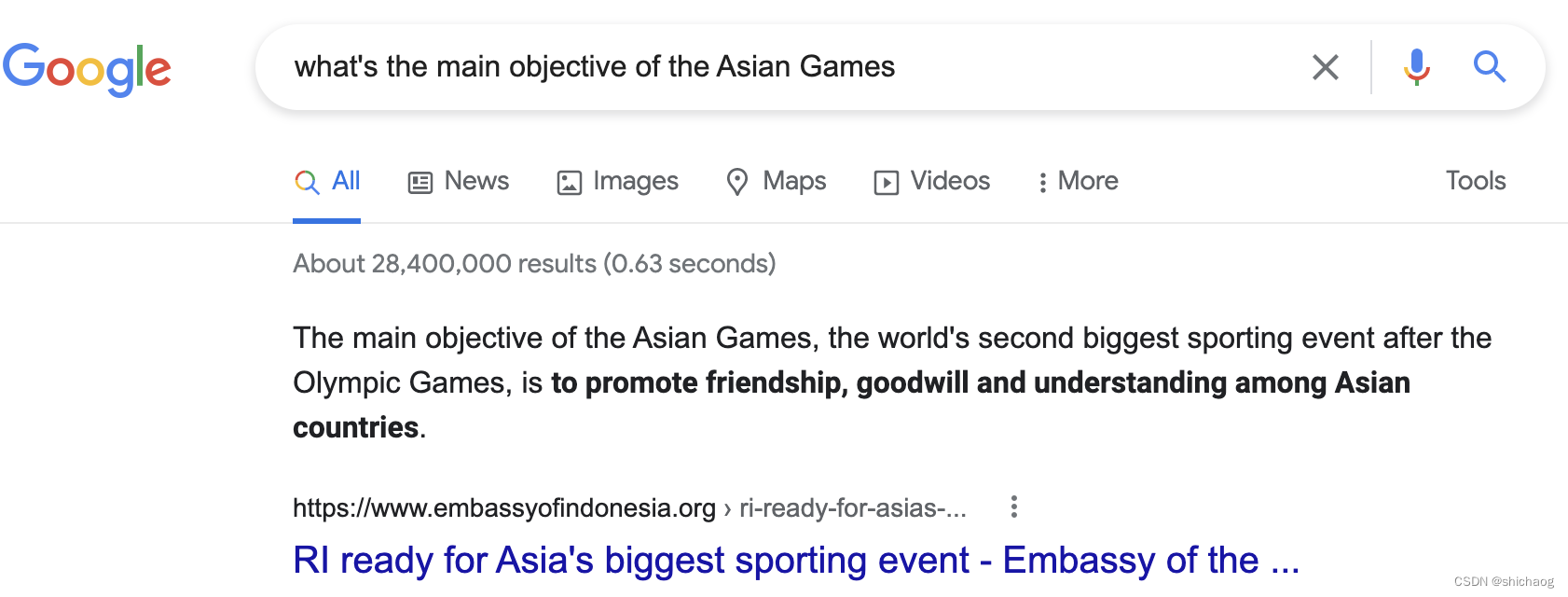
可以看到,其给出了文档链接、文档片段,并将最核心的答案高亮显示在了搜索页面上,搜索的答案非常准确、产品展示的也非常人性化。
在这里示例原文发布时间使用release这个单词,而为了验证模型的可靠性,问句中使用了announce这个单词,用以验证问答的鲁棒性,实际在运行的时候不论是relased还是announced,运行的结果都是2015这一正确值。
#question Answering
context = '''
TensorFlow is a free and open-source software library for machine learning and artificial intelligence. It can be used across a range of tasks but has a particular focus on training and inference of deep neural networks.
TensorFlow was developed by the Google Brain team for internal Google use in research and production. The initial version was released under the Apache License 2.0 in 2015. Google released the updated version of TensorFlow, named TensorFlow 2.0, in September 2019.
