第一次完整使用scrapy框架,通过一个简单的实例来记录一下使用框架的基本步骤,希望自己越来越熟悉这个强大框架的使用。
安装Scrapy
我这边是搭配anaconda使用的,因此直接在创建的环境(名为py36)中使用conda install scrapy即可在此工作环境下面安装好scrapy
此外,也可以直接
pip install Scrapy
入门案例
首先明确总体的步骤:
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建一个项目(scrapy startproject)
使用anaconda的话首先需要进入已经安装scrapy的环境(activate env1),然后进入自定义的项目目录中(比如说新建一个Scrapy_project文件夹存放所有的爬虫项目,再新建一个Taobao文件夹存放豆瓣网页的爬虫项目,那么就要进入\Scrapy_project\Taobao),运行下列命令:
scrapy startproject TaobaoSpider
可以在当前根目录下输入tree /F查看文件目录树,可以看到在Taobao目录下生成了TaobaoSpider这个项目的文件夹,文件夹名同项目名。
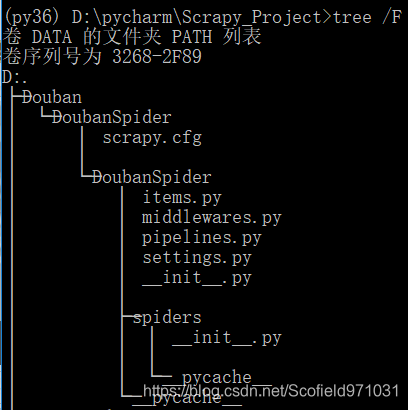
这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- TaobaoSpider/: 项目的Python模块,将会从这里引用代码。
- TaobaoSpider/items.py: 项目的目标文件。
- TaobaoSpider/pipelines.py: 项目的管道文件。
- TaobaoSpider/settings.py: 项目的设置文件。
- TaobaoSpider/spiders/: 存储爬虫代码目录。
二. 明确目标(TaobaoSpider/items.py)
我们打算抓取淘宝网上某商品关键字的商品信息:价格、商品名称、销量
Item.py文件定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护减少错误。所以说需要修改该文件将想要爬取到的字段填入该文件进行预定义即可。
打开items.py,可以发现基本结构已经生成完毕,包括导入库,类名都已经定义好,只需要按照注释所说定义好想要爬取的域字段即可,修改如下:
import scrapy
class TaobaospiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
num = scrapy.Field()
# 商品名称
name = scrapy.Field()
# 价格
price = scrapy.Field()
# 销量
sales = scrapy.Field()
pass
三. 制作爬虫 (spiders/TaobaoMovie.py)
之前说过 TaobaoSpider/spiders/是存储爬虫代码目录的文件夹,可以发现现在这个文件夹是空的,因为我们还没有开始制作一个爬虫。
1. 创建爬虫
在spiders的同一目录下输入
scrapy genspider TaobaoProduct www.taobao.com
TaobaoProduct 是爬虫名字,后面是爬取的目标域名
scrapy genspider [options] <name> <domain>
输入完毕之后,可以发现在spiders文件夹下面会自动创建一个TaobaoProduct.py文件,这个就是爬虫文件,我们需要在这文件里编辑、爬取目标数据。可以打开该文件,默认增加了以下代码:
import scrapy
class TaobaoproductSpider(scrapy.Spider):
name = "TaobaoProduct" # 爬虫名字
allowed_domains = ["www.taobao.com"]
start_urls = ['www.taobao.com']
def parse(self, response):
pass
-
name = “” :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
-
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
-
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
-
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:负责解析返回的网页数据(response.body),提取结构化数据(生成item)、生成需要下一页的URL请求。
2. 取数据
接下来我们要做的就是填充TaobaoProduct.py文件,使用相应的库(re、BeautifulSoup)来爬取所需数据。
- 首先,我们需要明白这个类之间的内在关系:parse子方法的response是对start_urls中的url的网页响应。传入参数response就是待解析的网页代码。
- 其次,当对url响应不仅仅只是简单的get时,比如网页需要模拟登录,那么就响应就需要post数据,或者加入get参数时,此时就要用到start_requests() 方法。
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。当spider启动爬取并且未指定URL时,该方法被调用。当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。该方法仅仅会被Scrapy调用一次,默认实现是使用 start_urls 的url生成Request。
恰好,淘宝网页就需要我们先模拟登录,再去爬取数据,此时如果不使用start_requests() 方法,会发现爬虫结果报错403。
