这篇博客写的很全,不清楚的可以直接过去找:点击打开链接
import pandas as pd //数据分析,代码基于numpy
import numpy as np //处理数据,代码基于ndarray
import matplotlib.pyplot as plt //画图pandas主要用于数据分析,numpy库主要用于处理数据,matplotlib库主要用于画图
关键字:
读入数据:
train_df = pd.read_json("train.json")index:获取键列表
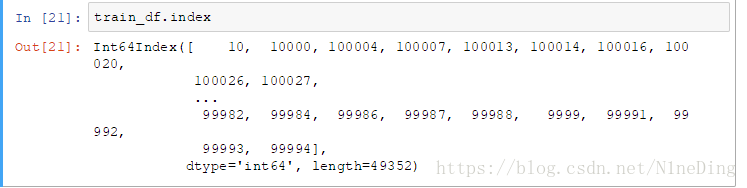
values:获取值列表

直接输入名称,可显示整个数据集:
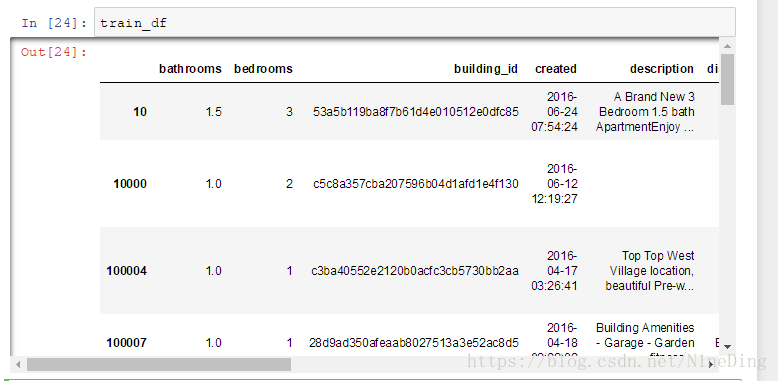
head(num),tail(num):查看头数据,不加参数默认为5,加.T为转置


columns:查看存在的所有列

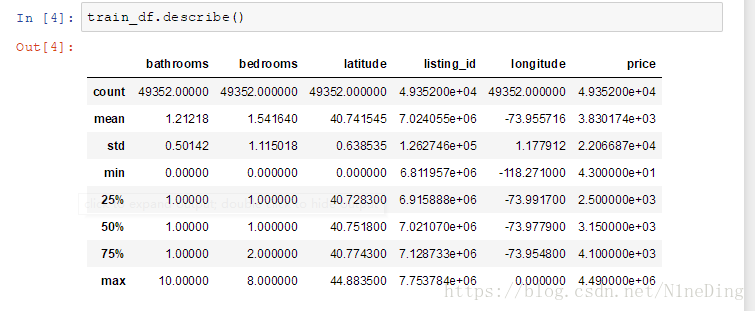
describe():输出所有列的各参数
count--计数
mean--平均值
std--标准差
min--最小值
max--最大值
25%--第一个四分位数
50%--中位数
75%--第三个四分位数
info():

.isnull().sum():可以查看数据集中是否含有缺失值
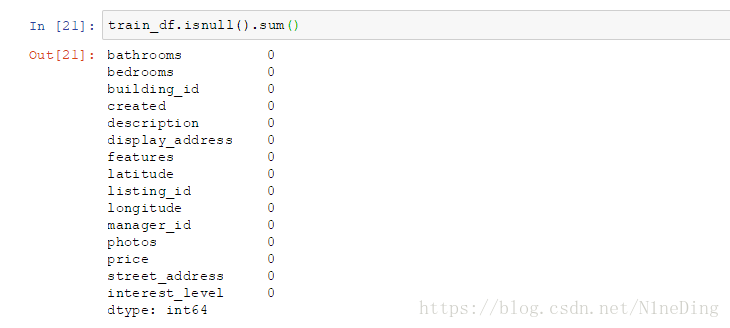
注:当然这只是一个简单的检测方式,由于数据类型的原因,部分以数组形式出的数据是无法通过这种方法检测出来,需要在后续做的时候进一步分析 。
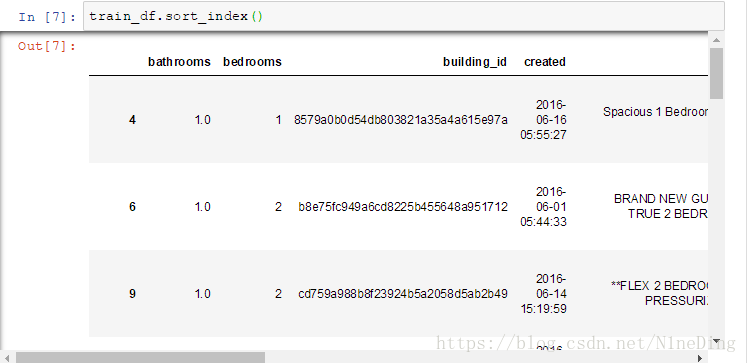
sort_index():按行索引进行排序
可以看到以行的id从小到大排序
.sort_index(ascending=False)可以用ascending=True或False来决定是正序还是倒叙
sort_index(axis=1):按列索引进行排序

