最近的大学生活就像是一个稳稳的循环,它就在那一直转来转去,出口条件貌似已经被赋值为1了,我有点南~~~(つまらない! )。但多多少少还是有点收获的,就像是那个自增条件,虽食之无味,但弃之可惜,愿积水成渊,有蛟龙生焉。(废话莫多说,言归且正传)。
在学习完分支和循环结构之后,就接触了比较重要的函数和数组这两块。同时在老师的讲解后,我深刻的认识到了,编程并不只是活用语言,对计算机这一物体深入了解才是应有之道。
人生若只如初见!
函数
在函数部分,比较重要的有函数的传参和函数的调用这两块。
函数传参:
函数传参有传值传参和传址传参两种方式。**
int exchange1(int a, int b)
{
a = a^b;
b = a^b;
a = a^b;
printf("exchange1内 :a=%d b=%d\n", a, b);
}
int exchange2( int*p,int*q)
{
*p = *p^*q;
*q = *p^*q;
*p = *p^*q;
printf("exchange2内 ;a=%d b=%d\n", *p, *q);
}
void main()
{
int a = 3, b = 6;
exchange1(a, b);
printf("exchange1外 :a=%d b=%d\n", a, b);
exchange2(&a, &b);
printf("exchange2外 :a=%d b=%d\n", a, b);
system("pause");
}
其中exchange1()函数中传参是a,b两个实参。exchange2()函数中是a,b两个实参的地址。暨分别对应两种传参方式。在函数调用过程中,在被调函数内的结果和在main函数中的结果我们都将其打印出来就有一下结果。
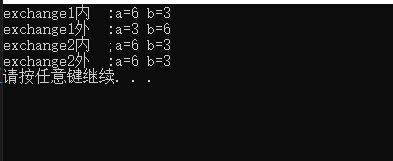
由此可见,在实现两数交换的这种操作需求下传址传参可以改变实参的值,而传值传参不能改变实参的值。同时注意到在exchange1内 a和b是在被调函数中完成了交换的。(这一点接下来说)。
这是传值传参和传址传参两种方法的区别。在实际操作中还是需要根据自己的操作需求来选择到底使用哪一种传参方式。两种方式的优缺点如下。
传值传参;缺点,不能通过形参的改变来改变外部实参
优点:与传址传参的缺陷相对。
传址传参(指针)(注:在传入数组地址时,数组会发生降维问题。小生还尚未学习到哪里,所以这一点希望读者能去参考其他大佬的博客学习一下。(我与其看了没搞懂就写,还不如不写,免得误导人 ))
** 优点**:可以通过形参的改变来改变外部实参。
缺陷:1.代码的可读性比较差。
2.代码的安全性比较低(指针在传参是一定要判空---->NULL)
3.可能会通过形参影响外部
函数调用:
函数调用有链式调用和嵌套调用两种 。其中嵌套调用中有一种特别的调用方式暨递归调用。
int max_(int a,int b)
{
return a > b ? a : b;
}
void MAX(int a, int b,int c,int d)
{
int x = max_(a, b);
int y = max_(c, d);
int z = max_(x, y);
printf("MAX=%d\n", z);
}
void main()
{
int a = 9, b = 6, c = 3, d = 12;
printf("max_(a, max_(b, max_(c, d)))=%d\n", max_(a, max_(b, max_(c, d))));
MAX(a, b, c, d);
system("pause");
}
其中main()函数中调用了2个函数,分别是max_()和MAX()函数。
printf("max_(a, max_(b, max_(c, d)))=%d\n", max_(a, max_(b, max_(c, d))));
这一段中的被打印部分为max_函数为链式调用(把一个函数的返回值作为另外一个函数的参数即为链式调用(或许用链式访问这个词更好))。
而MAX函数中调用了max_函数。这种类似于A函数中使用B函数的方法叫做嵌套调用。与嵌套循环一个道理。
至于递归。则是函数A继续调用函数A。只到抵达出口条件。
使用递归调用有两大前提
1.问题规模不断缩小化,缩小后还是相同的解决方法。2.能找到出口条件。缺一不可。如果问题规模不能缩小,或者缩小后解决方法改变,那么递归的使用就是毫无意义的。如果没有明确的出口条件,则函数可能会一直递归下去,造成死递归的现象,(卡的爆炸,电脑上天 !)。
递归不是万能的,没有递归是万万不能的!
为什么呢?首先,递归不是万能的,递归方法实际上体现了“以此类推”、“用同样的步骤重复”这样的思想,它可以用简单的程序来解决某些复杂的计算问题,但是运算量较大。在非此类问题的解决方法上,一般都是使用迭代方法,迭代方法速度快,且内存占用较少,所需时间少(为什么?)。但是,没有递归是万万不能的。在如汉诺塔这种重复性高,解决逻辑相同的问题上,使用递归可以有效地解决程序员的思考时间,减少代码书写的时间。(能写几行的我绝对不写几百行233 )。
消耗空间和时间的原因。
每一次函数调用,都需要在内存空间的栈上开辟空间,以执行被调函数和存放临时变量。背调函数一旦执行完,才会释放该处空间,同时处于该空间内的临时变量等临时数据都会被释放(前文中max_()函数中ab交换成功而函数执行完毕后ab并没有完成交换的原因所在)。
同时在每一次开辟空间和释放空间时,都会有时间的消耗。所以函数调用是具有时间成本和空间成本的。
在非递归调用的其他函数调用中。背调函数一旦执行完,释放空间,完成调用。哪怕是多次的嵌套调用也不会消耗太多的时空成本。但是递归调用一旦问题规模较大,或者规模缩小的较小时,就需要通过增加递归次数来靠近出口条件。
次数一多,时空成本一旦累计起来。就会很显眼,造成明显的延迟和卡顿。
先入后出,栈区原理(才疏学浅,个人现阶段看法)
上文提到,在函数调用是会在内存空间的栈上开辟空间。那么递归在栈上是如何运作的呢?

