Series
Series是一种类似Python中字典的对象,它由一组数据以及一组与之对应的标签组成。
# 一个简单的SEries
import pandas as pd
s = pd.Series(['a','b','c','d'], index=[1,2,3,4])
print(s)

Series的字符串表现形式为: 索引在左边,值在右边,当没有指定索引的时候会自动创建一个从0-N的整数索引。
Series可以像字典一样通过索引获取它的值

因为数据结构相似,所以一个字典可以很轻易的转换为一个Series
import pandas as pd
dt = {
'a': 100,
'b': 200,
'c': 300
}
s = pd.Series(dt)
print(s)
得到的执行结果中,字典的键就是Series的索引,字典的值就是索引对应的值。
a 100
b 200
c 300
dtype: int64
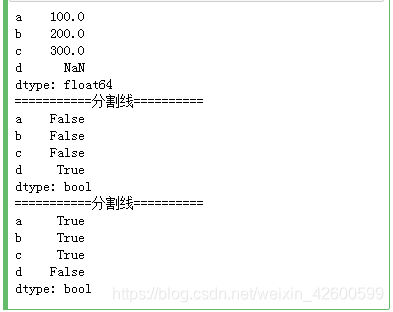
当对应的键没有相匹配的值的时候,pandas会用NaN(缺失或非数字)表示。
import pandas as pd
dt = {
'a': 100,
'b': 200,
'c': 300,
'd': None
}
s = pd.Series(dt)
print(s)
# pandasd isnull和nothull函数用于检测缺失数据
print('===========分割线==========')
print(pd.isnull(s))
print('===========分割线==========')
print(pd.notnull(s))
# Series中也有类似的方法
s.isnull() # 执行结果与上面一样。
就这样传入的数据显示出来是第一列是索引,后面是数据,也可以换过来,第一行是索引,后面每一行书数据:
import pandas as pd
# 创建3个Series
s1 = pd.Series([1, 2, 3], index=[1,2,3], name='A')
s2 = pd.Series([10, 20, 30], index=[1,2,3], name='B')
s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name='C')
# 把没个Series做为一行加到一个DateFrame中
df = pd.DataFrame({s1.name:s1, s2.name:s2, s3.name:s3})
print(df)

Series中的常用属性
Series.indes : 索引,相当于字典中的keys
Series.data : 值,相当于字典中的vlues
Series.name : name