FastAI github:https://github.com/fastai/fastai/tree/master/courses
Video:https://www.bilibili.com/video/av18904696
Lesson1
11:15
conda env update
42:40
Image Classification可用于围棋AI中,给定一个棋盘的布局(图像),判断该布局是否能赢
43:30
在反欺诈任务中,将用户鼠标移动的轨迹画出来,对该图像进行分类
59:15
一个在线展示图像卷积效果的网站:http://setosa.io/ev/image-kernels/
73:00
选择learning rate的论文:Cyclical Learning Rates for Training Neural Networks, WACV2017
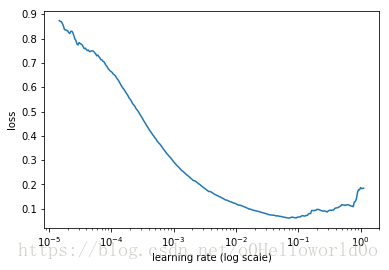
首先从一个很小的learning rate开始,每处理一个batch data时,增加learning rate,记录每一个learning rate梯度下降后的loss(视频中似乎没说是普通梯度下降还是别的优化算法),画出一个loss随learning rate变化的图像(图中的log scale表示横坐标是不均匀的)
斜率越大表示loss下降得越快,如learning rate=1e-3时,斜率最大,loss下降得越快
但我们想要学习率尽可能大一些,于是选择learning rate=1e-2,此时斜率仍然足够大
如果选择learning rate=0.1就不行,因为此时loss已经不再减小了
77:25
两种增加learning rate的方式:线性增加和指数级增加
82:15
忘记函数的参数是什么的时候,Shift+Tab按1次
Shift+Tab按2次,查看文档
Shift+Tab按3次,文档展示在底部
83:30
使用?查看文档,使用??查看源码
84:45
按H,显示Jupyter Notebook的快捷键
Lesson 8
视频链接:https://www.bilibili.com/video/av18904696/?p=8
使用cv2比PIL更快,并且在多线程下更安全
90:21
使用dict创建DataFrame时,不保证列的顺序,再指定columns就可以保证列的顺序
91:50
在Image Classification中,通常目标物体很大,且位于图像中心位置,可以做RandomCrop
而在Object Detection中,存在很多小物体,并且小物体可能位于图像边缘,因此不做任何Crop操作,直接将矩形图像squish成正方形
直觉上squish操作使图像中的物体变形了,但“still work pretty well”
95:00
next( dataloader_obj ),报错’DataLoader’ object is not an iterator.
改成next( iter( dataloader_obj ) )
101:40
In [130]的代码,画出多幅图像,很有用
115:40
对于bounding box regression,使用label = (row1, col1, row2, col2),即bounding box的左上角和右下角在图像矩阵中的行号和列号,直接使用像素值,而没有进行归一化
116:30
fastai中,使用tfm_y=TfmType.COORD来实现bounding box的data augmentation
118:40
对于bounding box regression,使用nn.L1loss()
Lesson 9,链接:https://www.bilibili.com/video/av18904696/?p=9
09:20
图像增强时,最多旋转30°,bounding box随之旋转,变成斜的矩形,取外接矩形即可
缺点是外接矩形所包含的范围变大了,不再精确表示物体的边界位置,视频中解决的办法是使用小一点的旋转角度,如最多旋转3°,并且以0.5的概率旋转
13:10
In [82]受到的启发:可以对Dataset使用数组下标,直接获取某个样本,如dataset[0]
17:50
在Single object detection的方案中,网络输出层节点数为4+len( cat ),为线性层,将坐标预测值经sigmoid变换到(0, 1),然后乘以224
18:15
Jeremy建议把BatchNorm放在Relu之后,然后再BatchNorm再接上Dropout
但是他又承认有时又会把BatchNorm放在Relu之前
ps:所以别总是纠结这个问题,随便选一种方案就行了
21:10
Loss的一部分是bounding box回归的L1loss,另一部分是分类的cross entropy loss,它们的取值其实是不在一个数量级的
在实际运行中观察它们的取值,发现将cross entropy乘以20之后二者的值才相当
22:03
有一个矛盾的地方,ResNet在AvgPool层中对空间维度上求了平均值,其实已经丢失了能够准确预测bounding box的信息(意思是AvgPool适合做分类任务,而不适合做检测),然而后面又加了全连接层预测bounding box,这样不就是先把信息丢失了,然后再“创造”信息吗?
34:30
视频中展示的这一页PPT
YOLO:Single object detection方案中,网络输出层节点数为4+C,只能检测1个物体,现在我想检测16个物体该怎么办?令网络输出层节点数为16×(4+C)
SSD:放弃使用全连接层,卷积层得到的feature map维度为7×7×512,那么可以使用一个卷积层将该feature map变化为4×4×(4+C),同样可以检测16个物体(此处将通道数变为4+C)
37:40
假设我们最终得到了一个2×2×(4+C)的feature map,将原始图像划分为2×2的网格
以图像上左上角的格子为例,为什么这个格子要负责检测落在其中的物体?
原因是,最后feature map空间维度上“左上角”的activation,对应的receptive field正好就是图像上左上角的格子
46:10
本来使用卷积就可以直接得到4×4×(4+C)的feature map,但是Jeremy认为还是分开进行卷积好一些,因此定义OutputConv,分别得到4×4×4和4×4×C的feature map,然后将它们拼接起来,得到最终的4×4×(4+C)的feature map
47:25
将最终的4×4×(4+C)的Tensor Flatten为16×(4+C),是为了方便计算loss
54:55
图像被划分为4×4的网格,每一个格子,在不同的paper中被称为anchor box,prior box,default box
56:55
查看图像的真实标记中的每一个bounding box,将每一个bounding box分配到某一个格子,分配的依据是Jacard Index(也称为IOU)最大
具体来说,假设真实标记有3个bounding box,坐标形成一个3×4的Tensor,再假设图像划分为4×4的网格,共16个格子,坐标形成一个16×4的Tensor,于是可以算出每个bounding box与每个格子的IOU,得到一个3×16的Tensor
map_to_ground_truth函数是干嘛的?
68:20
使用binary cross entropy,而不是softmax,为什么?没听懂
76:00
创建更多的anchor box,可以指定许多不同形状的anchor box
原先的版本,在每一个位置只有一个正方形的anchor box,现在我们可以在同一位置指定更多形状的anchor box
76:20
另一种创建更多的anchor box的方法
原先的版本,在每一个位置只有一个正方形的anchor box,现在我们可以将两个anchor box合并起来,构成一个新的anchor box,甚至可以将所有anchor box合并起来,构成一个最大的anchor box
91:20
现在anchor box有4×4的,有2×2的,有4×4的,那么我们就可以构建3个OutputConv,分别生成4×4×(4+C),2×2×(4+C),1×1×(4+C)的feature map
Lesson14,视频链接:https://www.bilibili.com/video/av18904696/?p=14
99:50
nn.ConvTranspose2d输出的Tensor为batch_size×1×128×128,而我们想要batch_size×128×128的Tensor,使用Lambda层去掉1的维度