TensorFlow can be used in a wide variety of programming languages, most notably Python, as well as Javascript, C++, and Java. This flexibility lends itself to a range of applications in many different sectors. '''
question = 'When was TensorFlow initial announced ?'
print('Text:')
print(wrapper.fill(context))
print('\nQuestion:')
print(question)
qa = pipeline('question-answering', model='distilbert-base-cased-distilled-squad')
print('\nQuestion:')
print(question + '\n')
print('Answer:')
a = qa(context=context, question=question)
print(a['answer'])
其输出是:
Text:
TensorFlow is a free and open-source software library for machine learning and
artificial intelligence. It can be used across a range of tasks but has a
particular focus on training and inference of deep neural networks. TensorFlow
was developed by the Google Brain team for internal Google use in research and
production. The initial version was released under the Apache License 2.0 in
2015. Google released the updated version of TensorFlow, named TensorFlow 2.0,
in September 2019. TensorFlow can be used in a wide variety of programming
languages, most notably Python, as well as Javascript, C++, and Java. This
flexibility lends itself to a range of applications in many different sectors.
Question:
When was TensorFlow initial released ?
Question:
When was TensorFlow initial released ?
Answer:
2015
摘要
这在新闻、影片或者故事、培训总结等大段的文字中需要summery的时候比较有用。
#Text summarization
review = '''
While both Tensorflow and PyTorch are open-source, they have been created by two different wizards. Tensorflow is based on Theano and has been developed by Google, whereas PyTorch is based on Torch and has been developed by Facebook.
The most important difference between the two is the way these frameworks define the computational graphs. While Tensorflow creates a static graph, PyTorch believes in a dynamic graph. So what does this mean? In Tensorflow, you first have to define the entire computation graph of the model and then run your ML model. But in PyTorch, you can define/manipulate your graph on-the-go. This is particularly helpful while using variable length inputs in RNNs.
Tensorflow has a more steep learning curve than PyTorch. PyTorch is more pythonic and building ML models feels more intuitive. On the other hand, for using Tensorflow, you will have to learn a bit more about it’s working (sessions, placeholders etc.) and so it becomes a bit more difficult to learn Tensorflow than PyTorch.
Tensorflow has a much bigger community behind it than PyTorch. This means that it becomes easier to find resources to learn Tensorflow and also, to find solutions to your problems. Also, many tutorials and MOOCs cover Tensorflow instead of using PyTorch. This is because PyTorch is a relatively new framework as compared to Tensorflow. So, in terms of resources, you will find much more content about Tensorflow than PyTorch.
This comparison would be incomplete without mentioning TensorBoard. TensorBoard is a brilliant tool that enables visualizing your ML models directly in your browser. PyTorch doesn’t have such a tool, although you can always use tools like Matplotlib. Although, there are integrations out there that let you use Tensorboard with PyTorch. But it’s not supported natively.'''
print('\nOriginal text:\n')
print(wrapper.fill(review))
summarize = pipeline('summarization', model='sshleifer/distilbart-cnn-12-6')
summarized_text = summarize(review)[0]['summary_text']
print('\nSummarized text:')
print(wrapper.fill(summarized_text))
输出结果如下:
Summarized text:
While Tensorflow creates a static graph, PyTorch believes in a dynamic graph .
This is particularly helpful while using variable length inputs in RNNs .
TensorBoard is a brilliant tool that enables visualizing your ML models directly
in your browser . Pytorch is more pythonic and building ML models feels more
intuitive .
单词填空
这种在一些编辑器中比较常用,比如word中写文档的提示和拼写检查,还有一些代码编辑器也会提供类似的功能。
#Fill in the blanks
sentence = 'It is the national <mask> of China'
mask = pipeline('fill-mask', model='distilroberta-base')
masks = mask(sentence)
for m in masks:
print(m['sequence'])
其输出是按照概率排布的,即anthem的概率最大,其它依次类推,输出如下:
It is the national anthem of China
It is the national treasure of China
It is the national motto of China
It is the national pride of China
It is the national capital of China
翻译
不同语言之间的互相翻译的应用面还是挺广的。由于BERT内建模型并没有中英之间的互相翻译,所以这里选择了将英文翻译成中文为例。
#Translation
english = '''I like artificial intelligence very much!'''
translator = pipeline('translation_en_to_de', model='t5-base')
german = translator(english)
print('\nEnglish:')
print(english)
print('\nGerman:')
print(german[0]['translation_text'])
输出如下:
English:
I like artificial intelligence very much!
German:
Ich mag künstliche Intelligenz sehr!