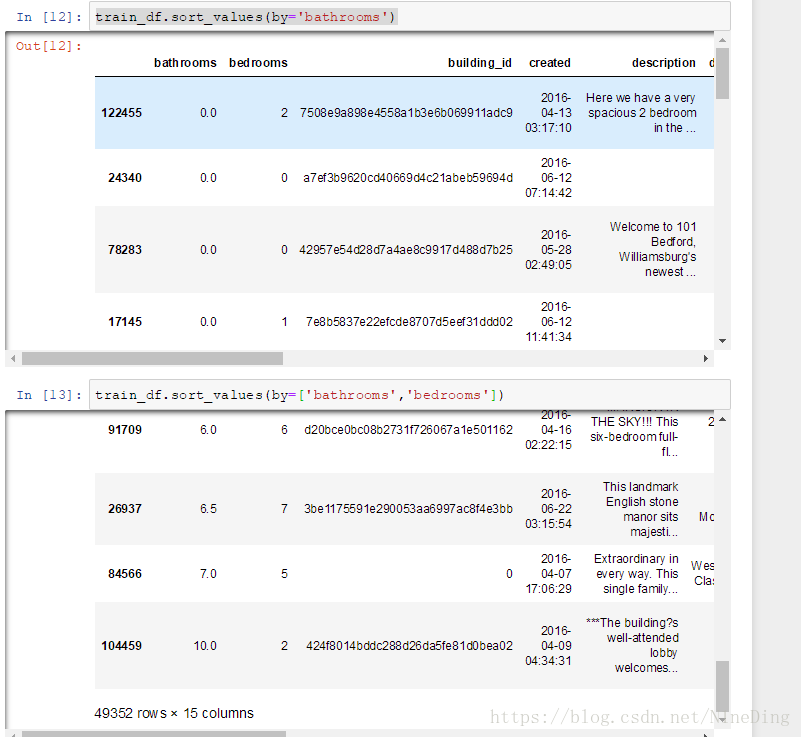
sort_values(by=''),sort_values(by=['','']:按照值的一个或多个进行排序
同样适用于sort_index
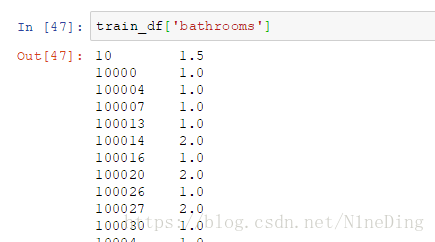
train_df['name']或train_df.name:列出某一特定列的值
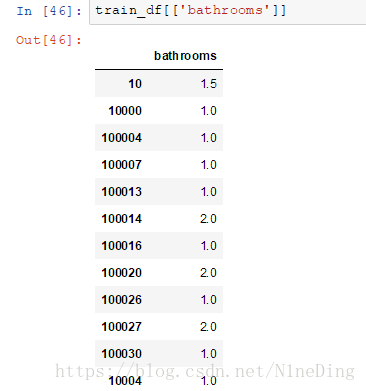
加两个中括号后:
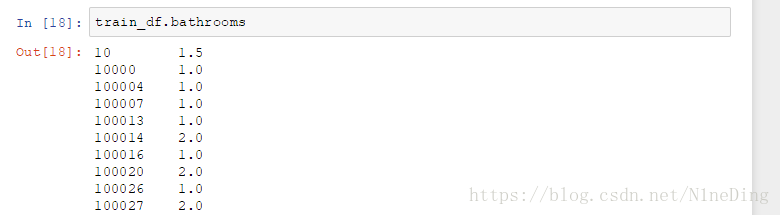
train_df[10:20]:列出范围内局部的数据
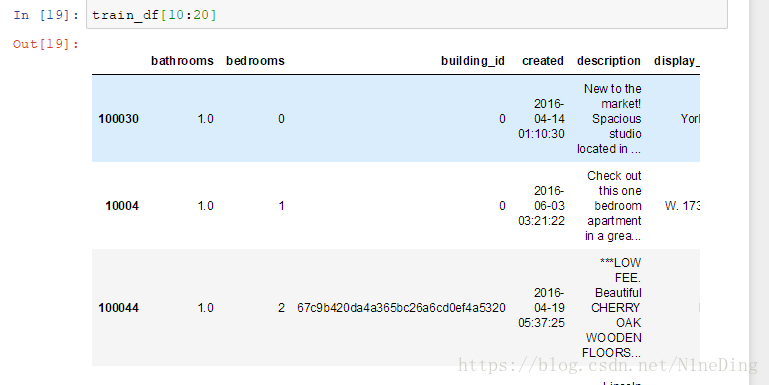
train_df.loc[ : ,[' ',' ']]:局部选择

