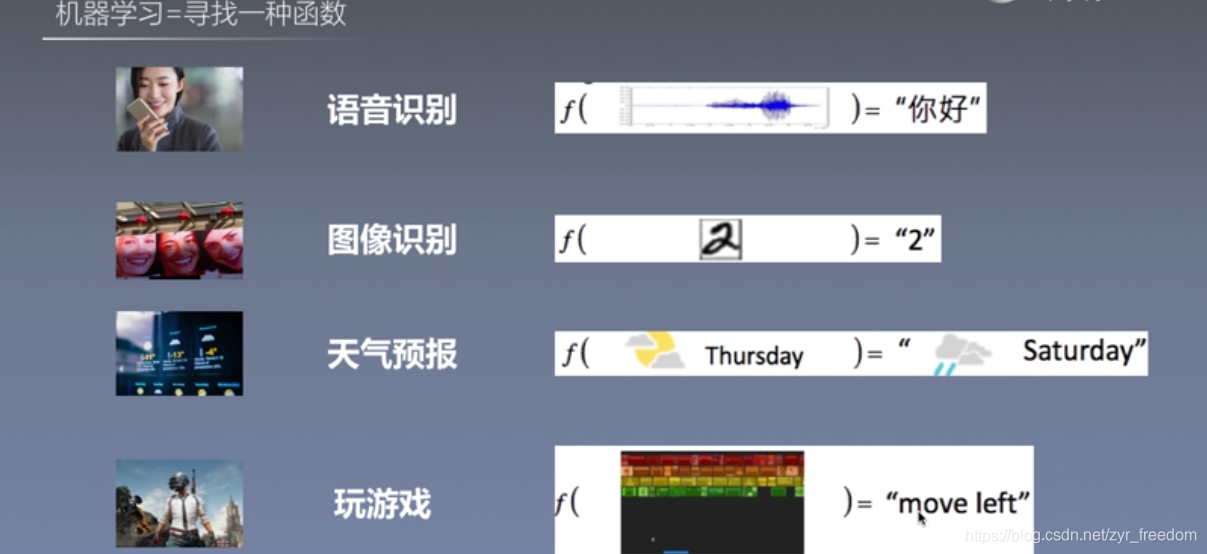
一、机器学习目的寻找一个函数:这个函数可以完成的常见功能如图
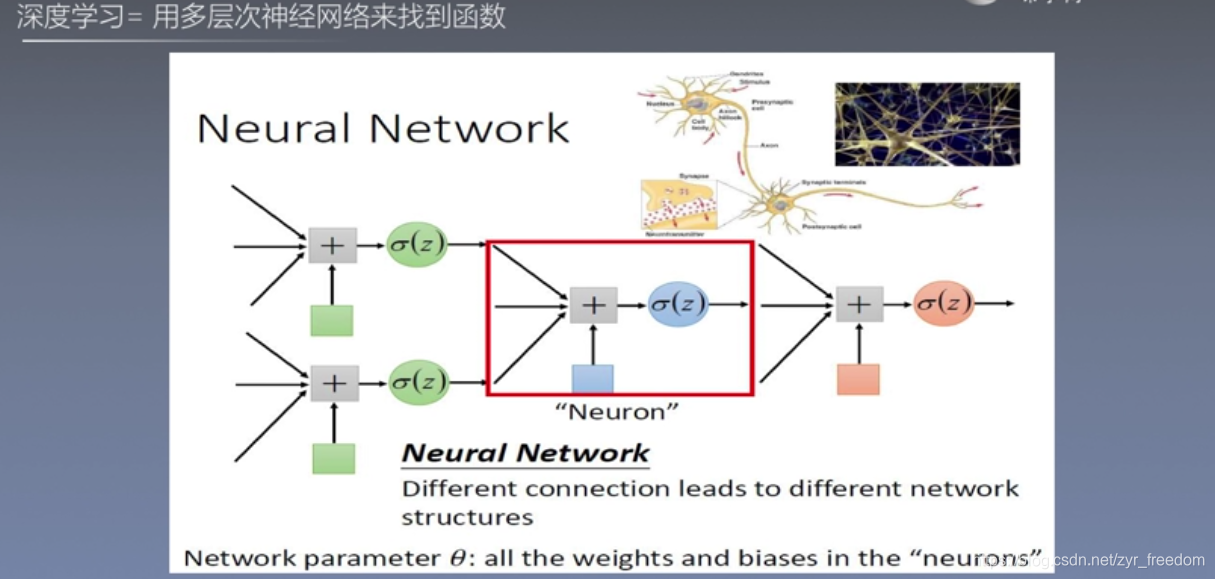
step1:定义一系列有一定功能的函数
step2:验证这一系列函数的 优劣性
step3:寻找一个最优的函数
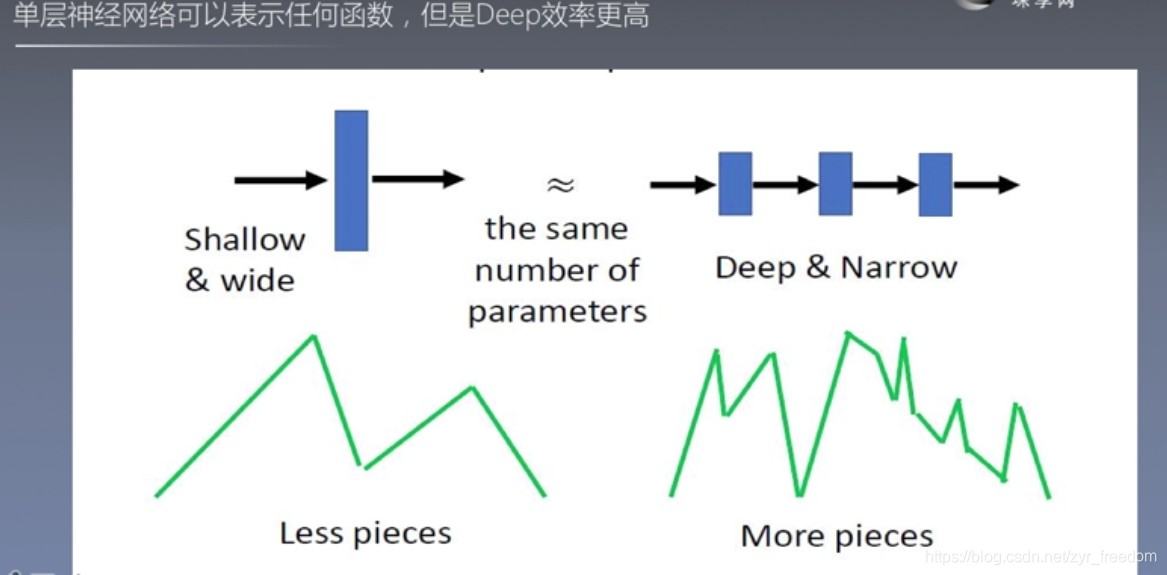
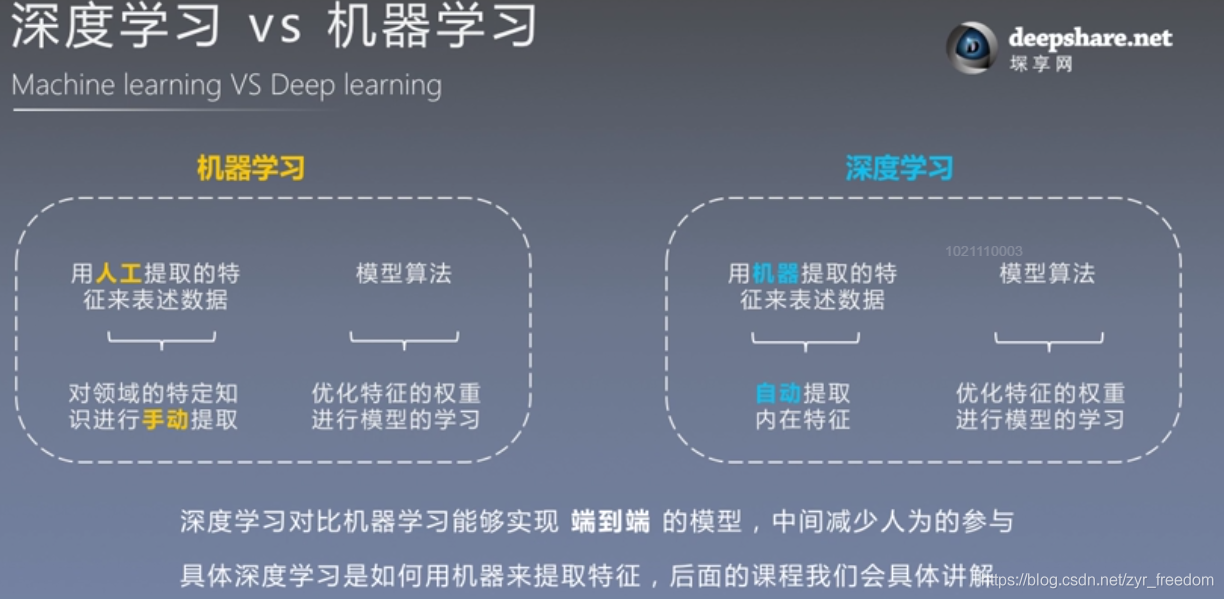

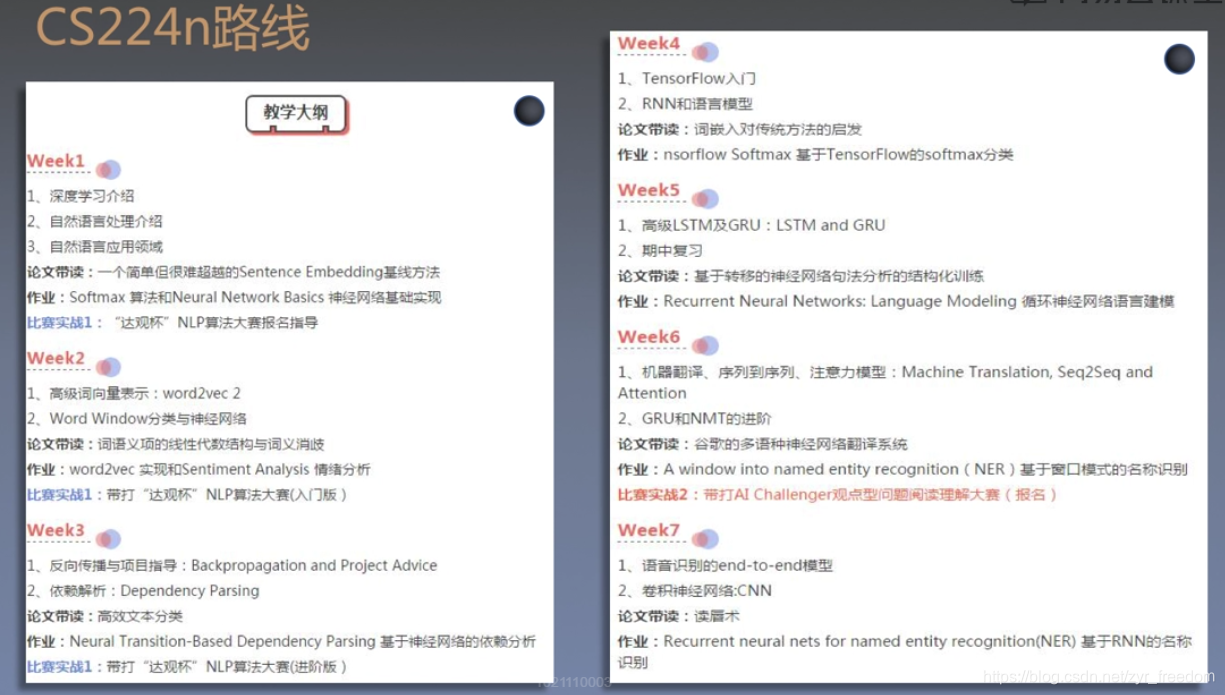
(二)、学习课表

(三)报名达观杯并做一些准备
达观公司组织的比赛,给好既定 的官方给的数据集,训练得到机器学习模型,而如何 评判模型的优劣,用的是测试集(每个样本没有label信息),用模型对测试集进行分类,然后把分类好的结果给官方进行评判
1.传统监督学习算法(西瓜书的章节有一 一对应)
(对数几率回归 / 支持向量机 / 朴素贝叶斯 / 决策树 / 集成学习等)
2.深度学习
(CNN / RNN / attention模型 )
Q:提高模型性能