Transoformers发展史
在2017年,大规模自然语言模型的一大挑战是数据集的标注工作,大量数据标注工作需要大量的人力、时间。随后提出的ULMFiT模型并不需要对数据集进行标注。这意味着如高质量的维基百科、书籍可以直接用于模型训练,2018年6月,open AI最先推出了生成预训练模型GTP(Generative pre-training model),其可用于多种NLP任务的细调,并是当时最高水平几个月之后,谷歌研究团队发布了BERT模型,上一节就是BERT能够在商业上应用的例子。2019年2月,OpenAI团队发布了更大、效果更好的模型GTP-2,但是OpenAI团队并没有开源GPT-2的细节,同年下半年,Facebook团队发布了BART,谷歌团队发布了T5,这两个都是使用和原始transformer相同架构的大型预训练模型,同年,也有使用更小模型的,DistilBERT模型大小只有BERT的60%,但性能却有BERT 的95%。2020年OpenAI团队提出了模型更大,准确度更高的GPT-3语言模型,开放了一些API,但是并未开放训练数据集和free的模型。它们发展的实践性和模型大小如图所示:
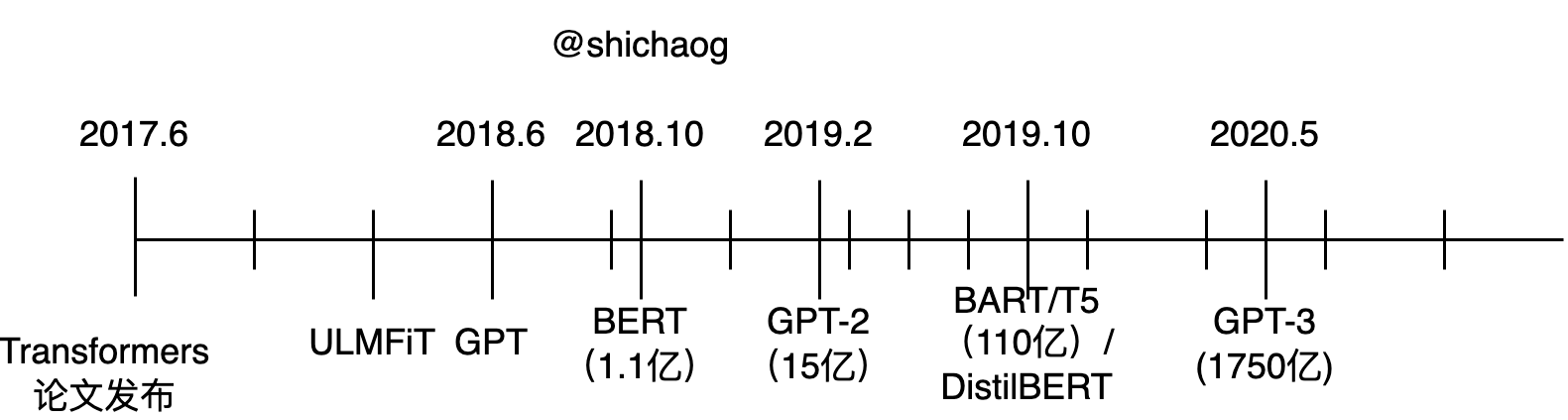
BERT 模型
BERT是Bidirectional Encoder Representations from Transformers的缩写,其训练数据使用了有25亿单词的英文维基百科以及8亿单词的出版书籍,BERT根据区分大小写和不区分大小写将模型分为两类,如果要计算区分大小写的BERT大小,可以通过BERT官方提供的模型checkpoint计算得到:
def get_model_size(checkpoint='bert-base-cased'):
'''
Usage:
checkpoint - NLP model with its configuration and its associated weights
returns the size of the NLP model
