图的逻辑结构:多对多。
图的存储结构:
目录
图没有顺序存储结构,但可以借助二维数组来表示元素之间的关系
数组表示法(邻接矩阵):

无向图的邻接矩阵:
例:

共有5个顶点,所以形成5*5的方阵。

举个例子,比如第一行:
v1与v1本身之间无边,无邻接关系,所以为0
v1与v2之间有边,有邻接关系,所以为1
v1与v3之间无边,无邻接关系,所以为0
v1与v4之间有边,有邻接关系,所以为1
v1与v5之间无边,无邻接关系,所以为0
特点:
对角线上的元素都是0(因为对角线上都是每一个顶点到自身的边,是不存在的)
对称性:关于对角线对称(因为无向图中如果v1和v2之间有边,那v2和v1之间也有边)
由邻接矩阵可以得到:
顶点 i 的度=第 i 行(列)中1的个数
完全图的邻接矩阵中,对角线上元素为0,其余均为1
有向图的邻接矩阵:
如果是该顶点发出的到其它顶点的弧,那么它到其它顶点的值都记为1,反之记为0。
例:

举个例子,比如还是第1行:
v1没有发向v1自身的弧,所以为0
v1有发向v2的弧,所以为1
v1有发向v3的弧,所以为1
v1没有发向v4的弧,所以为0
特点:
有向图的邻接矩阵可能是不对称的
顶点的出度=第 i 行元素之和
顶点的入度=第 i 列元素之和
顶点的度=第 i 行元素之和+第 i 列元素之和
网(即有权图)的邻接矩阵:

例:
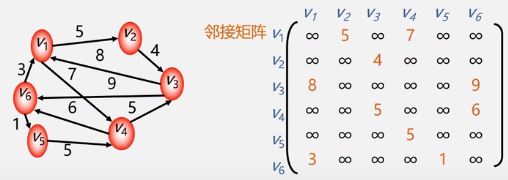
同样以第一行为例:
v1没有发向v1自身的弧,所以记为无穷
v1有发向v2的弧,且权值为5,所以记为5
v1没有发向v3的弧,所以记为无穷
v1有发向v4的弧,且权值为7,所以记为7
v1没有发向v4的弧,所以记为无穷
v1没有发向v4的弧,所以记为无穷
用邻接矩阵来建立无向网:
定义:

算法思想:

算法:



示例代码:
代码实现:
#include<iostream>
using namespace std;
#define OK 1
#define Maxint 32767//表无穷,一个很大的数
#define MVNum 100//表最大顶点数
typedef char VerTexType;//设顶点类型为字符型
typedef int ArcType;//假设边的权值类型为整型
typedef int Status;
//
typedef struct
{
VerTexType vexs[MVNum];//顶点表
ArcType arcs[MVNum][MVNum];//邻接矩阵
int vexnum,arcnum; //图的当前顶点数和边数
}AMGraph;
Status CreateUDN(AMGraph &G);//建立无向网
int LocateVex(AMGraph G,VerTexType u);//查找该字符在顶点表中的下标
int main()
{
AMGraph G;
//函数调用
CreateUDN(G);
return 0;
}
//建立无向网
Status CreateUDN(AMGraph &G)
{
cin>>G.vexnum>>G.arcnum;//输入总顶点数和总边数
int i,j,k,w;
char v1,v2;
for(i=0;i<G.vexnum;i++)
{
cin>>G.vexs[i];//输入顶点
}
for(i=0;i<G.vexnum;i++)
{
for(j=0;j<G.vexnum;j++)
{
G.arcs[i][j]=Maxint;//将邻接矩阵初始化为最大值
}
}
for(k=0;k<G.arcnum;k++)
{
cin>>v1>>v2>>w;
//查找
i=LocateVex(G,v1);
j=LocateVex(G,v2);
G.arcs[i][j]=w;
G.arcs[j][i]=G.arcs[i][j];//对称
}
cout<<"输出邻接矩阵:"<<endl;
for(i=0;i<G.vexnum;i++)
{
for(j=0;j<G.vexnum;j++)
{
cout<<G.arcs[i][j]<<" ";
}
cout<<endl;
}
}
//查找该字符在顶点表中的下标
int LocateVex(AMGraph G,VerTexType u)
{
int i;
for(i=0;i<G.vexnum;i++)
{
if(u==G.vexs[i])
return i;
}
return -1;
}运行结果:

另外还有:

邻接矩阵的时间复杂度和空间复杂度都为O(n*n)。
邻接矩阵的优缺点:
优点:

缺点:
不便于增加和删除顶点
浪费空间——存稀疏图(点很多而边很少)有大量的无效元素,但对稠密图(特别是完全图)还是很合算的
浪费时间——统计稀疏图中一共有多少条边时需要从头到尾遍历一遍
链式存储结构:
常用的表示方法有这三种:邻接表、十字链表、邻接多重表。其中重点介绍邻接表。
邻接表:

无向图的邻接表:
举例:

就比如说存放v1这个顶点的0位置,它后面的链表中第一个存储着3位置的v4,第二个存储着1位置的v2,代表着v1有两个邻接顶点v4和v2。
无向图中顶点 vi 的度为第 i 个单链表中的结点数。(如顶点v1的度为2)
特点:
邻接表不唯一(就像v1后面的链表中v2和v4的位置可变)
若无向图中有n个顶点,e条边,则其邻接表需要n个头结点和2e个表结点(就像上图一样,有v1到v4的,就一定会有v4到v1的)。适合存储稀疏图。
空间复杂度为O(n+2e)。
有向图的邻接表:
空间复杂度为O(n+e)。
举例(每一个顶点存储它的出度边):

就比如说存放v1这个顶点的0位置,它后面的链表中第一个存储着2位置的v3,第二个存储着1位置的v2,代表着v1有两条出度边分别指向v3和v2。
特点:
顶点vi的出度为第 i 个单链表中的结点个数(比如第1个单链表中的结点个数为2,所以v1的度就为2)
顶点vi的入度为整个单链表中邻接点域值是 i-1 的结点个数(如v1的入度边是v4,因为v4的链表结点中存着0位置的v1)
找出度容易,找入度难
举例(每一个顶点存储它的入度边):
逆邻接表:

特点:
顶点vi的入度为第 i 个单链表中的结点个数(比如第1个单链表中的结点个数为1,所以v1的度就为1)
顶点vi的出度为整个单链表中邻接点域值是 i-1 的结点个数(如v3的出度边是v4,因为v4的链表结点中存着2位置的v3)
找入度容易,找出度难
用邻接表来建立无向网:
定义:



算法思想:

算法说明:

算法:


邻接表的优缺点:
方便找任一顶点的所有“邻接点”
节约稀疏图的空间
需要N个头指针+2E个结点(每个结点至少2个域)
对无向图来说方便计算它的度(每一行后面所跟的结点个数即为它的度)
对有向图来说不方便计算(只能计算出度,需构造“逆邻接表”来方便计算入度)
不方便检查任意一对顶点间是否存在边
邻接矩阵与邻接表之间的关系:
联系:

区别:

十字链表:
由于在用邻接表来求有向图的度时比较困难,所以我们可以改进一下,也就是每个顶点我们不仅记录它的出度边还记录它的入度边,把邻接表和逆邻接表结合在一起,这种存储结构就叫做十字链表。
方法:
增设指针域

建立十字链表(右边的图):


邻接多重表:
由于在用邻接表来求无向图时每个边都要存储两遍,这样的话太浪费空间了,我们就可以用邻接多重表这种存储结构。
方法:


建立邻接多重表:

十字链表和邻接多重表了解一下就可以了。
