第一次接触,在网上搜了些资料,把自己能看懂和觉得写的不错的贴上来,供参考。前面两大点是知乎上的两个长篇,个人觉得写的很好(主要是对我这小白看得懂(ˉ▽ˉ;)),后面几大点是一些概念解释。
另外,网易公开课上的斯坦福大学的机器学习公开课可以看看,一共20节,每节1小时。看了一节课,讲的还是很通俗易懂的,我这种把上学的时候学的内容都忘的差不多的,不知道后面涉及数学的部分听不听得懂,慢慢看。
一、
https://www.zhihu.com/question/29271217?sort=created
机器学习为什么需要训练,训练出来的模型具体又是什么?
1、
很久没从事专业相关工作,尽力说一下自己的理解,可能有些表述不是特别精确,烦请指正并见谅。
先从有监督问题谈起,形式上,无论解析还是非解析,有监督问题都可看作根据已知数据在全体映射空间举个例子,求解找规律题目“1, 2, 3, 4, ( ), 6”,一般人都会在括号里填5。然而理论
上来说这个括号里可以是任意数字,比如4。不知道大家是否考虑过凭什么“每次增1”是规律
而“先增三次1然后保持不变然后再持续增1”就不可以是规律。那是因为我们不知不觉中使用了
题目并未给出的一些前提假设,比如奥卡姆剃刀原则,“每次增1”看起来明显比后者更简洁优
雅,更容易被人接受。
解释这个概念就不能不提到Inductive Bias,意指在求解学习问题前必须拥有的一系列前提假设。当我们选定一个广义上的model,其实可以看作选定了一组inductive bias。特定的model/inductive bias可以在浩瀚的全体映射空间中圈定出一个子空间
,然后通过inductive bias提供的方式(一般为某种loss function)寻找符合已知数据的model参数,从而又在
中进一步缩小搜索范围直至确定最优或次优映射
(
可能本不在
中)。
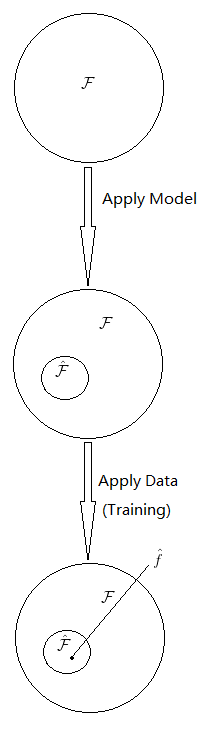
所以应了那句话,“All models are wrong, but some are useful.” 得出什么样的答案,很大程度上取决于我们使用什么样的假设。
那么此问题的答案是:模型是求解学习问题的一系列前提假设/inductive bias,根据已知数据寻找模型参数的过程就是训练,最终搜索到的映射被称为训练出来的模型。
注:
1. 这里所谓的“最优”,“次优”,“符合”等描述是根据预先设定好的测量标准/目标函数进行
阐释的,属于model/inductive bias的一部分。
2. 之所以说“广义上的model”,是因为一般形式上会对prior distribution,model(实际指映射
表达式)以及loss function等进行区分,这里为方便阐述,不加区分的算成广义上
的model,因其均为inductive bias。
无监督问题大致上也类似,前提假设甚至会表现得更为明显,有一则段子:
@南大周志华“聚类的故事:老师拿来苹果和梨,让小朋友分成两份。小明把大苹果大梨放一起,小个头的放一起,老师点头,恩,体量感。小芳把红苹果挑出来,剩下的放一起,老师点头,颜色感。小武的结果?不明白。小武掏出眼镜:最新款,能看到水果里有几个籽,左边这堆单数,右边双数。老师很高兴:新的聚类算法诞生了”
PS: 人类的各种错觉,比如视错觉,也可看成是一系列人脑硬编码的inductive bias,用以辅助学习方便解决现实问题,所以各假设都具有其对应的适用范围。
参考:机器学习物语(1):世界观设定 « Free Mind
Inductive bias
University of Edinburgh MLPR 2012 Lecture - Introduction