'''
model = AutoModel.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
num_params = 0
return sum(torch.numel(param) for param in model.parameters())
checkpoint = 'bert-base-cased'
print(f"The number of parameters for {
checkpoint} is : {
get_model_size(checkpoint)}")
输出是
The number of parameters for bert-base-cased is : 108310272
根据模型的参数里,大致可以计算模型推理运行需要的内存,每个参数是四字节的浮点数,上面显示参数量是1.08亿,算下来大概需要41.08=432M内存大小。如果要运行GPT3175模型,则需要1750004~ 700G内存。
transformer架构和BERT
《Attention is all you need》论文给出的transformer架构图如下:
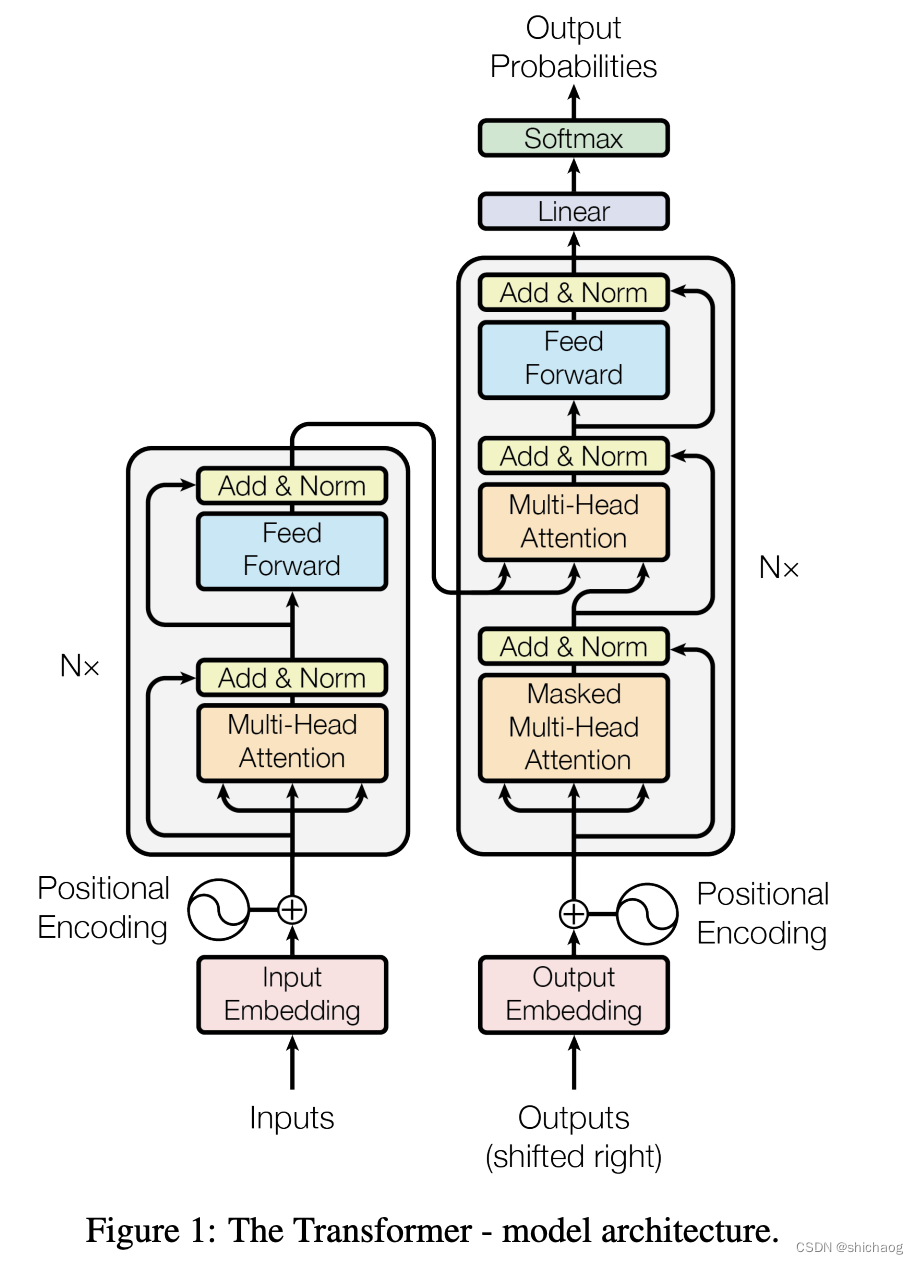
其左边是编码右边是解码部分,Nx encoder和decoder计数,该图中对应有六层encoder和六层decoder,对于诸如翻译、摘要等需要输入输出通用性任务,encoder-decoder架构则非常使适用,谷歌的BART和T5都是这类架构的语言模型,对于诸如只需要褒贬句意等之类的则只需要encoder部分即可,BERT, RoBERTa和 distilBERT属于这类模型,仅含decoder部分的语言模型适用于文本生成,比如OpenAI发布的GPT系列模型。
组成transformer的encoder和decoder的核心是self-attention,encoder结构是BERT的核心结构,而Attention是encoder和decoder的核心结构,transformer架构完全依赖于self-attention来绘制输入和输出之间的全局依赖关系。