因为函数是先调用,运行完毕后再释放的。而上图这个递归在return语句中 return的后半句有调用,所以,在第一次调用时,运行return时会先执行text(a-1)这个函数,从而实现函数调用。但是这个时候text(a)函数并没有运行完毕,他的空间还存在,同理一次类推,只有当最后一个函数既text(1)执行完毕时,返回return1后再一次进入到text(2)这时,text(2)才算执行完毕,释放空间后再次向上返回一个值,完成后text(3)才算是运行完毕,重复以往的网上实行这个过程,只有当所有的调用全部完毕后,最初的调用text(a)才能完成。既递归的第一次调用是最早产生的,也同时是最迟消失的。我们将这两个过程称为入栈和出栈。从时间角度上来说,递归的从栈上来看就是——先入栈者后出栈,后入栈者先出栈。
(本人学习尚且不是很深入,可能会有错误,若有用处,自然最好,若无用处,愿博君一笑)
数组
这里住要是从一维数组入手推广到多维数组。
众所周知,数组是具有相同数据类型的元素组合。数组的定义和初始化,是现在内从空间上开辟出一段连续的内存空间,然后载按照数据类型将其划分。由此可见一维数组的内存地址时连续的 。

如图所示。
那么二维数组的地址时什么情况呢。

那么三维数组呢

以此类推,多维数组在内存空间上也是连续的。
其次,再仔细观察,会发现,所有的地址也都是递增的。
所以得出结论,所有的数组,无论是几维的,在内存空间上他的每一个元素的地址都是连续且递增的(**连续并不是完完全全的连续,而是相差一个数据类型大小的字节 **)
再次推导,二维数组可以看成是元素为一维数组的一个数组,三维数组为元素为二维数组的一个数组,四位数组为元素是三维数组的一维数组,既n维数组可以看成元素是n-1维数组的一维数组。
他们都具备上述结论的特征,既数组元素在内存空间上是连续且递增的。
学习进度差不多就到这里了,周末抽点时间总结了一下,可能有不对的地方,希望能被大佬们指正。个人感觉最大的收获就是,学习计算机,还是要深一步,进一步的思考,要多想为什么。语言知识工具,搞懂原理,弄清本质。才会在知识的更新换代后能更快的适应。毕竟,计算机他只是一个计算机,但是,计算机他毕竟还是一个计算机。
愿人生不只如初见!