2、
谢 张之诗 邀。我用两个分类的例子简单说明下,有错误的地方还请指出。
假设现在我们要开发一个识别鸟类的计算机程序。我们已经收集了很多鸟类样本数据,比如下面这样:
 (图片和例子来自
机器学习实战 )
(图片和例子来自
机器学习实战 )
这个识别鸟类的程序要完成的功能:输入一只鸟的“体重”、“翼展”、“有/无脚蹼”、“后背颜色”,输出这只鸟的种类。
换句话说,这是一个分类系统。
怎么让计算机帮助我们对鸟类进行分类?这就需要使用机器学习的方法。机器学习可以让计算机从已有的数据(上面收集的已经有分类信息的鸟类样本数据)中学习出新的知识(如何对鸟进行分类)。
那么什么是训练?在这个例子里,训练指的就是利用收集的鸟类样本数据让计算机学习如何对鸟类进行分类这一过程。
已有类别信息的鸟类样本数据集合,称为训练数据集、训练集。训练的目的是让计算机程序知道“如何进行分类”。
至于“训练的是什么”、“参数是什么”,这依赖于我们所选取的“模型”。训练的结果简单来说就是得到一组模型的参数,最后使用采用这些参数的模型来完成我们的分类任务。
再举一个简单例子说明“模型”和“模型的参数”。
假设现在我们收集了一些二维平面上的点:
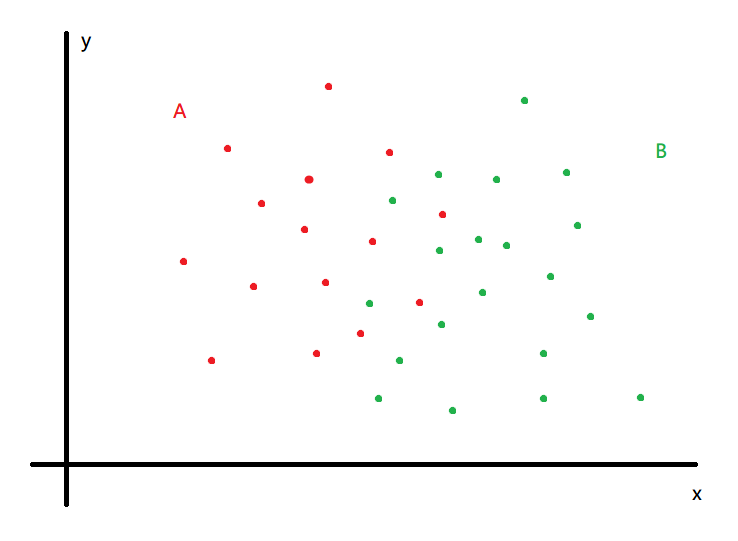
红色的点记为A类,绿色的点记为B类,这些点的坐标和类别信息都是已知的。现在任务是,给出一个新的点的坐标,判断它是A类还是B类。
简单观察一下数据,好像我们可以用一条平行于 y 轴的直线把 A 类点和 B 类点分开。大概是这个样子:
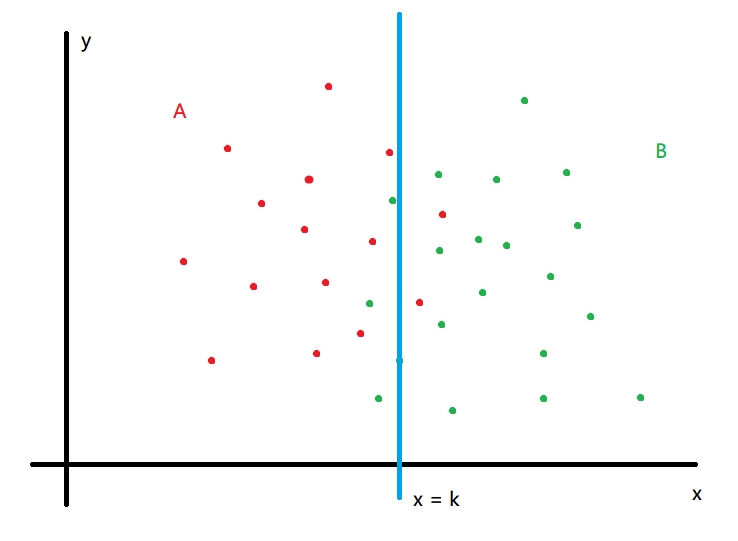
我们希望找到这样一条直线 x = k,直线左边绝大多数点都是 A 类,直线右边绝大多数点都是 B 类。
于是我们的分类器模型就是 x = k 这样的直线,k 就是我们的模型参数。
训练的过程就是利用已有的数据点确定参数 k 的过程。假设我们的训练结果是 k = k_0 ,那么我们就可以用 x = k_0 这条直线作为分类器对新的点进行分类了。
当然实际应用中的模型可能要复杂的多,模型参数也不会只有一个 k 这么简单。二、各种机器学习的应用场景分别是什么?例如,k近邻,贝叶斯,决策树,svm……
https://www.zhihu.com/question/26726794
关于这个问题我今天正好看到了这个文章。讲的正是各个算法的优劣分析,很中肯。
https://zhuanlan.zhihu.com/p/25327755正好14年的时候有人做过一个实验[1],比较在不同数据集上(121个),不同的分类器(179个)的实际效果。
论文题为:Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
实验时间有点早,我尝试着结合我自己的理解、一些最近的实验,来谈一谈吧。主要针对分类器(Classifier)。
写给懒得看的人:
没有最好的分类器,只有最合适的分类器。
随机森林平均来说最强,但也只在9.9%的数据集上拿到了第一,优点是鲜有短板。
SVM的平均水平紧随其后,在10.7%的数据集上拿到第一。
神经网络(13.2%)和boosting(~9%)表现不错。
数据维度越高,随机森林就比AdaBoost强越多,但是整体不及SVM[2]。
数据量越大,神经网络就越强。
近邻 (Nearest Neighbor)
典型的例子是KNN,它的思路就是——对于待判断的点,找到离它最近的几个数据点,根据它们的类型决定待判断点的类型。
它的特点是完全跟着数据走,没有数学模型可言。
适用情景:
需要一个特别容易解释的模型的时候。
比如需要向用户解释原因的推荐算法。