at:选择具体某个元素
(网上的例子)

iloc[num]:从0开始,第num行(即num为3,为第四行数据)
iloc[num1:num2,num3:num4]:第num1+1行到num2行,第num3+1列到num4列
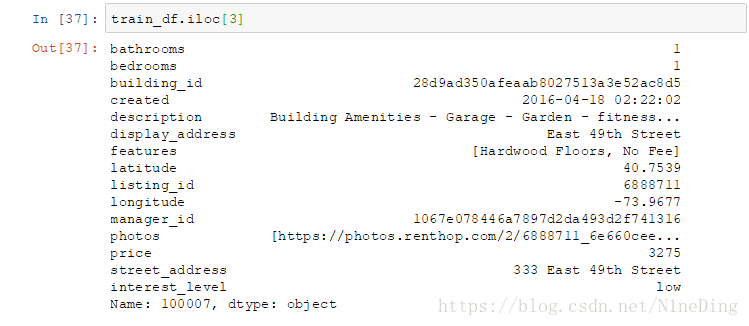

iloc剩下的几个用法对比网上例子:
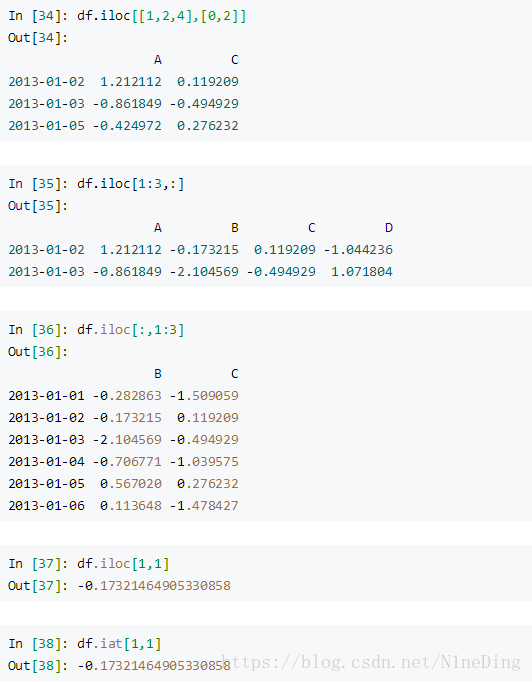
取范围内部分值:

train_df2=train_df1.copy():对train_df1的复制
isin:
参考网上例子如下:

apply:对行或列进行操作
train_df['num_photos']=train_df['photos'].apply(len)
train_df['num_features']=train_df['features'].apply(len)
train_df['num_description_words'] = train_df['description'].apply(lambda x : len(x.split(' ')))
train_df['num_description_len']=train_df['description'].apply(len)len函数返回列表元素个数,或者字符串长度
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
如下例:
add = lambda x, y : x+y
add(1,2) # 结果为3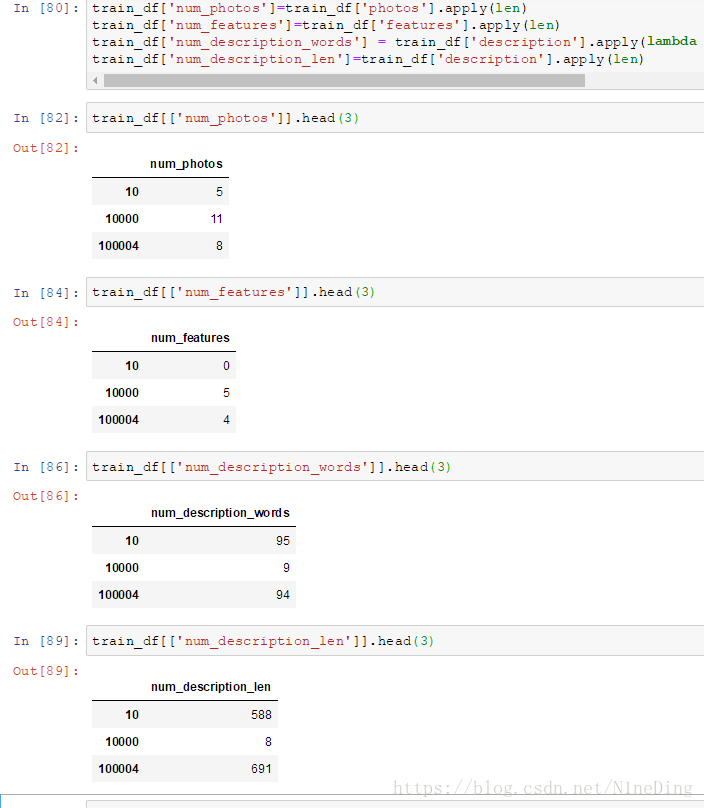
映射:
Interest_level是每条记录对应的分类结果,分别为:low,medium,high,以string形式给出,由于在模型训练中只接受数值型的数据,因此我们可以做一个映射如下:
label_num_map={'high':0,'medium':1,'low':2}
train_df['label']=train_df['interest_level'].apply(lambda x:label_num_map[x])
train_df[['label']].head()
One-hot编码,方便后续的特征提取
使用get_dummies进行one-hot编码
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合,
参数如下:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
interest_level = pd.get_dummies(train_df['interest_level'])
train_df=pd.concat([train_df,interest_level],axis=1)
train_df[['interest_level','high','low','medium']].head()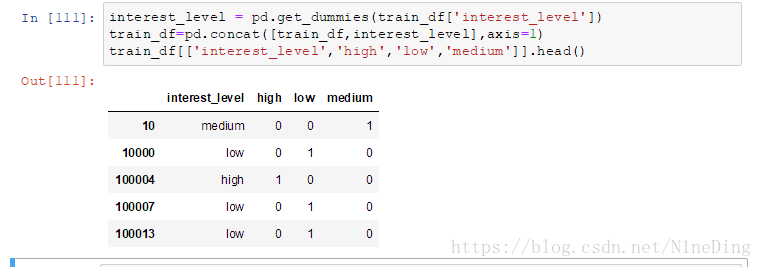
删除列:train_df.drop("medium",axis=1,inplace=True),asis=1表示删除的是一列
删除行:train_df.drop(10,axis=0,inplace=True),10表示的是将删除的id,axis=0表示删除的是一行
增加的关键字是append,可以用iloc定位然后增加。
对于时间类型的数据,我们可以获取它对应的年月日 :
train_df['created_year'] = pd.to_datetime(train_df['created']).dt.year
train_df['created_month'] = pd.to_datetime(train_df['created']).dt.month
train_df['created_day'] = pd.to_datetime(train_df['created']).dt.day
train_df[['created','created_year','created_month','created_day']].head()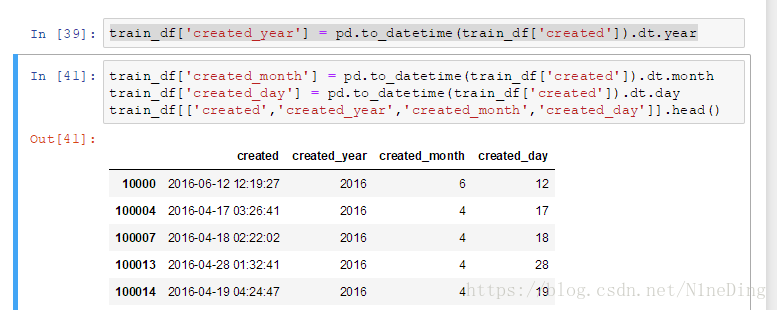
对不同卧室数目的房屋的感兴趣程度数目
和对不同卧室数目的房屋感兴趣程度(高/中/低)占对该类型房屋总数目的比:
groupby:对数据进行分组, 分组后使用sum之类的方法可以计算分组后的结果
add_suffix:将列标签前面加上后缀suffix
reset_index():将索引作为df中的一列值
bedroom_features = train_df.groupby(['bedrooms'])['high','low','medium'].sum().add_suffix('_count').reset_index()
bedroom_features['all_count'] = train_df.groupby(['bedrooms'])['price'].count()
bedroom_features['high_ratio'] = bedroom_features['high_count']/bedroom_features['all_count']
bedroom_features['medium_ratio']=bedroom_features['medium_count']/bedroom_features['all_count']
bedroom_features['low_ratio']=bedroom_features['low_count']/bedroom_features['all_count']
bedroom_features.head()
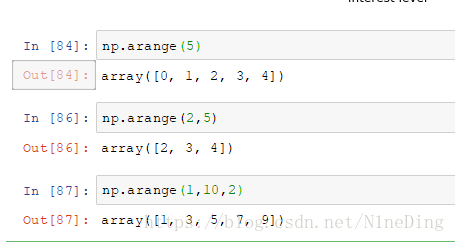
numpy库中的arange关键字:
第一个参数为起始参数,第二个为结束参数,第三个为步长。
主要参考:点击打开链接
| 将索引作为df中的一列值 |