selft-attention的公式表示:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T n ) V Attention(Q,K,V) =softmax(\frac{QK^T}{\sqrt{n}})V Attention(Q,K,V)=softmax(nQKT)V,Q是query,V是value,K是key,表示的是词向量之间距离,公式看起来比较抽象和晦涩,下面用简单例子说明该公式的计算过程。
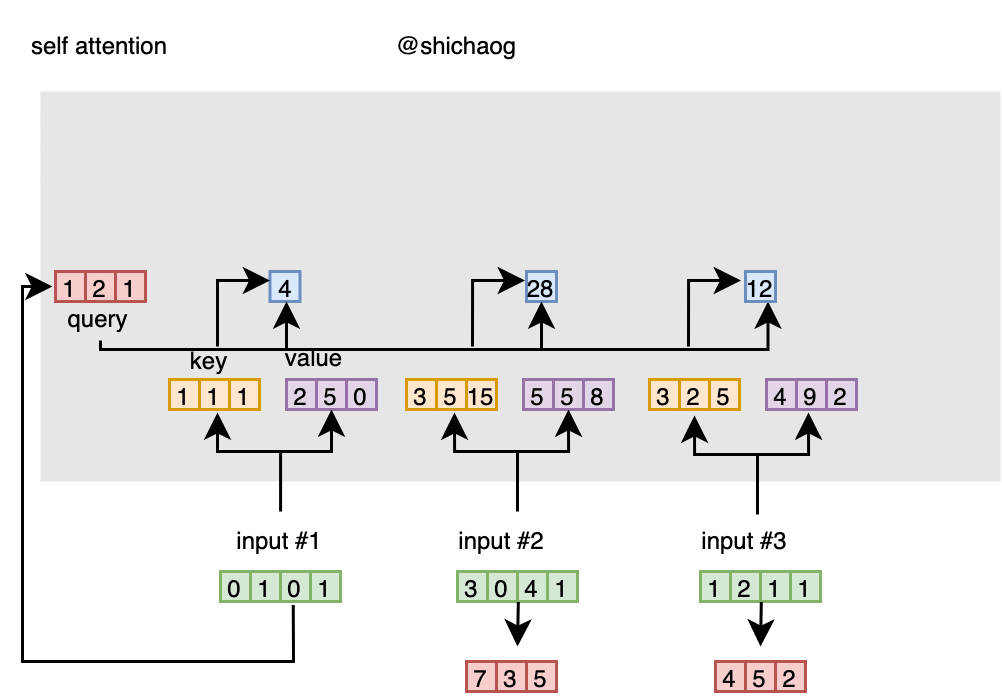
以下用例子说明self-attention的过程:
1.输入
2.权重初始化
3.推导key,query和value
4.为输入1计算attention打分
5.计算softmax
6.用打分值对value值加权(相乘)
7.步骤6得到的权重值得到输出1
8.对于输入2和输入3,重复步骤4-7
- 步骤1 准备输入
这里以三个四维为例表示输入:
Input 1: [0, 1, 0, 1]
Input 2: [3, 0, 4, 1]
Input 3: [1, 2, 1, 1]

- 权重初始化
每个输入向量都用三种key(黄色)、query(红色)和value(紫色)三种向量表示,且令三种表示的维度都是3,则可以得到权重维度为4*3。
为了获得key、query和value的三种表示,假设三种表示权重参数初始化(通常在深度神经网络都是使用浮点数,随机正态分布,初始化,在TensorFlow模型优化和调优实例提到过权重参数初始化,如下:
//key
[
[1, 0, 2],
[1, 0, 0],
[0, 1, 2],
[0, 1, 1]
]
//query
[
[1, 1, 0],
[1, 2, 0],
[1, 0, 1],
[0, 0, 1]
]
//value
[
[0, 1, 0],
[1, 3, 0],
[1, 0, 2],
[1, 2, 0]
]