贝叶斯 (Bayesian)
典型的例子是Naive Bayes,核心思路是根据条件概率计算待判断点的类型。
是相对容易理解的一个模型,至今依然被垃圾邮件过滤器使用。
适用情景:
需要一个比较容易解释,而且不同维度之间相关性较小的模型的时候。
可以高效处理高维数据,虽然结果可能不尽如人意。
决策树 (Decision tree)
决策树的特点是它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。
虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。
举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
适用情景:
因为它能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器[3]。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
随机森林 (Random forest)
提到决策树就不得不提随机森林。顾名思义,森林就是很多树。
严格来说,随机森林其实算是一种集成算法。它首先随机选取不同的特征(feature)和训练样本(training sample),生成大量的决策树,然后综合这些决策树的结果来进行最终的分类。
随机森林在现实分析中被大量使用,它相对于决策树,在准确性上有了很大的提升,同时一定程度上改善了决策树容易被攻击的特点。
适用情景:
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
SVM (Support vector machine)
SVM的核心思想就是找到不同类别之间的分界面,使得两类样本尽量落在面的两边,而且离分界面尽量远。
最早的SVM是平面的,局限很大。但是利用核函数(kernel function),我们可以把平面投射(mapping)成曲面,进而大大提高SVM的适用范围。
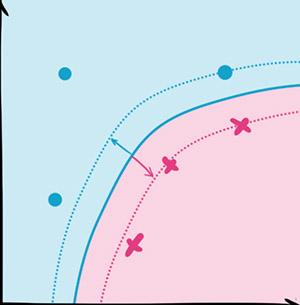
提高之后的SVM同样被大量使用,在实际分类中展现了很优秀的正确率。
适用情景:
SVM在很多数据集上都有优秀的表现。
相对来说,SVM尽量保持与样本间距离的性质导致它抗攻击的能力更强。
和随机森林一样,这也是一个拿到数据就可以先尝试一下的算法。
逻辑斯蒂回归 (Logistic regression)
逻辑斯蒂回归这个名字太诡异了,我就叫它LR吧,反正讨论的是分类器,也没有别的方法叫LR。顾名思义,它其实是回归类方法的一个变体。
回归方法的核心就是为函数找到最合适的参数,使得函数的值和样本的值最接近。例如线性回归(Linear regression)就是对于函数f(x)=ax+b,找到最合适的a,b。
LR拟合的就不是线性函数了,它拟合的是一个概率学中的函数,f(x)的值这时候就反映了样本属于这个类的概率。
适用情景:
LR同样是很多分类算法的基础组件,它的好处是输出值自然地落在0到1之间,并且有概率意义。
因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。
虽然效果一般,却胜在模型清晰,背后的概率学经得住推敲。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。
判别分析 (Discriminant analysis)
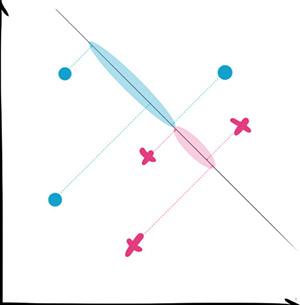
判别分析主要是统计那边在用,所以我也不是很熟悉,临时找统计系的闺蜜补了补课。这里就现学现卖了。
