先修知识:
self-attention 到 Transformer:https://blog.csdn.net/weixin_41332009/article/details/114441708
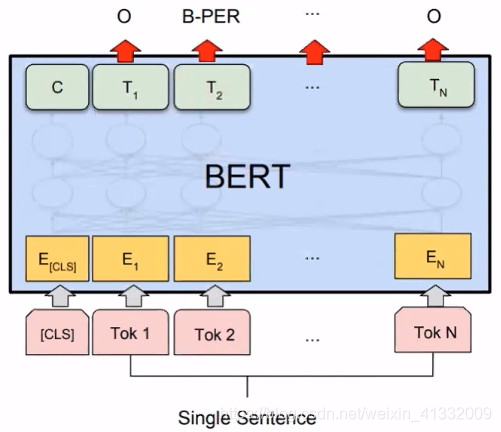
1. BERT简介
Bidirection: BERT的整个模型结构是双向的。
Encoder: 是一种编码器,BERT只是用到了Transformer的Encoder部分。
Representation: 做词的表征。
Transformer: Transformer是BERT的核心内部元素。
BERT的基本思想和 word2vec 中的 CBOW 是一样的,都是给定context,来预测下一个词。BERT的结构是双向结构。
2. BERT的模型结构
BERT的模型结构是Seq2Seq,核心是Transformer encoder。
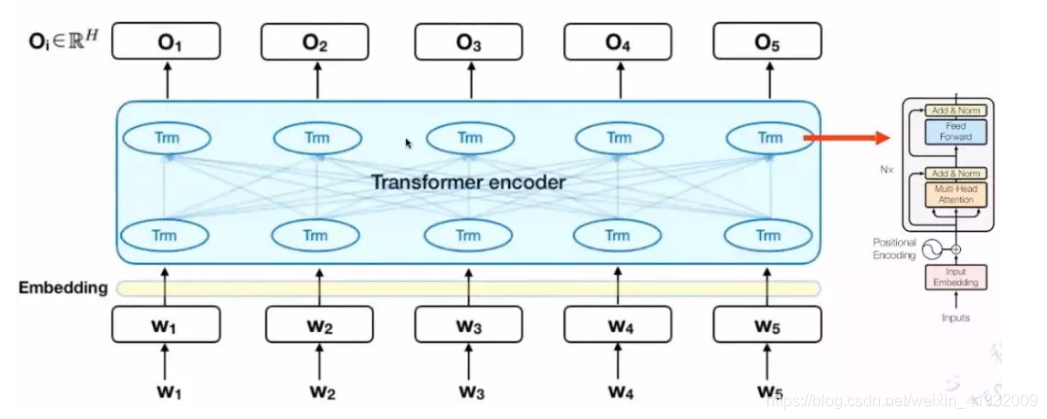
2.1 Bert模型的输入
BERT的输入包含三个部分:Token Embedding、Segment Embedding、Position Embedding。这三个部分在整个过程中是可以学习的。
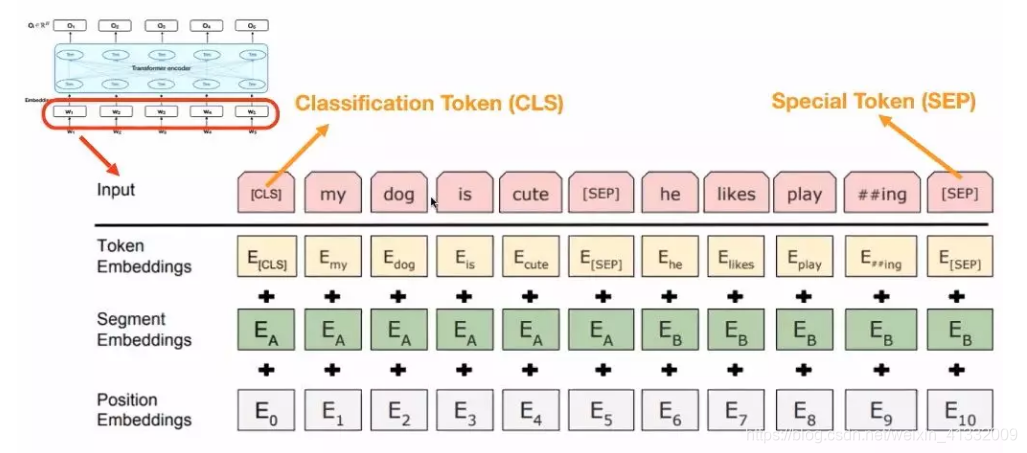
特殊字符介绍:
-
CLS,全称是Classification Token(CLS),是用来做一些分类任务。“CLS”token为什么会放在第一位?因为本身BERT是并行结构,“CLS”放在尾部也可以,放在中间也可以。放在第一个应该是比较方便。
-
SEP,全称是Special Token(SEP),是用来区分两个句子的,因为通常在train BERT的时候会输入两个句子。从上面图片中,可以看出SEP是区分两个句子的token。
3. BERT模型的不同训练方法
3.1 BERT的预训练
BERT是如何做预训练的?有两个任务:一是Masked Language Model(MLM);二是Next Sentence Prediction(NSP)。在训练BERT的时候,这两个任务是同时训练的。所以,BERT的损失函数是把这两个任务的损失函数加起来的,是一个多任务训练。
BERT官方提供了两个版本的BERT模型。一个是BERT的BASE版,另一个是BERT的LARGE版。BERT的BASE版有12层的Transformer,隐藏层Embedding的维度是768,head是12个,参数总数大概是一亿一千万。BERT的LARGE版有24层的Transformer,隐藏层Embedding的维度是1024,head是16个,参数总数大概是三亿四千万。
3.1.1 BERT-Masked Language Model
什么是Masked Language Model?它的灵感来源于完形填空。具体在BERT中,掩盖了15% 的Tokens。这掩盖了15%的Tokens又分为三种情况:
- 有80%的字符用“MASK”这个字符替换,如:My dog is hairy -> My dog is [MASK].
- 有10%的字符用另外的字符替换,如:My dog is hairy -> My dog is apple
- 有10%的字符是保持不动,如: My dog is hairy -> My dog is hairy.
让模型去预测/恢复被掩盖的那些词语。最后在计算损失时,只计算被掩盖的这些Tokens(也就是掩盖的那15%的Tokens)
3.1.2 BERT-Next Sentence Prediction
Next Sentence Prediction是更关注于两个句子之间的关系。与Masked Language Model任务相比,Next Sentence Prediction更简单些。

