背景
最近几个月学了数据分析相关知识,到现在也算学了不少内容,接下来打算慢慢开始找工作了。本项目打算着重复习 python 相关的知识。首先用requests、BeautifulSoup、pandas库对<猎聘网>现有的数据分析招聘信息进行爬取和存储,然后利用numpy, pandas 和 matplotlib库对爬取到的数据进行数据抽取、数据清洗以及可视化呈现:
目的
主要是希望通过实际的数据来解答针对数据分析岗位的一些疑惑。具体来说,主要针对以下几个问题:
- 数据分析师岗位需求的地域性分布;
- 不同城市数据分析师的薪酬情况是怎样的;
- 该岗位对于工作经验的要求是怎样的;
数据爬取:
import requests import pandas as pd from bs4 import BeautifulSoup #在猎聘网全国范围搜索,得到100页结果,下面一行代码是这100页链接 url_list=['https://www.liepin.com/zhaopin/?init={}&imscid=R000000058&d_sfrom=search_fp_bar&key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90'.format(pages) for pages in range(0,100)] def detail(url): result=requests.get(url) #获取本页面内容 soup=BeautifulSoup(result.text,'lxml') job_info=soup.find_all('div',class_='job-info') #页面审查元素->找到所需信息的位置->通过位置获取 job = pd.DataFrame(columns=[['position', 'salary', 'city', 'edu-background', 'experience']])#需要的字段:职位、年薪、城市、教育背景、经验 job['position']=[div.h3.get('title') for div in job_info] job['salary'] = [div.p.get('title').split('_')[0] for div in job_info] job['city'] = [div.p.get('title').split('_')[1][:2] for div in job_info] job['edu-background'] = [div.p.get('title').split('_')[2] for div in job_info] job['experience'] = [div.p.get('title').split('_')[3] for div in job_info] return job job_ = pd.DataFrame(columns=[['position', 'salary', 'city', 'edu-background', 'experience']]) for i in range(0,100): job_=job_.append(detail(url_list[i])) #循环获取100页的所有需要的信息 job_.to_excel('../lagou/data0.xls') #数据保存
数据处理、可视化:
import pandas as pd import numpy as np import matplotlib.pyplot as plt #因爬取的时候确认过数据的完整性,所以就不需要再次确认了 input='../lagou/data.xls' #文件路径 data=pd.read_excel(input) #获取文件 data_city=data.groupby(by='city')['position'].count().sort_values(ascending=False) #按城市降序排列 fig=plt.figure() ax1=plt.subplot() rect=ax1.bar(np.arange(len(data_city)),data_city.values,width=0.5) def auto_xtricks(rects,xticks): #X轴刻度标签 x=[] for rect in rects: x.append(rect.get_x()+rect.get_width()/2) x=tuple(x) plt.xticks(x,xticks) def auto_tag(rects,data=None,offset=[0,0]): #数据标签 for rect in rects: try: