此集群三个节点基于三台虚拟机(hadoop01、hadoop02、hadoop03)进行搭建,虚拟机安装的操作系统为Centos6.5,Hadoop版本选取为2.9.1。
实验过程
1、基础集群的搭建
下载并安装VMware WorkStation Pro,链接:https://pan.baidu.com/s/1rA30rE9Px5tDJkWSrghlZg 密码:dydq
下载CentOS镜像或者Ubuntu镜像都可,可以去官网下载,我这里使用的Centos6.5。
使用VMware安装linux系统,制作三台虚拟机。
2、集群配置
设置主机名:
vi /etc/sysconfig/network 修改内容:
HOSTNAME=hadoop01
三台虚拟机主机名分别为:hadoop01、hadoop02、hadoop03
修改hosts文件:
vi /etc/hosts内容:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.216.15 www.hadoop01.com hadoop01
192.168.216.16 www.hadoop02.com hadoop02
192.168.216.17 www.hadoop03.com hadoop03
注意:三台虚拟机都做此操作
网络环境配置:
vi /etc/sysconfig/network-scripts/ifcfg-eth0示例内容:
DEVICE=eth0
HWADDR=00:0C:29:0F:84:86
TYPE=Ethernet
UUID=70d880d5-6852-4c85-a1c9-2491c4c1ac11
ONBOOT=yes
IPADDR=192.168.216.111
PREFIX=24
GATEWAY=192.168.216.2
DNS1=8.8.8.8
DNS2=114.114.114.114
NM_CONTROLLED=yes
BOOTPROTO=static
DEFROUTE=yes
NAME="System eth0"
hadoop01:192.168.216.15
hadoop02:192.168.216.16
hadoop03:192.168.216.17
设置完后,可以通过ping进行网络测试
注意事项:通过虚拟机文件复制,可能会产生网卡MAC地址重复的问题,需要在VMware网卡设置中重新生成MAC,在虚拟机复制后需要更改内网网卡的IP。
安装jdk:
下载jdk,链接:
解压:
tar zxvf jdk-8u181-linux-x64.tar.gz -C /usr/local配置环境变量:
vi /etc/profile内容为:
export JAVA_HOME=/usr/local/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin:使之生效:
source /etc/profile设置免密登陆:
免密登陆,效果也就是在hadoop01上,通过 ssh登陆到对方计算机上时不用输入密码。(注:若没有安装ssh,先进行安装ssh)
首先在hadoop01 上进行如下操作:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys然后:hadoop01 ---> hadoop02
ssh-copy-id hadoop02然后:hadoop01 ---> hadoop03
ssh-copy-id hadoop03说明:
hadoop01给hadoop02发出请求信息,hadoop02接到去authorithd_keys找对应的ip和用户名,能找到则用其对应公钥加密一个随机字符串(找不到则输入密码),然后将加密的随机字符串返回给hadoop01,hadoop01接到加密后的字符然后用自己的私钥解密,然后再发给HAdoop02,hadoop02判断和加密之前的是否一样,一样则通过登录,不一样则拒绝。
如果需要对其他做免密操作,同理。
3、Hadoop安装配置
安装前三台节点都需要需要关闭防火墙:
service iptables stop : 停止防火墙
chkconfig iptables off :开机不加载防火墙Hadoop安装
首先在hadoop01节点进行hadoop安装配置,之后在hadoop02和hadoop03进行同样的操作,我们可以复制hadoop文件至hadoop02和hadoop03上:scp -r /usr/local/hadoop-2.9.1 hadoop02:/usr/local/
下载Hadoop压缩包,下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.1/hadoop-2.9.1.tar.gz
(1)解压并配置环境变量
tar -zxvf /home/hadoop-2.9.1.tar.gz -C /usr/local/vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.9.1/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
source /etc/profile : 使环境变量生效
