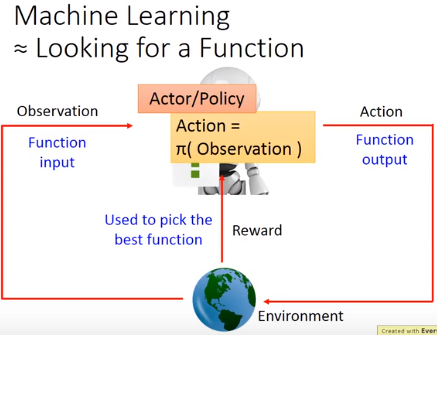
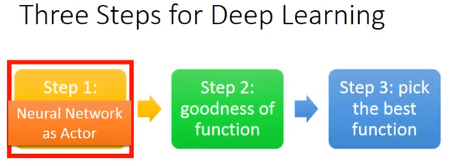
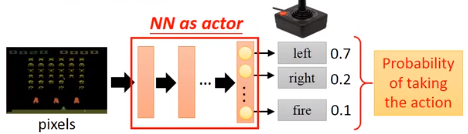
step 1:Neural Network as Actor
step 2:goodness of function(训练一些Actor)
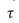 是一个序列,包含T个状态s、行为a、奖励s。代表某一次的开始到结束的过程。
是一个序列,包含T个状态s、行为a、奖励s。代表某一次的开始到结束的过程。
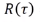 是一个奖励和。
是一个奖励和。
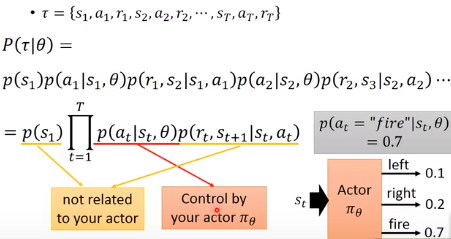
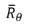 是某一设定好的参数
是某一设定好的参数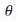 获得的总平均奖励
获得的总平均奖励
用策略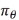 去玩N次游戏获得N个,则从概率
去玩N次游戏获得N个,则从概率 中进行采样。
中进行采样。

step 3:pick the best function(找到最好的一个Actor)
方法:Gradient Ascent
即最大化,用Gradient Ascent方法寻找使最大的




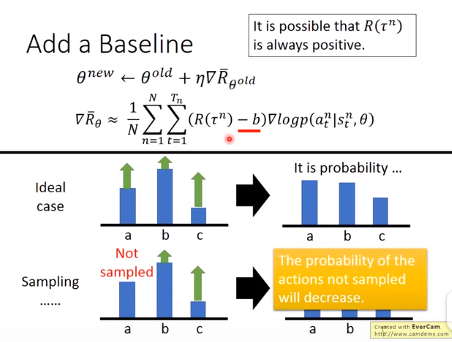
添加偏置
这里的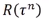 有可能总是正数,加上一个偏置b即可。
有可能总是正数,加上一个偏置b即可。
如果相减还是得到一个正数则可以提高该行为的概率,否则降低该行为的概率