判别分析的典型例子是线性判别分析(Linear discriminant analysis),简称LDA。
(这里注意不要和隐含狄利克雷分布(Latent Dirichlet allocation)弄混,虽然都叫LDA但说的不是一件事。)
LDA的核心思想是把高维的样本投射(project)到低维上,如果要分成两类,就投射到一维。要分三类就投射到二维平面上。这样的投射当然有很多种不同的方式,LDA投射的标准就是让同类的样本尽量靠近,而不同类的尽量分开。对于未来要预测的样本,用同样的方式投射之后就可以轻易地分辨类别了。
使用情景:
判别分析适用于高维数据需要降维的情况,自带降维功能使得我们能方便地观察样本分布。它的正确性有数学公式可以证明,所以同样是很经得住推敲的方式。
但是它的分类准确率往往不是很高,所以不是统计系的人就把它作为降维工具用吧。
同时注意它是假定样本成正态分布的,所以那种同心圆形的数据就不要尝试了。
神经网络 (Neural network)
神经网络现在是火得不行啊。它的核心思路是利用训练样本(training sample)来逐渐地完善参数。还是举个例子预测身高的例子,如果输入的特征中有一个是性别(1:男;0:女),而输出的特征是身高(1:高;0:矮)。那么当训练样本是一个个子高的男生的时候,在神经网络中,从“男”到“高”的路线就会被强化。同理,如果来了一个个子高的女生,那从“女”到“高”的路线就会被强化。
最终神经网络的哪些路线比较强,就由我们的样本所决定。
神经网络的优势在于,它可以有很多很多层。如果输入输出是直接连接的,那它和LR就没有什么区别。但是通过大量中间层的引入,它就能够捕捉很多输入特征之间的关系。卷积神经网络有很经典的不同层的可视化展示(visulization),我这里就不赘述了。
神经网络的提出其实很早了,但是它的准确率依赖于庞大的训练集,原本受限于计算机的速度,分类效果一直不如随机森林和SVM这种经典算法。
使用情景:
数据量庞大,参数之间存在内在联系的时候。
当然现在神经网络不只是一个分类器,它还可以用来生成数据,用来做降维,这些就不在这里讨论了。
Rule-based methods
这个我是真不熟,都不知道中文翻译是什么。
它里面典型的算法是C5.0 Rules,一个基于决策树的变体。因为决策树毕竟是树状结构,理解上还是有一定难度。所以它把决策树的结果提取出来,形成一个一个两三个条件组成的小规则。
使用情景:
它的准确度比决策树稍低,很少见人用。大概需要提供明确小规则来解释决定的时候才会用吧。
提升算法(Boosting)
接下来讲的一系列模型,都属于集成学习算法(Ensemble Learning),基于一个核心理念:三个臭皮匠,顶个诸葛亮。
翻译过来就是:当我们把多个较弱的分类器结合起来的时候,它的结果会比一个强的分类器更
典型的例子是AdaBoost。
AdaBoost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权取和(weighted sum)的方式把这个新分类器结合进已有的分类器中。
它的好处是自带了特征选择(feature selection),只使用在训练集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题。
最经典的AdaBoost实现中,它的每一个弱分类器其实就是一个决策树。这就是之前为什么说决策树是各种算法的基石。
使用情景:
好的Boosting算法,它的准确性不逊于随机森林。虽然在[1]的实验中只有一个挤进前十,但是实际使用中它还是很强的。因为自带特征选择(feature selection)所以对新手很友好,是一个“不知道用什么就试一下它吧”的算法。