hadoop version : 检测hadoop版本信息
[root@hadoop01 hadoop-2.9.1]# source /etc/profile
[root@hadoop01 hadoop-2.9.1]# hadoop version
Hadoop 2.9.1
Subversion https://github.com/apache/hadoop.git -r e30710aea4e6e55e69372929106cf119af06fd0e
Compiled by root on 2018-04-16T09:33Z
Compiled with protoc 2.5.0
From source with checksum 7d6d2b655115c6cc336d662cc2b919bd
This command was run using /usr/local/hadoop-2.9.1/share/hadoop/common/hadoop-common-2.9.1.jar此时环境变量配置成功。
(2)配置配置文件(注意,此时的操作是在hadoop解压目录下完成的)
[root@hadoop03 hadoop-2.9.1]# pwd
/usr/local/hadoop-2.9.1vi ./etc/hadoop/hadoop-env.sh :指定JAVA_HOME的路径
修改:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64vi ./etc/hadoop/core-site.xml : 配置核心配置文件
<configuration>
<!--指定hdfs文件系统的默认名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!--指定io的buffer大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定hadoop的临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/tmp</value>
</property>
</configuration>vi ./etc/hadoop/hdfs-site.xml
<configuration>
<!--指定块的副本数,默认是3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定数据块的大小-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!--指定namenode的元数据目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopdata/dfs/name</value>
</property>
<!--指定datanode存储数据目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopdata/dfs/data</value>
</property>
<!--指定secondarynamenode的检测点目录-->
<property>
<name>fs.checkpoint.dir</name>
<value>/home/hadoopdata/dfs/checkpoint/cname</value>
</property>
<!--edit的数据存储目录-->
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/home/hadoopdata/dfs/checkpoint/edit</value>
</property>
<!--指定namenode的webui监控端口-->
<property>
<name>dfs.http.address</name>
<value>hadoop01:50070</value>
</property>
<!--指定secondarynamenode的webui监控端口-->
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop02:50090</value>
</property>
<!--是否开启webhdfs的-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否开启hdfs的权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
cp ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
vi ./etc/hadoop/mapred-site.xml
<configuration>
<!--配置mapreduce的框架名称-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!--指定jobhistoryserver的内部通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop03:10020</value>
</property>
