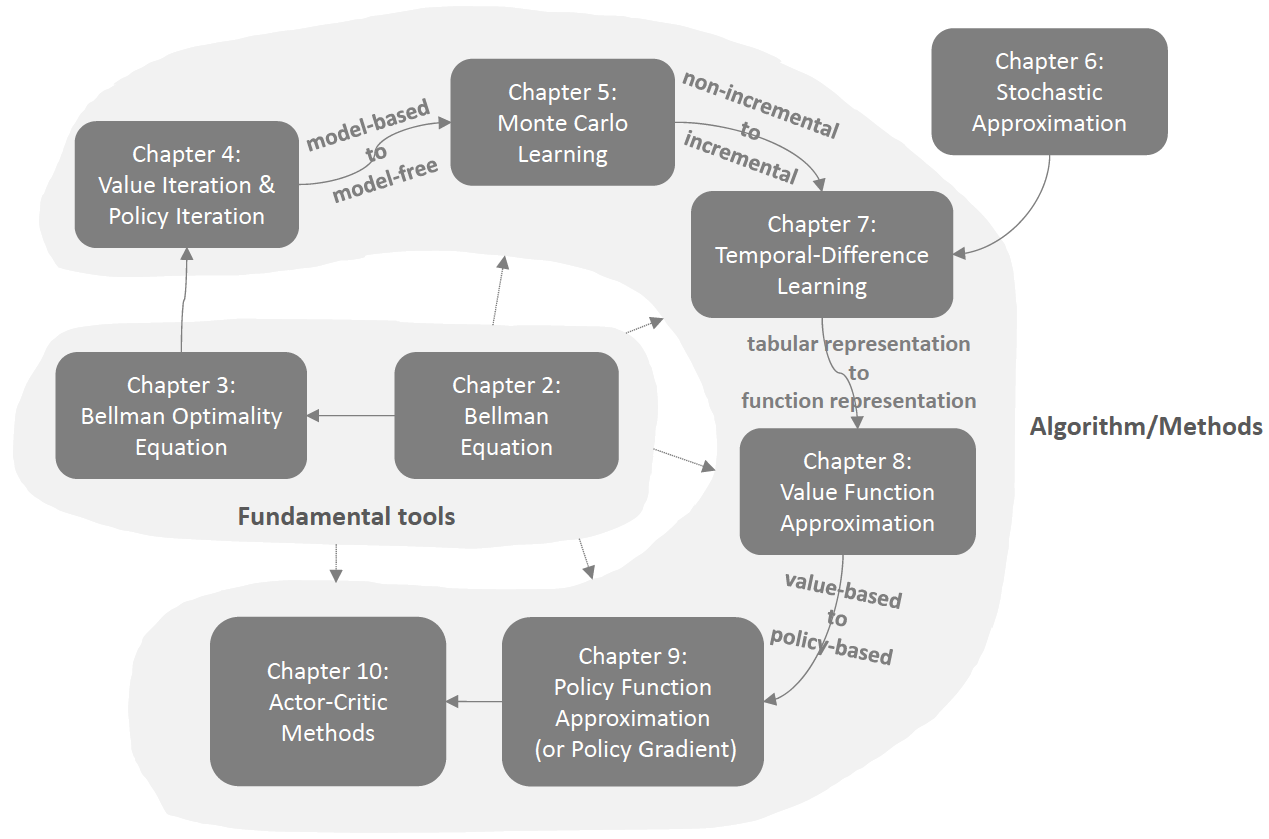

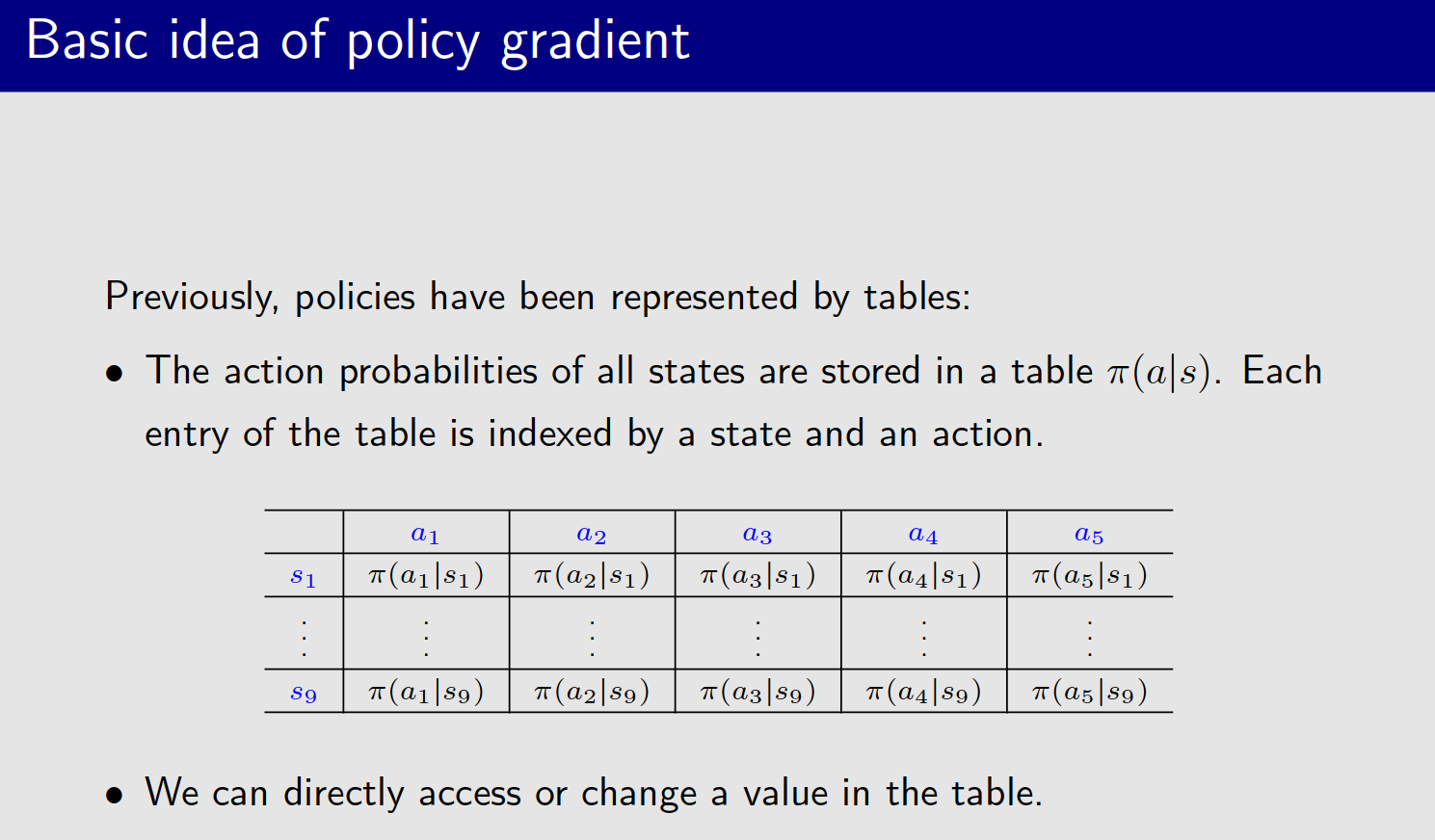
一、Basic idea of policy gradient



二、Metrics to define optimal policies
1、The average value
1.1 average state value