装袋算法(Bagging)
同样是弱分类器组合的思路,相对于Boosting,其实Bagging更好理解。它首先随机地抽取训练集(training set),以之为基础训练多个弱分类器。然后通过取平均,或者投票(voting)的方式决定最终的分类结果。
因为它随机选取训练集的特点,Bagging可以一定程度上避免过渡拟合(overfit)。
在[1]中,最强的Bagging算法是基于SVM的。如果用定义不那么严格的话,随机森林也算是Bagging的一种。
使用情景:
相较于经典的必使算法,Bagging使用的人更少一些。一部分的原因是Bagging的效果和参数的选择关系比较大,用默认参数往往没有很好的效果。
虽然调对参数结果会比决策树和LR好,但是模型也变得复杂了,没事有特别的原因就别用它了。
Stacking
这个我是真不知道中文怎么说了。它所做的是在多个分类器的结果上,再套一个新的分类器。
这个新的分类器就基于弱分类器的分析结果,加上训练标签(training label)进行训练。一般这最后一层用的是LR。
Stacking在[1]里面的表现不好,可能是因为增加的一层分类器引入了更多的参数,也可能是因为有过渡拟合(overfit)的现象。
使用情景:
没事就别用了。
(修订:
提醒说stacking在数据挖掘竞赛的网站kaggle上很火,相信参数调得好的话还是对结果能有帮助的。http://blog.kaggle.com/2016/12/27/a-kagglers-guide-to-model-stacking-in-practice/
这篇文章很好地介绍了stacking的好处。在kaggle这种一点点提升就意味着名次不同的场合下,stacking还是很有效的,但是对于一般商用,它所带来的提升就很难值回额外的复杂度了。)
多专家模型(Mixture of Experts)
最近这个模型还挺流行的,主要是用来合并神经网络的分类结果。我也不是很熟,对神经网络感兴趣,而且训练集异质性(heterogeneity)比较强的话可以研究一下这个。
讲到这里分类器其实基本说完了。讲一下问题里面其他一些名词吧。
最大熵模型 (Maximum entropy model)
最大熵模型本身不是分类器,它一般是用来判断模型预测结果的好坏的。
对于它来说,分类器预测是相当于是:针对样本,给每个类一个出现概率。比如说样本的特征是:性别男。我的分类器可能就给出了下面这样一个概率:高(60%),矮(40%)。
而如果这个样本真的是高的,那我们就得了一个分数60%。最大熵模型的目标就是让这些分数的乘积尽量大。
LR其实就是使用最大熵模型作为优化目标的一个算法[4]。
EM
就像最大熵模型一样,EM不是分类器,而是一个思路。很多算法都是基于这个思路实现的。
@刘奕驰 已经讲得很清楚了,我就不多说了。
隐马尔科夫 (Hidden Markov model)
这是一个基于序列的预测方法,核心思想就是通过上一个(或几个)状态预测下一个状态。
之所以叫“隐”马尔科夫是因为它的设定是状态本身我们是看不到的,我们只能根据状态生成的结果序列来学习可能的状态。
适用场景:
可以用于序列的预测,可以用来生成序列。
条件随机场 (Conditional random field)
典型的例子是linear-chain CRF。
具体的使用 @Aron 有讲,我就不献丑了,因为我从来没用过这个。
就是这些啦。
相关的文章:
[1]: Do we need hundreds of classifiers to solve real world classification problems.