<!--指定jobhistoryserver的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop03:19888</value>
</property>
</configuration>vi ./etc/hadoop/yarn-site.xml
<configuration>
<!--指定resourcemanager的启动服务器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!--指定mapreduce的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定rm的内部通信地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop02:8032</value>
</property>
<!--指定rm的scheduler内部通信地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop02:8030</value>
</property>
<!--指定rm的resource-tracker内部通信地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop02:8031</value>
</property>
<!--指定rm的admin内部通信地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop02:8033</value>
</property>
<!--指定rm的web访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop02:8088</value>
</property>
</configuration>vi ./etc/hadoop/slaves
hadoop01
hadoop02
hadoop03这里,我们可以使用scp工具吧hadoop文件夹复制到hadoop02、hadoop03上,这样就不需要重复配置这些文件了。
命令:
复制hadoop文件至hadoop02和hadoop03上:
scp -r /usr/local/hadoop-2.9.1 hadoop03:/usr/local/
scp -r /usr/local/hadoop-2.9.1 hadoop03:/usr/local/4、启动Hadoop
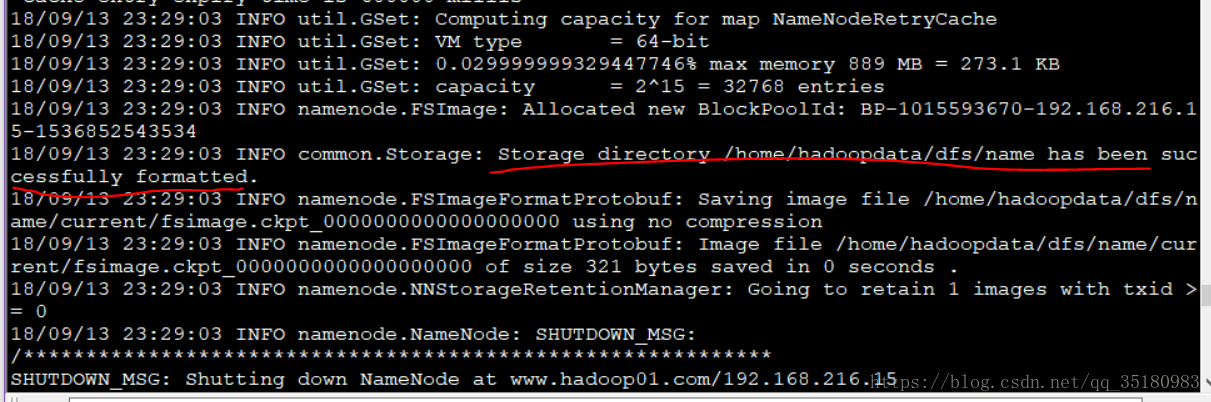
在hadoop01格式化namenode
bin/hdfs namenode -format出现:INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
则初始化成功。
启动hadoop:
start-all.sh[root@hadoop01 hadoop-2.9.1]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
18/09/13 23:29:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop01]
hadoop01: starting namenode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-namenode-hadoop01.out
hadoop03: starting datanode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-datanode-hadoop03.out
hadoop01: starting datanode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-datanode-hadoop01.out
hadoop02: starting datanode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-datanode-hadoop02.out
Starting secondary namenodes [hadoop02]
hadoop02: starting secondarynamenode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-secondarynamenode-hadoop02.out
18/09/13 23:29:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.9.1/logs/yarn-root-resourcemanager-hadoop01.out
hadoop03: nodemanager running as process 61198. Stop it first.
hadoop01: starting nodemanager, logging to /usr/local/hadoop-2.9.1/logs/yarn-root-nodemanager-hadoop01.out
