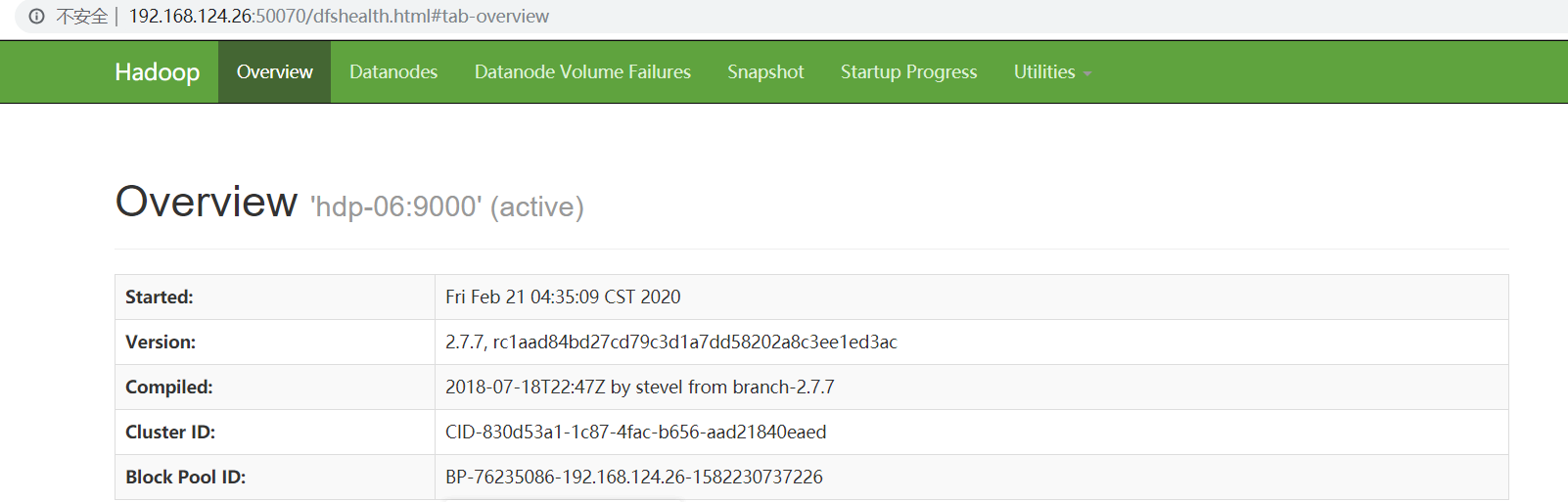
一、namenode节点各参数

二、Hadoop sbin指令
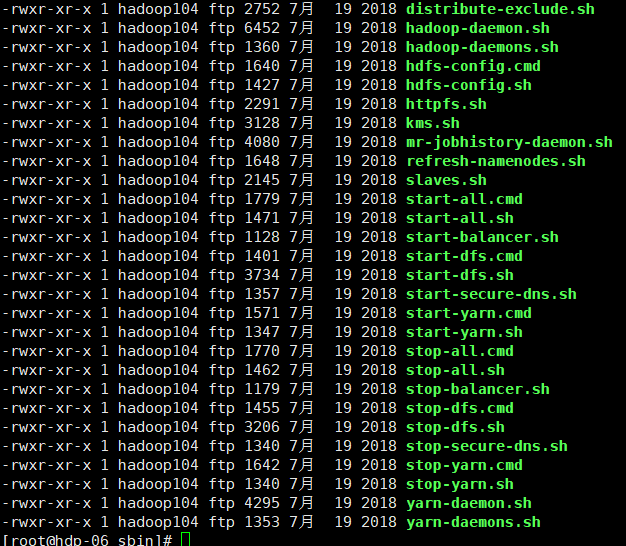
1.hadoop-daemon.sh //启动或关闭一个应用 hadoop-daemon start namenode hadoop-daemon start datanode hadoop-daemon start secondarynamenode hadoop-daemon stop namenode hadoop-daemon stop datanode 2.start-all.sh //启动dfs和yarn两个组件(五个应用) dfs:namenode,datanode,secondaryname yarn:resourcemanager,nodemanager 3.stop-all.sh //关闭dfs和yarn两个组件 4.start-dfs.sh //启动dfs组件 5.stop-dfs.sh //关闭dfs组件 6.start-yarn.sh //启动yarn组件 7.stop-yarn.sh //关闭yarn组件 8.yarn-daemon.sh //启动或关闭yarn组件的单个应用 yarn-daemon start resourcemanager yarn-daemon start nodemanager
三、完全分布式部署
1.先完成伪分布式部署
2.克隆一台机器,修改IP地址(vim /etc/sysconfig/network-scripts/ifcfg-ens33)、uuid、主机名(vim /etc/hostname)
3.修改两台虚拟机的IP地址映射 vim /etc/hosts

4.修改hdfs-site.xml 将副本数设置为3
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
5.修改 etc/hadoop/slaves 添加新的节点,作为datanode
6.删除两台机器的 tmp/dfs/目录下的文件

7.配置免密登陆
ssh-keygen //生成公钥和私钥 ssh-copy-id 主机名 //传递公钥,实现免密登陆
ssh 主机名 //测试免密登陆是否成功
8.在namenode节点上初始化
hadoop namenode -format
9.启动节点
start-dfs.sh
start-yarn.sh
9.测试 jps查看节点的启动状况;web端验证
namenode节点
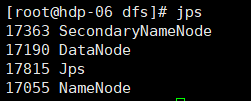
datanode节点

web端查看