注:参考资料《统计模型轻松入门-网易云课堂》张文彤
类别预测模型概述
自变量是连续的;而因变量是分类变量。
如果两个自变量,对应就是二维的;
因变量,作为分类变量,可以是两类,也可以是多类,这里,简单地,以两类为例进行分析。

上图中,横坐标对应自变量
,纵坐标对应自变量
,因变量为两类(红和蓝)的分类变量。
我们期望能够找到一条分界线,从而把两类区别开。要求分得误差(错分的比例/概率)越小越好。

- 经典判别分析模型/Logistic模型
不过,仅有尽可能小的错分概率是不够的,还要考虑错分的风险尽可能低(各自阵营的点尽可能地离分界线远),也就是,下图中五角星表示重心(可以选取平均值),使得各个重心到分界线的距离尽可能远。

在下面这种情况,可以找到抛物线作分界线。

也可以像下面这样,把二维化成一维(极坐标,圆半径),当超过某圆半径时,算作他类。

例子2:横坐标是孕妇的年龄,纵坐标是孕妇怀孕前的每月饮酒量;

- 尽可能曲线直线化
旋转坐标轴。缺点在于需要观察。
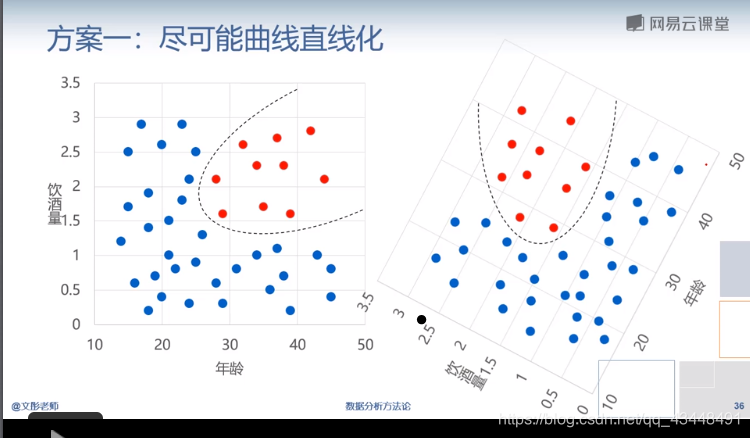
- 降维打击
经典案例:

从花萼的长、宽和花瓣的长、宽中,提取主成分,进行降维分析(4维->2维,需要原变量的线性变换)。
只是,这里降维的目的是使得类间差异最大化。

- 分类树;树模型

- 近似(用分段直线近似判别曲线),神经网络
如果点在·直线1的右侧 & 直线2的右侧 & 直线3的上侧·,那么就把它归为红。

- k近邻分析,“近朱者赤近墨者黑”
没有模型,简单;

判断第一个(靠上)黄色标记是红还是蓝,就以该点为圆心,画圆,圆内有2个红点>1个蓝点,所以认为它是红;
同样地,判断第二个黄色标记是蓝。
- 高维空间化,支持向量机(SVM)
相比于圆外的蓝点,圆内的红点 值比较小,因此乘积也比较小,作为各点对应的第三维度。

结果如下,这时,我们可以找到一个线性平面作为分界。

- 多类判别的处理方式:将问题转化成多个两类判别

首先,根据判别直线1,判断是蓝色么;
根据判别直线2 ,判断是黄色么;
根据判别直线3,判断是红色么;
分类预测模型的基本框架:

注:
神经网络的“表达困难”:参数的含义不知
“对数据缩放敏感”:缩放是指数据的离散度、测量尺度,需要作变换;
SVM,支持向量机,多用在文本词条分类;