hadoop02: starting nodemanager, logging to /usr/local/hadoop-2.9.1/logs/yarn-root-nodemanager-hadoop02.out
这里的一个警告可以忽略,如果想解决,可以查看我之前帖子。
查看是否正常启动:
hadoop01:
[root@hadoop01 hadoop-2.9.1]# jps
36432 Jps
35832 DataNode
36250 NodeManager
35676 NameNodehadoop02
[root@hadoop02 hadoop-2.9.1]# jps
54083 SecondaryNameNode
53987 DataNode
57031 Jps
49338 ResourceManager
54187 NodeManagerhadoop03
[root@hadoop03 hadoop-2.9.1]# jps
63570 Jps
63448 DataNode
61198 NodeManager一切正常。
这里,我们在hadoop03启动JobHistoryServer
[root@hadoop03 hadoop-2.9.1]# mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/hadoop-2.9.1/logs/mapred-root-historyserver-hadoop03.out
[root@hadoop03 hadoop-2.9.1]# jps
63448 DataNode
63771 Jps
63724 JobHistoryServer
61198 NodeManagerWeb浏览器查看一下:
- http://hadoop01:50070 namenode的web
- http://hadoop02:50090 secondarynamenode的web
- http://hadoop02:8088 resourcemanager的web
- http://hadoop03:19888 jobhistroyserver的web
验证一下:
- namenode的web

- secondarynamenode的web
- resourcemanager的web
- jobhistroyserver的web

OK!!!
7、Hadoop集群测试
目的:验证当前hadoop集群正确安装配置
本次测试用例为利用MapReduce实现wordcount程序
生成文件helloworld:
echo "Hello world Hello hadoop" > ./helloworld 将文件helloworld上传至hdfs:
hdfs dfs -put /home/words/helloworld /查看一下:
[root@hadoop01 words]# hdfs dfs -ls /
18/09/13 23:49:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 3 root supergroup 26 2018-09-13 23:46 /helloworld
drwxr-xr-x - root supergroup 0 2018-09-13 23:41 /input
drwxrwx--- - root supergroup 0 2018-09-13 23:36 /tmp
[root@hadoop01 words]# hdfs dfs -cat /helloworld
18/09/13 23:50:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hello world Hello hadoop执行wordcount程序,
[root@hadoop01 words]# yarn jar /usr/local/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /helloworld/ /out/00000出现如下内容,则OK
Virtual memory (bytes) snapshot=4240179200
Total committed heap usage (bytes)=287309824
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=26
File Output Format Counters
Bytes Written=25查看生成下的文件:
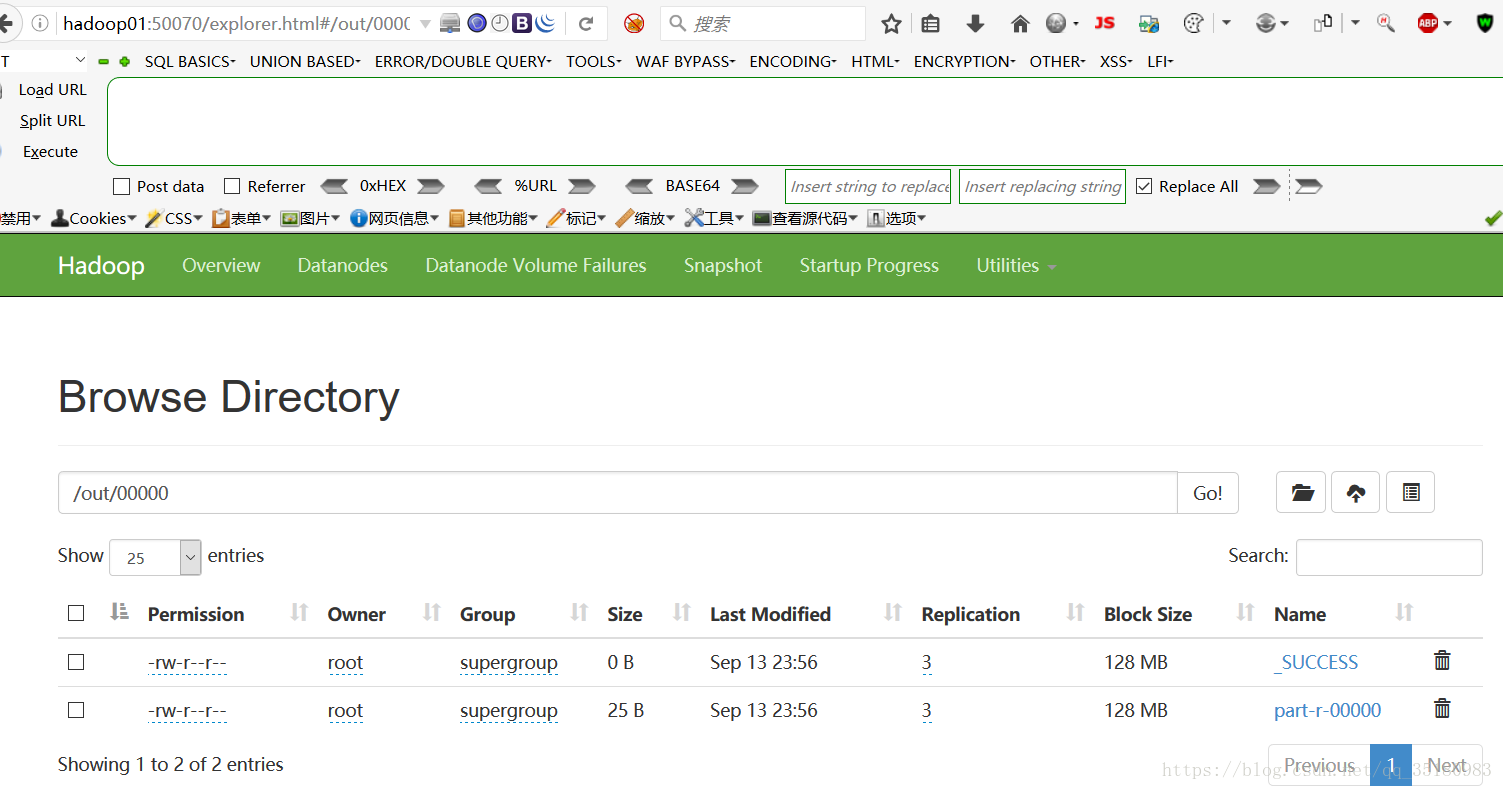
代码查看:
[root@hadoop01 words]# hdfs dfs -cat /out/00000/part-r-00000
18/09/14 00:32:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hello 2
hadoop 1
world 1结果正确。

此时我们就可以在jobHistory看到此任务的一些执行信息,当然,还有很多信息,不一一说了。晚上00:37了,睡觉。。。。
竟然维护。。。。。。。。。。。。。。
详细信息可查看官网文档