Fernández-Delgado, Manuel, et al. J. Mach. Learn. Res 15.1 (2014)
[2]: An empirical evaluation of supervised learning in high dimensions.
Rich Caruana, Nikos Karampatziakis, and Ainur Yessenalina. ICML '08
[3]: Man vs. Machine: Practical Adversarial Detection of Malicious Crowdsourcing Workers
Wang, G., Wang, T., Zheng, H., & Zhao, B. Y. Usenix Security'14
[4]: http://www.win-vector.com/dfiles/LogisticRegressionMaxEnt.pdf
三、贝叶斯公式
用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。如上公式也可变形为:P(B|A) = P(A|B)*P(B) / P(A)。
例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,P(A) = 3/7,P(B) = 2/(20*365) = 2/7300,P(A|B) = 0.9,按照公式很容易得出结果:P(B|A) = 0.9*(2/7300) / (3/7) = 0.00058
三、没有免费的午餐定理和丑小鸭定理
关于没有免费的午餐定理,网上很多都是各种公式,实在看的头大,大体总结就是:
1、在机器学习算法中的体现为在没有实际背景下,没有一种算法比随机胡猜的效果好。
2、没有免费的午餐定理(No Free Lunch Theorem),这个定理说明
若学习算法LaLa 在某些问题上比学习算法LbLb 要好,
那么必然存在另一些问题, 在这些问题中LbLb 比La表现更好。
个人觉得就是基于前面的Inductive bias,在有假设条件或说假设空间的前提下,才有最优算法的概念。就像说一个人比另一个人利害,这个不一定,但是限定一个范围以后就可以进行评价了。
3、http://blog.csdn.net/mnshenyanping/article/details/51280731
没有免费的午餐定理(noerfelunhchtocerm,简称NFL)。该定理由wolpert和Macerday提出,结论是由于对所有可能函数的相互补偿,最优化算法的性能是等价的。该定理暗指,没有其它任何算法能够比搜索空间的线性列举或者纯随机搜索算法更优。该定理只是定义在有限的搜索空间,对无限搜索空间结论是否成立尚不清楚。
丑小鸭定理(Ugly Duckling) 上个世纪60年代,模式识别研究的鼻祖之一,美籍日本学者渡边慧证明了“丑小鸭定理”。这个定理说的是“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”。这个看起来完全违背常识的定理实际上说的是:世界上不存在分类的客观标准,一切分类的标准都是主观的。渡边慧举了一个鲸鱼的例子说明这个定理:按照生物学的分类方法,鲸鱼属于哺乳类的偶蹄目,和牛是一类;但是在产业界,捕鲸与捕鱼都要行船出海,鲸和鱼同属于水产业,而不属于包括牛的畜牧业。分类结果取决于选择什么特征作为分类标准,而特征的选择又依存于人的目的。丑小鸭是白天鹅的幼雏,在画家的眼里,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是在遗传学家的眼里,丑小鸭与其父亲或母亲的差别小于父母之间的差别。 由此引出的一个问题是,事物有没有“本质”?一个苹果,牛顿看到的是它的质量,遗传学家看到的是它的染色体中的DNA序列,美食家关心的是它的味道,画家看到的是它的颜色和形状,孔融还可能关注其大小并从中看出道德因素。这里面没有谁对谁错的问题,所以不可能知道苹果的“本质”是什么。在说到“本质”的时候,充其量说的只是“我认为最重要的特征”,只代表个人的立场,他人并没有赞同的充分理由。所以任何使用“本质”这个词汇所进行的论证都是靠不住的。如果一个哲学家说:“思维是人的本质,计算机不具备这种本质,所以机器不能思维。”这种论证只相当于说:“我认为计算机不能思维,所以计算机不能思维。”这当然不能成为有效的论证。问题就在于世界上还不存在能够判断什么是事物的本质的公认的有效方法。