下面的简单阐述自己对频率派和贝叶斯派的一些认识,不一定正确。
机器学习一直有两个派别:频率派和贝叶斯派。频率派发展成统计机器学习,贝叶斯派发展成概率图模型。
频率派认为模型的参数θ是一个未知的常量,数据X是随机变量,关心的是数据,需要把参数θ估计出来,常用的方法就是极大似然估计。
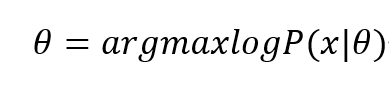
贝叶斯派认为θ是一个随机变量,服从一个概率分布θ~p(θ),称之为先验概率。通过贝叶斯定理把参数的先验和后验以及似然联系起来。
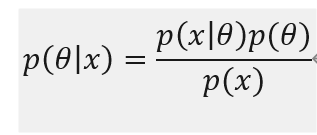
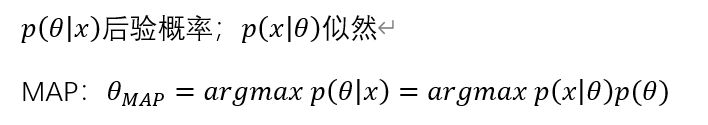
正则化的极⼤似然⽅法可以看成MAP(maximum posterior)⽅法,其中正则化项可以被 看成先验参数分布的对数。 比如从贝叶斯角度岭回归,正则化的最小二乘法等价于先验概率和噪声是高斯分布的MAP。
线性回归的损失函数均方差其实是从频率派的角度出发,就是极大似然估计。所以像深度学习中的损失函数可以理解为频率派的极大似然估计。像概率图模型其实没有损失函数,因为它是生成模型。
扫描二维码关注公众号,回复:
9417572 查看本文章