- 模拟登录:我们先解决模拟登录的问题,这边我们因为发现淘宝网页的post data字段太多,并且似乎经过了加密处理,post用户名密码登录方法实现登录似乎比较麻烦,所以直接使用了基于cookie的模拟登录:将登录后的cookie复制下来,作为参数获取网页响应,这里用到了start_requests() 方法:
cookies = {}
c = '_uab_collina=151221395076409730939696; cna=476mEjlDmngCAdrFmUz2zpFC; hng=CN%7Czh-CN%7CCNY%7C156; t=bf63eaafda26ff86c76af4014fe3b509; tg=0; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; miid=7820446351806933749; lid=%E6%96%AF%E7%A7%91%E8%8F%B2%E4%BA%8C%E5%BE%B7; enc=4fo9WJlEp1W00%2F6vzoD7251gSfQcg%2Bev4Q74Kqct7rl8%2FXiHKNAM%2F6txKDZyg9c8K0thDU5IoRUkwTcv1d5Qdw%3D%3D; _umdata=6AF5B463492A874D4FF2535D5E094AE8FEBC511C9E2C38CECE0987D5E2210676A8E3549BA5C0F630CD43AD3E795C914CED09BBFF8F1CE9836FAF732B92BDE3D8; UM_distinctid=1664e12832255-02254c9411ae0f-5701732-144000-1664e128323195; thw=cn; lc=VypURZ%2BxkK2WDFmBpHzI; log=lty=Ug%3D%3D; uc3=vt3=F8dByEnZoL5dWiOVyHM%3D&id2=UUGk3bJF6X9rfg%3D%3D&nk2=qBFl9Ii6zaXunA%3D%3D&lg2=VT5L2FSpMGV7TQ%3D%3D; tracknick=%5Cu65AF%5Cu79D1%5Cu83F2%5Cu4E8C%5Cu5FB7; lgc=%5Cu65AF%5Cu79D1%5Cu83F2%5Cu4E8C%5Cu5FB7; _cc_=UtASsssmfA%3D%3D; mt=ci=29_1; v=0; uc1=cookie14=UoTZ4M4rAgkdvA%3D%3D; cookie2=1268809b458a9c1730ca8ca319cfdb0b; _tb_token_=e9787eb14b139; cookieCheck=80558; isg=BDEx7CEZyWJGF2P2D6JnwH6eQL3BmwjQYjYEzRNGLfgXOlGMW261YN9YWI756T3I; l=bBxpeERlvJpR20w2BOCanurza77OSIRYYuPzaNbMi_5Qq6T_k2QOliyMBF96Vj5RsxYB4-L8Y1J9-etkZ'
for line in c.split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, cookies=cookies)
使用这个方法之后,那么parse方法传入的参数response第一个时刻就是带上了cookie的网页响应,实现了登录。
- 填充parse方法中代码取数据:导入类初始化item对象、解析代码填入item属性字段、自动翻页
# -*- coding: utf-8 -*-
import scrapy
from ..items import TaobaospiderItem
import re
cookies = {}
c = '_uab_collina=151221395076409730939696; cna=476mEjlDmngCAdrFmUz2zpFC; hng=CN%7Czh-CN%7CCNY%7C156; t=bf63eaafda26ff86c76af4014fe3b509; tg=0; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; miid=7820446351806933749; lid=%E6%96%AF%E7%A7%91%E8%8F%B2%E4%BA%8C%E5%BE%B7; enc=4fo9WJlEp1W00%2F6vzoD7251gSfQcg%2Bev4Q74Kqct7rl8%2FXiHKNAM%2F6txKDZyg9c8K0thDU5IoRUkwTcv1d5Qdw%3D%3D; _umdata=6AF5B463492A874D4FF2535D5E094AE8FEBC511C9E2C38CECE0987D5E2210676A8E3549BA5C0F630CD43AD3E795C914CED09BBFF8F1CE9836FAF732B92BDE3D8; UM_distinctid=1664e12832255-02254c9411ae0f-5701732-144000-1664e128323195; thw=cn; lc=VypURZ%2BxkK2WDFmBpHzI; log=lty=Ug%3D%3D; uc3=vt3=F8dByEnZoL5dWiOVyHM%3D&id2=UUGk3bJF6X9rfg%3D%3D&nk2=qBFl9Ii6zaXunA%3D%3D&lg2=VT5L2FSpMGV7TQ%3D%3D; tracknick=%5Cu65AF%5Cu79D1%5Cu83F2%5Cu4E8C%5Cu5FB7; lgc=%5Cu65AF%5Cu79D1%5Cu83F2%5Cu4E8C%5Cu5FB7; _cc_=UtASsssmfA%3D%3D; mt=ci=29_1; v=0; uc1=cookie14=UoTZ4M4rAgkdvA%3D%3D; cookie2=1268809b458a9c1730ca8ca319cfdb0b; _tb_token_=e9787eb14b139; cookieCheck=80558; isg=BDEx7CEZyWJGF2P2D6JnwH6eQL3BmwjQYjYEzRNGLfgXOlGMW261YN9YWI756T3I; l=bBxpeERlvJpR20w2BOCanurza77OSIRYYuPzaNbMi_5Qq6T_k2QOliyMBF96Vj5RsxYB4-L8Y1J9-etkZ'
