一、算法简述
- Momentum(动量法):模拟物理动量的概念,积累之前的动量来替代真正的梯度
- Adagrad(Adaptive Gradient):每个参数反比于历史梯度平方总和的平方根
- RMSprop(Root Mean Squared propagation):AdaGrad的升级(将梯度积累替换为Running Average)
- Adam(Adaptive Moment Estimation):Momentum+ RMSProp + Bias Correction(偏差修正)
- 好了,说了一大堆,我们来看看这几个算法之间的关系(发展历史)

二、梯度下降的三种常用方式(不作为重点)
(备注:如果熟悉可跳过)
1. Batch Gradient Descent
- 定义:BGD其实就是标准的梯度下降,没有任何优化(naked guy)
- 优点:可保证每一次更新权重(weights)都能降低损失函数,并且可充分利用向量运算的优点
- 缺点:当我们有一个非常庞大的数据集时,运算会非常缓慢;不支持在线学习(Online Learning)
- 适用场景:在实际运用中已经不常用了,目前应用的都是基于庞大数据集的情况。(优胜劣汰)
2. Stochastic Gradient Descent
- 定义:随机梯度下降算法,每次训练迭代利用单个样本。
- 优点:训练速度非常快,可能整个数据集还没遍历完算法就已经收敛了。
- 缺点:收敛性能不太好。从迭代次数上看,SGD下降的迭代次数很多,在解空间搜索比较盲目,这使得它每次更新并不是朝着最优化方向进行,这是由于每个样本中存在的差异性以及各种问题所导致的;容易陷入鞍点(关于鞍点问题,在这里不讨论)。
- 适用场景:在线学习及其他,在实际中很常用。
3. Mini-batch Gradient Descent
- 定义:小批量梯度下降,这个算法介于上面两者中间,需要事先定义mini-batch size,算法性能很好
- 特点:一方面减少了梯度下降的盲目性,另一方面减少了BGD中存在的计算量大的问题。
4. 三种方式的直观对比

备注:由于论文中经常用SGD,下面就用SGD形式做讨论
三、算法解读(重点来了)
(1).Momentum算法(指数加权平均思想)

- 修改含义:将蓝色替换为红色下划线。
1. 特点
- 总是比BGD运行的效率好
2. 优化原理
(下面是SGD的迭代过程,红色点是最优点)
- Momentum是通过减少摇摆方向的梯度来优化梯度下降的。
- 在上图中我们考虑两个方向上的优化:W,b。其中W待变横轴方向的梯度,b代表纵轴方向的梯度。我们想要的结果是纵向减少摆幅,横向加快移动。那我们就来看看Momentum是如何实现的。
- Momentum利用指数加权平均的思想:在当前迭代过程中充分考虑了之前的梯度,然后加权平均。这样做的好处是:通过平均当前和过去的梯度,减缓了纵轴(摇摆方向)的摇摆幅度,而在横轴方向,所有的梯度都指向了最优化方向,所以横轴的梯度值依然会很大(算法的倒数第三行解释了这一概念,对应的思想恰恰就是指数加权平均)。
- Momentum中含有两个超参数(Hyper-parameter):学习率epsilon、动量参数 α。(论文中指出α=0.9是一个很好的鲁棒数,epsilon=0.001是个建议值)
- 最后直观理解一下Momentum “动量” 的含义,这有助于梯度下降跳出鞍点(Saddle point)
- 想象一下,一个小车从高坡上冲下来,他不会停在最低点,因为他还有一个动量,还会向前冲,甚至可以冲过一些小的山丘,如果面对的是较大的坡,他可能爬不上去,最终又会倒车回来,折叠几次,停在谷底。