4. What does BERT look like?
训练好BERT之后,我们来研究BERT内部的机制。BERT的BASE版本有12个head,每一个head是否有相同的功能?
如下图所示,第一个head的连线非常的密集,它是Attends broadly;对于第3个head到第1个head,更关注的是下一个单词;对于第8个head到第7个head,更关注的是句子的分割符(SEP);对于第11个head到第6个head,更关注的是句子的句号。
所以,对于每一个head来说,代表的意义是不一样的, 这也是BERT强大的原因。BERT本身的Multi-Headed结构可以抓住不一样的特征,包括全局的特征、局部的特征等。(就像CNN中不同的卷积核能捕捉到不同的信息一样)

BERT的BASE版有12层的Transformer,下图中的每一个颜色代表一层的Transformer,相同颜色会聚集的比较近。相同层的head是非常相近的。
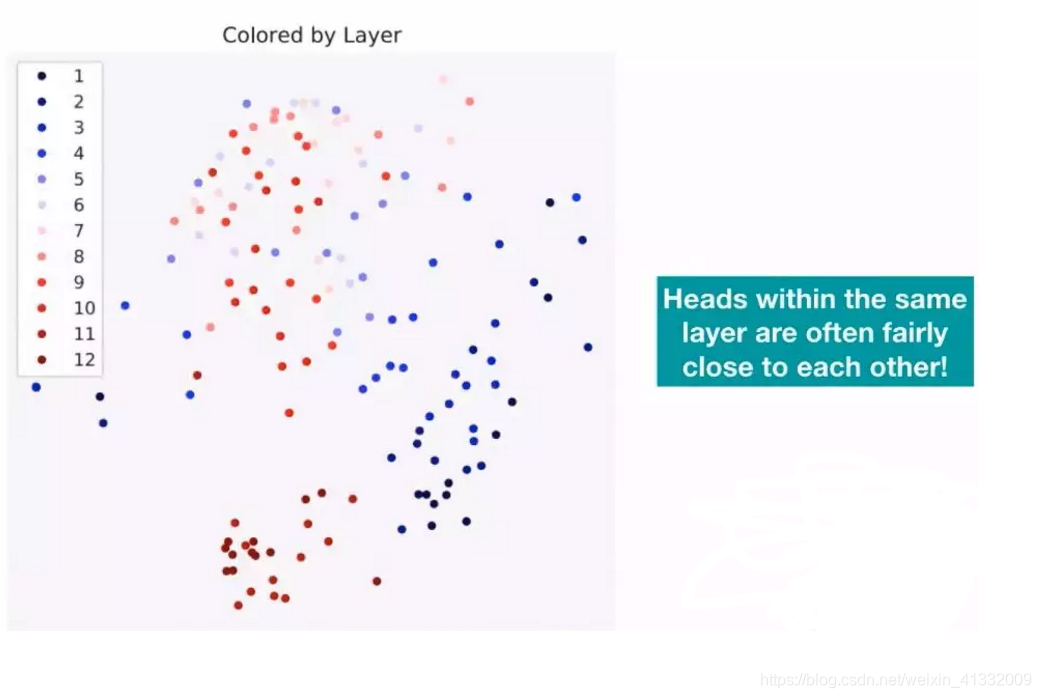
针对上面两幅图进行总结,对于含有12层 +12个Head的BERT模型,对于每一层来说,它的Head的功能是相似的;对于每一个Head里面的Attention表现出的功能是完全不一样的。
5. BERT在实际项目中的应用
5.1 Classification
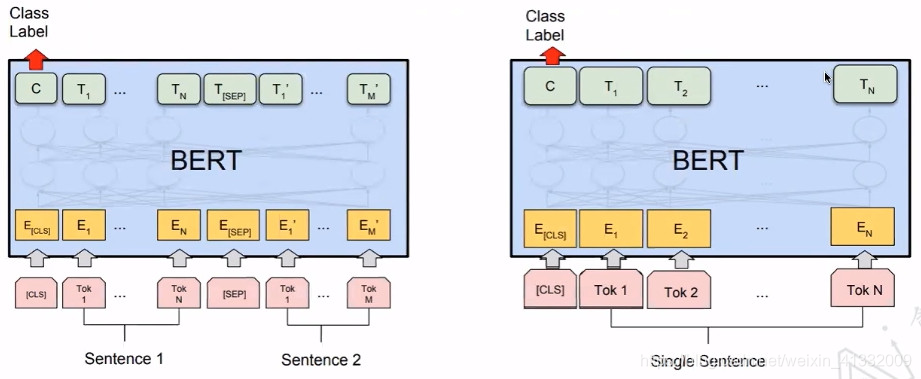
5.2 Question Answering

5.3 Name Entity Recognition