图的遍历是图的基本运算。
目录
深度优先搜索遍历
遍历
定义:
从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且每个顶点仅被访问一次,就叫做图的遍历。
遍历实质:找每个顶点的邻接点的过程。
由于图的特点是图中可能存在回路,且图的任一顶点都可能与其它顶点相通,所以在访问完某个顶点之后很可能会沿着某些边又回到曾经访问过的顶点 。
方法(避免重复访问):
设置辅助数组,用来标记每个被访问过的顶点。
《1》初始状态visited[i]为0。
《2》顶点 i 被访问,改visited[i]为1,防止被多次访问。
遍历两大方法:

深度优先搜索:
连通图的遍历:
方法:

举例:

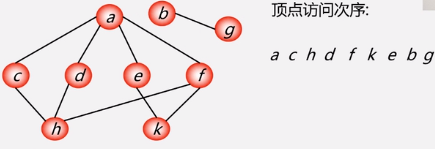
就比如说上图第一种顶点访问次序:
假如说先从v1开始,然后在它没有访问过的邻接点v2和v3中随机选择一个访问,在这里我们选择了v2,然后在v2没有访问过的邻接点v4和v5中随机选择一个访问,在这里我们选择了v4,然后访问v4的邻接点v8(没有被访问过),然后再访问v8的邻接点v5(没有被访问过),到了这里,由于v5的邻接点v2和v8都已经被访问过了,所以此时我们需要从哪里来,往哪里退,退到v8的位置,继续找没有被访问过的邻接点,发现v5没有,那就继续退,退到v4,再找v4没有被访问过的邻接点,然后再继续退,直到退到v1时,发现v1有一个邻接点v3没有被访问过,所以访问v3,然后随机访问它的邻接点v6,再访问v6的邻接点v7,到了这里,又出现了以上的情况,我们就退,直到退到v1的位置,访问结束。
非连通图的遍历:
方法:一个一个连通图进行遍历。
当我们对第一个连通图遍历完时,我们在另一个连通图中再任取一个没有访问过的顶点,再进行一样的操作,直到遍历完。
邻接矩阵上的深度优先遍历算法:
无向图的深度遍历:
举例:
最开始时将辅助数组visited[n]都初始化为0,表示所有的顶点都没有被访问过。

假设从2号顶点开始访问,所以将2号顶点的visited[2]改为1,表示2号顶点已经被访问过了。

然后从邻接矩阵中行下标为2的一行中按顺序去寻找元素1,第一个1是1号顶点,再去查找1号顶点在visited数组中为0(表示没有被访问过的邻接点),所以我们就可以访问1号顶点了,将它的visited[1]改为1

然后再从邻接矩阵中行下标为1的一行中按顺序去寻找元素1,第一个1是2号顶点,再去查找2号顶点在visited数组中为1(表示已经被访问过了),那么再继续寻找下一个元素1,第二个1是3号顶点,再去查找3号顶点在visited数组中为0(表示没有被访问过的邻接点),所以我们就可以访问3号顶点了,将它的visited[3]改为1

重复上述的过程:
访问5号顶点

到了5号顶点,我们发现,邻接矩阵中行下标为5的一行中元素为1的2号顶点和3号顶点都已经被访问过了,所以此时我们需要退回到3号顶点,也就是邻接矩阵中下标为3的那一行,继续找元素为1并且没有被访问过的,发现还是没有,再继续退,退到1号顶点,发现有元素为1并且没有被访问过的(即visit数组中该顶点存的值为0),重复之前的操作。
直到6号顶点,又出现了以上情况,那我们就退,直到退到了2号顶点(起点),发现所有顶点都已经访问过了,visit数组全都为1了,就结束了。

算法:

示例代码:
代码实现(以上面所举的例子为例):
#include<iostream>
using namespace std;
#define OK 1
#define MVNum 100//表最大顶点数
typedef char VerTexType;//设顶点类型为字符型
typedef int ArcType;//假设边的权值类型为整型
typedef int Status;
//定义
typedef struct
{
VerTexType vexs[MVNum];//顶点表
ArcType arcs[MVNum][MVNum];//邻接矩阵
int vexnum,arcnum; //图的当前顶点数和边数
}AMGraph;
Status CreateUDN(AMGraph &G);//建立无向网
int LocateVex(AMGraph G,VerTexType u);//查找该字符在顶点表中的下标
void DFS(AMGraph G,int v);//DFS遍历输出
int visited[MVNum]={0};
int main()
{
AMGraph G;
//函数调用
CreateUDN(G);
cout<<"输出DFS(遍历)结果:"<<endl;
DFS(G,2);
return 0;
}
//建立无向网
Status CreateUDN(AMGraph &G)
{
cin>>G.vexnum>>G.arcnum;//输入总顶点数和总边数
int i,j,k,w;
char v1,v2;
for(i=1;i<=G.vexnum;i++)
{
cin>>G.vexs[i];//输入顶点
}
for(i=1;i<=G.vexnum;i++)
{
for(j=1;j<=G.vexnum;j++)
{
G.arcs[i][j]=0;//将邻接矩阵初始化为最大值
}
}
for(k=1;k<=G.arcnum;k++)
{
cin>>v1>>v2>>w;
//查找
i=LocateVex(G,v1);
j=LocateVex(G,v2);
G.arcs[i][j]=w;
G.arcs[j][i]=G.arcs[i][j];//对称
}
cout<<"输出邻接矩阵:"<<endl;
for(i=1;i<=G.vexnum;i++)
{
for(j=1;j<=G.vexnum;j++)
{
cout<<G.arcs[i][j]<<" ";
}
cout<<endl;
}
}
//查找该字符在顶点表中的下标
int LocateVex(AMGraph G,VerTexType u)
{
int i;
for(i=1;i<=G.vexnum;i++)
{
if(u==G.vexs[i])
return i;
}
return -1;
}
//DFS遍历输出
void DFS(AMGraph G,int v)
{
cout<<v<<" ";
visited[v]=1;//访问第v个顶点
for(int g=1;g<=G.vexnum;g++)//邻接矩阵一行一行搜索
{
if((G.arcs[v][g]!=0)&&(!visited[g]))
{
DFS(G,g);//g是v的邻接点,如果g未访问,则递归调用DFS
}
}
}运行结果:

邻接表的深度优先遍历算法:
void DFS(ALGraph G,int v)
{
cout<<v;
visited[v]=true;
p=G.vertices[v].firstarc;
while(p!=NULL)
{
w=p->adjvex;
if(!visited[w])
{
DFS(G,w);
}
p=p->nextarc;
}
} 深度优先遍历算法分析:

广度优先搜索遍历:
方法:

假设从v1开始,依次访问它的邻接点v2和v3,然后再依次访问它邻接点的邻接点,即先从它第一个邻接点v2开始,访问v2的邻接点v4和v5,然后再访问它另一个邻接点v3的邻接点v6和v7,之后再从v4开始,访问v4的邻接点v8,最后全部访问完毕,就结束了。
邻接表的广度优先遍历:
还是先将辅助数组visited全都初始化为0

从v1开始,所以将visited[0]改为1(表示v1已被访问)

然后v1出队,然后在邻接表中v1这一行顺着链表来找它的邻接点,找到v2和v3,然后让v2,v3依次入队,访问v2和v3,修改visit数组中的值

然后v2出队,让v2的邻接点依次入队,由于0号位置的v1已被访问,所以就不用管它了,直接从3号位置的v4开始,将v4和v5依次入队,并修改visited数组的值

然后将v3出队,将它的邻接点v6和v7依次入队,重复以上的操作

将V4出队,v4的邻接点v8入队,重复以上操作

然后重复以上操作,依次访问v5,v6,v7,v8的邻接点,发现都已经被访问过了。
所有顶点都访问完了,队为空并且visited数组的值都为1,遍历就结束了。

算法:

广度优先遍历算法分析:

DFS和BFS的比较:
空间复杂度相同,都是O(n)(栈和队列最坏的情况),DFS借用了栈,BFS借用了队列
时间复杂度只与存储结构(邻接矩阵O(n*n)和邻接表O(n+e))有关,而与搜索路径无关