(a)数据预处理
(b)特征工程 【特征做的好,质的飞跃,例子:对于一个人,脸部特征、身材特征】
(c)机器学习算法:
(d)模型集成
(e) 数据增强
报了名,然后提交了结果,代码按训练营的代码
print("开始.....................")
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
df_train = pd.read_csv('./train_set.csv')
df_test = pd.read_csv('./test_set.csv')
df_train.drop(columns = ['article','id'],inplace = True)
df_test.drop(columns = ['article'],inplace = True)
vectorizer = CountVectorizer(ngram_range = (1,2),min_df = 3,max_df = 0.9,max_features = 100000)
vectorizer.fit(df_train['word_seg'])
x_train = vectorizer.transform(df_train['word_seg'])
x_test = vectorizer.transform(df_test['word_seg'])
y_train = df_train['class'] - 1
lg = LogisticRegression(C = 4,dual = True)
lg.fit(x_train,y_train)
y_test = lg.predict(x_test)
df_test['class'] = y_test.tolist()
df_test['class'] = df_test['class'] + 1
df_result = df_test.loc[:,['id','class']]
df_result.to_csv('./result.csv',index = False)
print('完成................................')成功了,明天自己要尝试读懂并备注这段代码,自己要理解其原理所在。
安装anaconda 遇见问题:下载安装Anaconda 只出现prompt界面
原因中途弹出的小黑窗手动给关闭了。卸载后让默认要求重装一次成功啦!