- 计算key、query、value值
输入1的key计算如下:
[1, 0, 2]
[0, 1, 0, 1] x [1, 0, 0] = [1, 1, 1]
[0, 1, 2]
[0, 1, 1]
类似的输入2和输入3的key值计算如下:
//key2
[1, 0, 2]
[3, 0, 4, 1] x [1, 0, 0] = [3, 5, 15]
[0, 1, 2]
[0, 1, 1]
//key3
[1, 0, 2]
[1, 2, 1, 1] x [1, 0, 0] = [3, 2, 5]
[0, 1, 2]
[0, 1, 1]
key值的向量计算表示如下:
[1, 0, 2]
[0, 1, 0, 1] [1, 0, 0] [1, 1, 1]
[3, 0, 4, 1] x [0, 1, 2] = [3, 5, 15]
[1, 2, 1, 1] [0, 1, 1] [3, 2, 5]
类似的value值和query值(实际中还有bias值),计算如下:
//value
[0, 1, 0]
[0, 1, 0, 1] [1, 3, 0] [2, 5, 0]
[3, 0, 4, 1] x [1, 0, 2] = [5, 5, 8]
[1, 2, 1, 1] [1, 2, 0] [4, 9, 2]
//query
[1, 1, 0]
[0, 1, 0, 1] [1, 2, 0] [1, 2, 1]
[3, 0, 4, 1] x [1, 0, 1] = [7, 3, 5]
[1, 2, 1, 1] [0, 0, 1] [4, 5, 2]
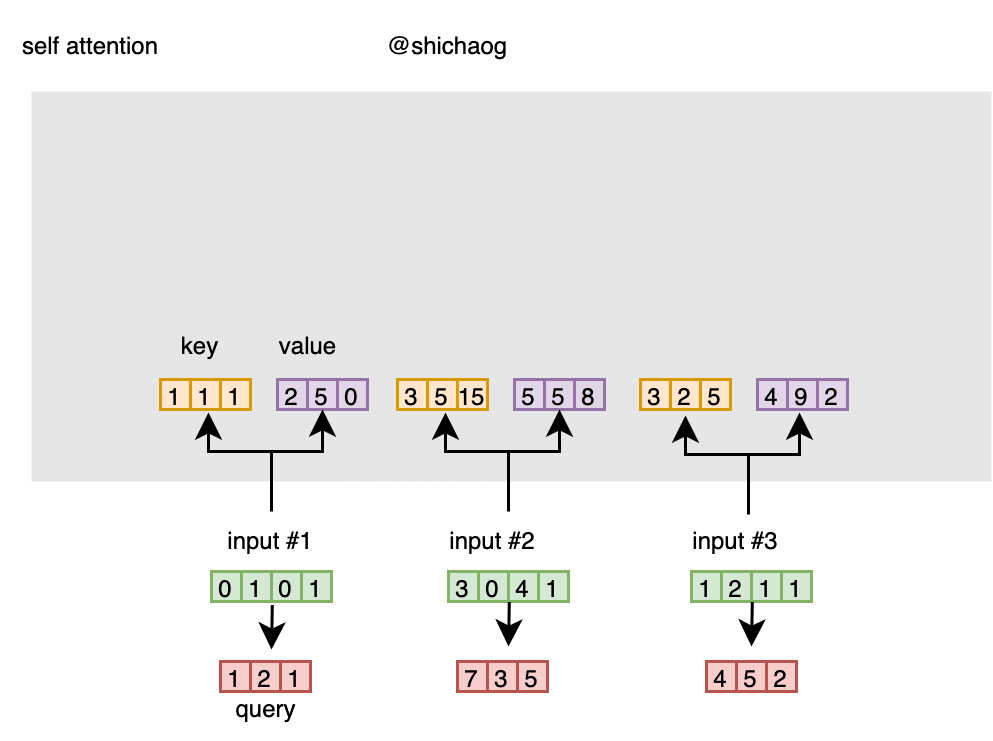
有了这三组值之后,就可以计算attention的打分了。
- 输入1的打分
为了计算其打分,需要将输入1的query值和所有的key值点乘(此外点乘外,还可以选择缩放的点乘、加或拼接等形式作为attention打分值),则可以得到是哪个蓝颜色的attention打分。
[1, 3, 3]
[1, 2, 1] x [1, 5, 2] = [4, 28, 12]
[1, 15, 5]