for line in c.split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
class TaobaoproductSpider(scrapy.Spider):
num = 0 # 序号
count = 0 # 迭代次数
name = "TaobaoProduct"
# allowed_domains = ["www.taobao.com"]
start_urls = ['https://s.taobao.com/search?q=%E4%B9%A6']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, cookies=cookies)
def parse(self, response):
item = TaobaospiderItem()
names = re.findall(r'\"raw_title\":\"(.*?)\"', response.body.decode())
prices = re.findall(r'\"view_price\":\"(.*?)\"', response.body.decode())
sales = re.findall(r'\"view_sales\":\"(.*?)\"', response.body.decode())
for i in range(len(names)):
item['name'] = names[i]
item['price'] = prices[i]
item['sales'] = sales[i]
item['num'] = self.num
self.num = self.num + 1
yield item
if self.count < 10000:
self.count = self.count + 1
next_url = self.start_urls[0] + '&s=' + str(self.count * 44)
yield scrapy.Request(next_url, cookies=cookies)
pass
这里最需要注意的是导入items.py中定义的类,from ..items import TaobaospiderItem
导入之后,初始化一个item对象,然后给对象的属性赋值
四. 配置项(settings.py/pipeline.py)
settings.py
修改重要的配置项,可以减少爬虫被目标网页发现的几率:
ROBOTSTXT_OBEY = True # 是否遵守robots.txt
CONCURRENT_REQUESTS = 16 # 开启线程数量,默认16
AUTOTHROTTLE_START_DELAY = 3 # 开始下载时限速并延迟时间 默认3
AUTOTHROTTLE_MAX_DELAY = 60 # 高并发请求时最大延迟时间 默认60
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 以上几个参数对本地缓存进行配置,如果开启本地缓存会优先读取本地缓存,从而加快爬取速度
USER_AGENT = 'projectname (+http://www.yourdomain.com)'
# 对requests的请求头进行配置,比如可以修改为‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36’同样可以避免服务器返回403
pipelines.py
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。如果仅仅想要保存item,则不需要实现的pipeline。item pipeline的一些典型应用有:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 将爬取的结果保存到数据库中或文件中
我这里只是定义了写文件的操作(这个操作其实可以通过运行爬虫使用命令加参数实现)
import json
import codecs
# import pandas as pd
class TaobaospiderPipeline(object):
def __init__(self):
self.file = codecs.open('taobao.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
五. 运行爬虫
语法:scrapy crawl <spider>
因为这里在pipelines.py文件中写了写文件的操作,因此不需要加入额外参数运行爬虫即可实现保存,同样地,可以选择scrapy crawl <spider> -o <filename>将结果保存到特定文件中。
taobao.json文件内容如下:

至此,梳理了一遍scrapy框架使用的大体步骤,实例操作时候最大的感受就是需要设置好settings.py参数,把并发数调低点,不然IP就被封掉了,要好几天才会恢复。
其中,pipelines/middlewares/settings.py的使用还需要进一步通过实验去熟悉,更复杂的项目可能就需要对这些文件进行复杂的操作了。
最后,这个实例里面基本没有用到xpath,但是xpath是非常好用简洁的,以后应该会记录基本使用方法。