- 如果使用的是梯度下降,则会停在鞍点。

(2)Adagrad算法

1. 特点:
- AdaGrad算法独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根,学习率单调递减,训练后期学习率非常小。因此该算法适合稀疏梯度的学习。
- 从公式(倒数第三行)可以看出,Adagrad算法中有自适应调整梯度的意味(adaptive gradient)
2. 优化原理
- 如果目标函数有关自变量中某个元素的偏导数g一直都较大,那么该元素的学习率epsilon 将下降较快(在最后更新参数向量时除以一个很大的数字,所以会降低这个维度方向上的训练进度,这个方向的梯度可能是震荡的,希望震荡小一点);
- 反之,某个元素的偏导数一直较小,则该元素的学习率下降较慢(更新参数向量时除以一个很小的数字,从而加速了在小梯度维度上的学习速度)
3. 存在的问题
- 由于全局学习速率epsilon除以的是累加梯度的平方,到后面累加的比较大时,会导致每次的学习率逐渐减小,导致梯度更新缓慢,最终可能会导致训练中后期就停止迭代了。
- 不适用于非凸函数,当到达一个局部极值点时,会困在这里,使得训练过程无法再进行下去
(3) RMSprop(Root Mean Squared prop)

1. 算法特点
- RMSProp 算法是针对 Adagrad 算法的缺陷进行修改,改变梯度积累为指数加权移动平均
- Adagrad 算法旨在应用于凸问题时快速收敛
- RMSProp 算法使用指数衰减平均以丢弃遥远过去的历史
- RMSProp算法的学习率是自适应的
2.优化原理
还拿下面这个图来直观的理解一下(当然参数空间可能是很高维度的空间)
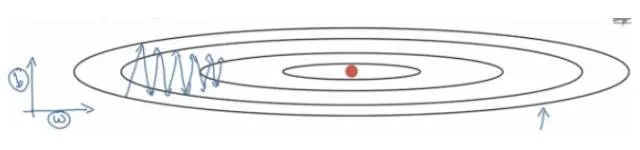
- 由图可知道,W方向的梯度值是很小的,而b方向的梯度值很大。我们希望加快W方向,而减缓b方向的迭代。
- 当W梯度值很小时,通过算法,可知 :当前学习率=全局学习率 / r,此时当前学习率会增加,也即当前的step增加;同理,当b方向的梯度值很大时,步长会减小,从而降低摇摆幅度。
3. 存在的问题
- 没有什么太大的问题,该算法只是在一定程度上表现得很好。如果非要说问题,那么我就说对梯度下降算法提升得程度还不够高!
(4) Adam算法(重头戏)

1. 算法特点
- 该算法结合了Momentum(First-order moment)和RMSProp(Second-order moment)两者得优点
- 动量直接并入了梯度一阶矩(指数加权)的估计,将动量加入RMSProp最直观的的方法是将动量应用于缩放后的梯度。
- Adam 算法通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改
- Adam算法是需要修正偏差的,偏差是由于初始化问题导致的,具体的公式由来是可以证明的,在这里不在多说,具体参考《ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION》
- 计算效率很高,使用的内存相对较小
2. 优化原理
- 结合Momentum和RMSProp即可
3. 存在的问题
- Adam算法是2015年ICLR会议上提出来的,要说问题,没啥问题我觉得,最近好像是清华大学一个本科生提出了一种算法,效率比Adam高,还有的论文也多多少少指出了Adam算法确实存在一些缺陷,等以后有机会再深入。
4. Adamax(Adam算法的一个扩展)
- 主要原理就是将Adam中梯度的二范数一般化为p范数,这里p要趋近于无穷
- 没有偏差修正
- 学习率α的范围很好确定
- 具体数学证明参考原著

5. 一个注意要点
- 关于stepsize的选择范围要慎重,Adam算法原著中有相关解释,看一参考,这里不再叙述,下面把原著中这一部分贴出来供大家参考。


四、总结
- Adam大法好啊,深度学习中很常用的算法,得get!
五、参考文献
[1]参考文献1
[2]参考文献2
[3]ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION,Diederik P . Kingma,Jimmy Lei Ba,2015-ICLR.