- 计算softmax值
对所有蓝色打分值做softmax运算,为了便于运算进行了四首五入。
softmax([2, 4, 4]) = [0.0, 1.0, 0.0]
- 将打分值和value值相乘
经过softmax之后的atten打分值和其相应的value值相乘,这样会得到三个对其的黄色向量,这被称为权重value值。
1: 0.0 * [2, 5, 0] = [0.0, 0.0, 0.0]
2: 1.0 * [5, 5, 8] = [5.0, 5.0, 8.0]
3: 0.0 * [4, 9, 2] = [0.0, 0.0, 0.0]
- 将权重value相加得到输出值
[0.0, 0.0, 0.0]
+ [5.0, 5.0, 8.0]
+ [0.0, 0.0, 0.0]
-----------------
= [5.0, 5.0, 8.0]
由input 1输入到输出的这一过程计算入下图,
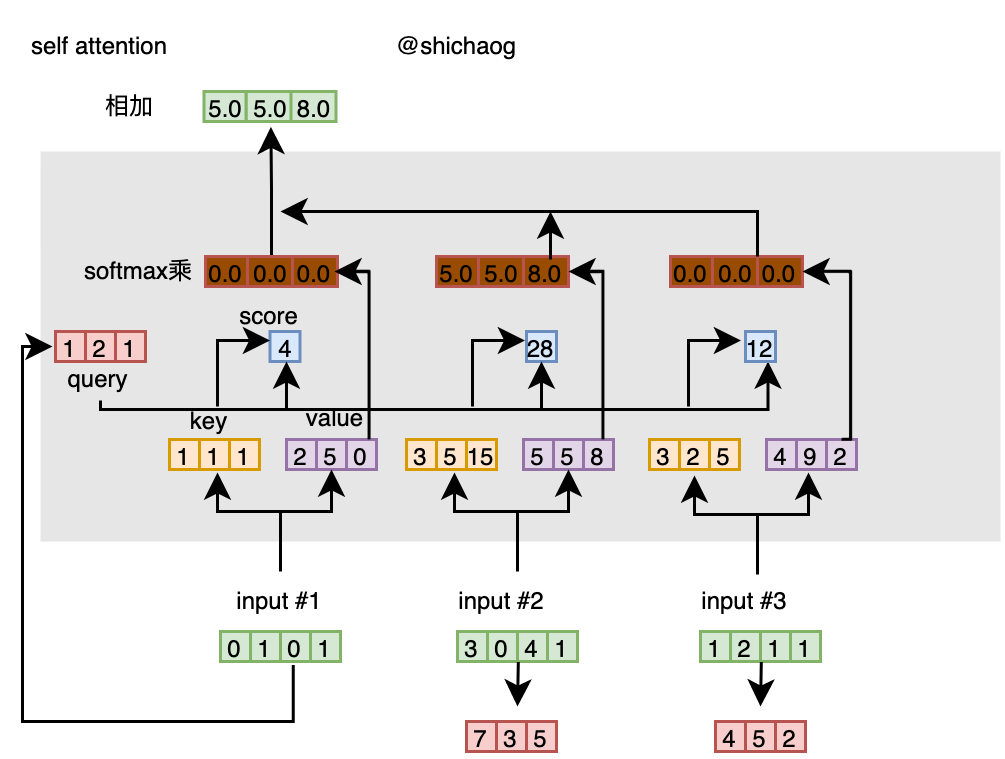
权重value值对应位置元素相加之后就是输入1的输出(称为输出1),即输出1是基于输入1的自身和其它所有key值的querey表示。
- 对输入2和输入3类似运算
BERT分类
使用开源影评数据集IMDB对BERT进行fine-tuning。该数据集有两列,一列是影评,对应的第二列是该影评正面还是负面的标注,1表示正面评价,0表示负面评价。
IMDB数据集的情况如下:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
如果使用完整的IMDB训练耗时较多,可以使用含2000句的影评以demofine-tuning,此外在原数据集上增加了validation数据集,以便验证训练时模型是过拟合还是欠拟合。
本博客代码下载地址链接
在深度学习之一 TensorFlow模型优化和调优实例一文提到模型优化方法,可以改变batchsize、epoch,以及使用distilbert-based-cased模型在和链接里的源码对比下模型的准确性/推理时间,