1.2 average one-step reward



2、Remarks



3、Excise


三、Gradients of the metrics





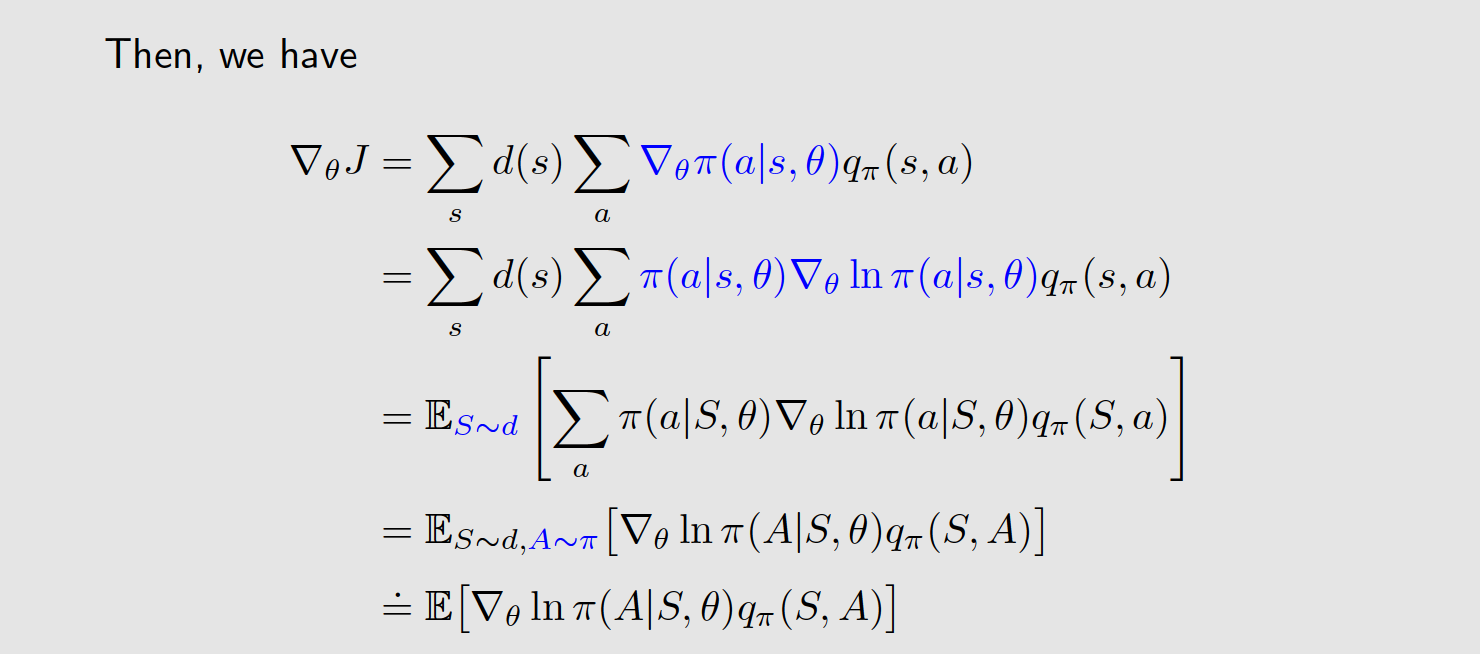


四、Gradient-ascent algorithm






1、REINFORCE algorithm


参考资料:
强化学习导论(十三)- 策略梯度法