height=rect.get_height() plt.text(rect.get_x()+rect.get_width()/2.4,1.01*height,'%s'%int(height)) except AttributeError: x=range(len(data)) y=data.values for i in range(len(x)): plt.text(x[i]+offset[0],y[i]+0.05+offset[1],y[i]) auto_tag(rect,offset=[-1,0]) auto_xtricks(rect,data_city.index) ax1.set_xticklabels(data_city.index)
plt.show()
结果如下:
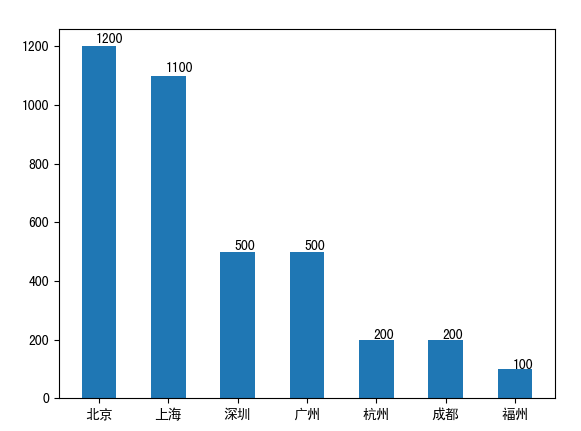
(上面图裂X轴的汉字显示需要先处理下,不然只显示两个框,详见:https://segmentfault.com/a/1190000005144275)
在猎聘网上,全国有7个城市的企业邮数据分析师的人才需求,其中1/3需求在北京市,排名第一。排名分别是:北京、上海、深圳、广州、杭州-成都、福州
结论:目前,对大数据分析的需求主要集中在北上广深,其次是杭州、成都、福州,其它城市目前的需求量较小(考虑到猎聘网上的招聘不能代表所有,所有不能说其它城市没有需求)
data1=data[data['salary']!='面议'] #去掉薪酬为面议的 data1.index=range(len(data1)) #重设索引 def avg_salary(salary): #因年薪是区间,此处处理是通过平均值得方式把区间转换成一个数 s_list=salary.split(u'万') #去掉‘万’字 s_list=s_list[0].split('-') #以‘-’为分隔符,把区间拆成两个数 s_min=int(s_list[0]) s_max=int(s_list[1]) s_avg=float(s_max+s_min)/2 #求平均值 return s_avg data1['avg_salary']=data1['salary'].apply(avg_salary)
count_by_city_salary=data1.groupby(['city'])['avg_salary'] #把薪水按城市分组 top_data_by_city=data_city df=[] for group in top_data_by_city.index: v=count_by_city_salary.get_group(group).values df.append(v) fig=plt.figure() ax3=plt.subplot() rect=ax3.boxplot(df) ax3.set_xticklabels(top_data_by_city.index) ax3.set_title(u'不同城市薪酬分布') ax3.set_ylabel(u'薪酬k/月') plt.show()
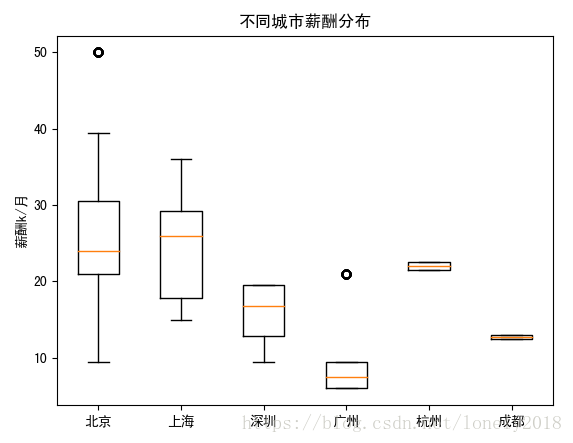
可以看出,北上深广的待遇是和城市发达程度很相关的(北-上-深-广),杭州和程度算是得意与阿里巴巴和腾讯,才会有比较高的待遇,但是需求量不多。
count_by_exp=data1.groupby(['experience'])['position'].count().sort_values(ascending=False)
print(count_by_exp.index)
fig=plt.figure()
ax4=plt.subplot()
rect=ax4.bar(range(len(count_by_exp)),count_by_exp.values,width=0.5)
ax4.set_xticklabels(['','3年以上', '2年以上', '经验不限', '1年以上', '5年以上'])
ax4.set_title(u'工作经验分布')
plt.show()

可以看出:主要需求是集中在2~3年工作经验的,无经验要求的非常少,所以对于转行或者应届生来说,入行的第一份工作还是比较难找的,所以正处在这个阶段的朋友可以不用焦虑,不是你不行,这是由市场需求决定的,多点耐心就好。
总结
对于数据分析师技能的分析是比较简陋的,在本次分析过程中,仅针对工具型的技能进行了分析。但其实,数据分析师所需要具备的素质远不止这些,还需要有扎实的数学、统计学基础,良好的数据敏感度,开拓但严谨的思维等。如果要对这些内容进行深入挖掘的话,应该会更加有趣。不过,需要掌握大量中文分词、关键字提取等方面的知识和技能,难度也会更高。时间所限,在这里不再进一步展开了。