map概念
Go 语言中 map 是一种特殊的数据结构:一种元素对(pair)的无序集合,pair 的一个元素是key,对应的另一个元素是value,所以这个结构也称为关联数组或字典。这是一种快速寻找值的理想结构:给定key,对应的value可以迅速定位。
map使用
初始化
func test1() {
map1 := make(map[string]string, 5)
map2 := make(map[string]string)
map3 := map[string]string{}
map4 := map[string]string{"a": "1", "b": "2", "c": "3"}
fmt.Println(map1, map2, map3, map4)
}
删除map中指定key:
func main(){
mymap:=make(map[string]string)
mymap["key"] = "value"
fmt.Println(mymap)
delete(mymap,"key")
fmt.Println(mymap)
}
新增map中的key(map会自动扩容)
func main(){
mymap:=make(map[string]string)
mymap["key"] = "value"
mymap["key2"] = "value2"
}
查看map中的key是否存在
func main(){
mymap:=make(map[string]string)
mymap["key"] = "value"
_,ok:=mymap["key2"]
if ok{
fmt.Println("key exist")
}else{
fmt.Println("key not exist")
}
}
map作为函数的参数
Golang中是没有引用传递的,均为值传递。这意味着传递的是数据的拷贝。
那么map本身是引用类型,作为形参或返回参数的时候,传递的是地址的拷贝,扩容时也不会改变这个地址。(与slice形成对比,slice扩容会生成新对象,则不影响外面的值)
func changeMap(mm map[string]string){
for i:=0;i<10;i++ {
ss:=strconv.Itoa(i)
mm[ss] = ss
}
fmt.Println(len(mm))
}
func changeArr(arr []int){
for i:=0;i<10;i++{
arr = append(arr,i)
}
fmt.Println("function")
fmt.Println(&arr[0])
fmt.Println(arr)
fmt.Println("function")
}
func main(){
mymap:=make(map[string]string)
mymap["key"] = "value"
fmt.Println(len(mymap))
fmt.Println(&mymap)
changeMap(mymap)
fmt.Println(&mymap)
fmt.Println(mymap)
arr:=make([]int,5)
arr = append(arr,1)
fmt.Println(&arr[0])
changeArr(arr)
fmt.Println(arr)
fmt.Println(&arr[0])
}
map源码分析
map结构体代码
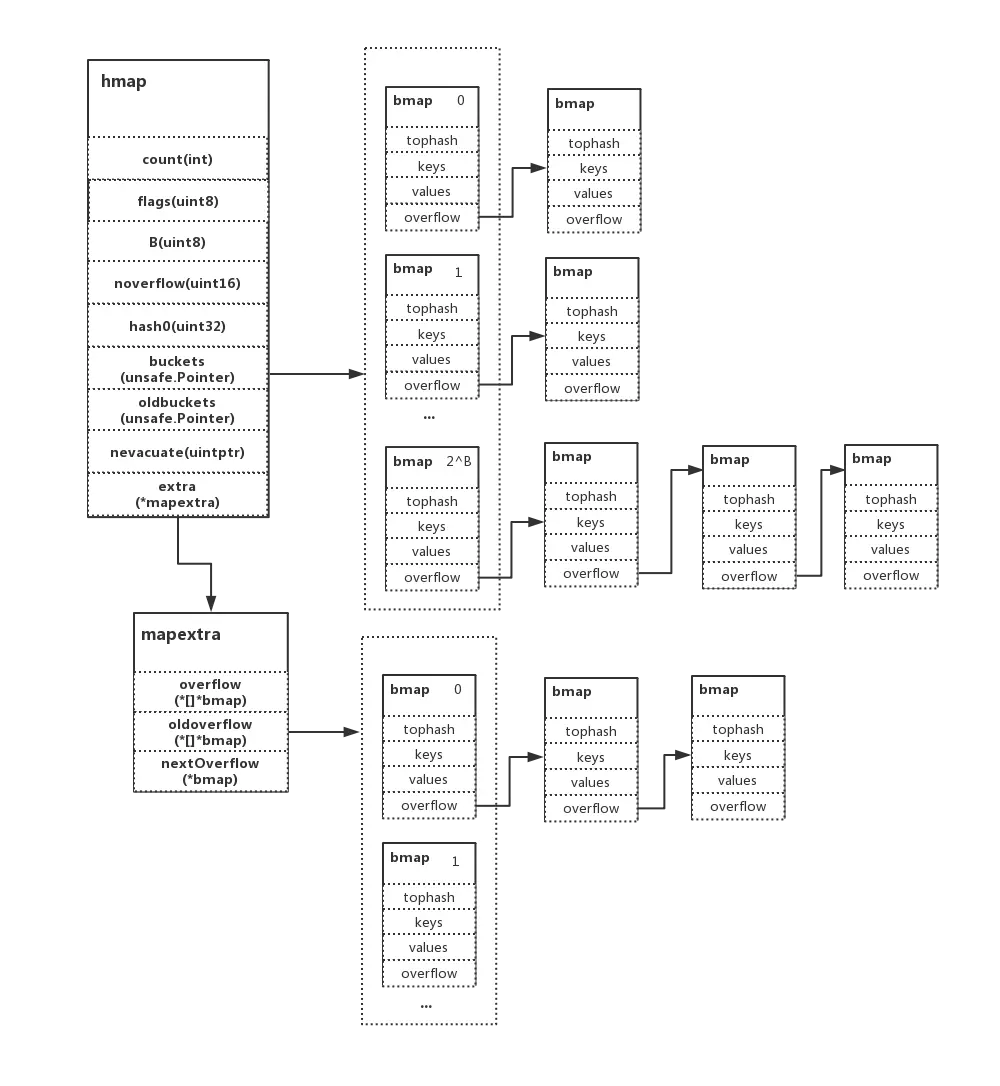
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # map中key的个数,len()返回使用count
flags uint8 //状态标识,主要是 goroutine 写入和扩容机制的相关状态控制。并发读写的判断条件之一就是该值
B uint8 // 桶数目,可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // 桶的地址
oldbuckets unsafe.Pointer // 旧桶的地址,用于扩容
nevacuate uintptr // 搬迁进度,当map扩容的时候需要将旧桶数据迁移到新桶
extra *mapextra // optional fields
}
type mapextra struct {
//若map中所有的key和value都不包含指针且内联,那么将存储bucket的类型标记为不包含指针,这样可以防止回收此类map
//然而,bmap.overflow是一个指针,目的是保存桶溢出的活性防止被回收,,我们将指向所有溢出桶的指针存储在hmap.extra.overflow和hmap.extra.oldoverflow中。
//仅当所有key和value不包含指针的时候才是用overflow和oldoverflow
// overflow包含hmap.buckets的溢出桶。
// oldoverflow 包含hmap.oldbuckets的溢出桶.
//间接允许将指向切片的指针存储在hiter中。
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow 拥有一个指向空闲溢出桶的指针
nextOverflow *bmap
}
bucket 结构体代码
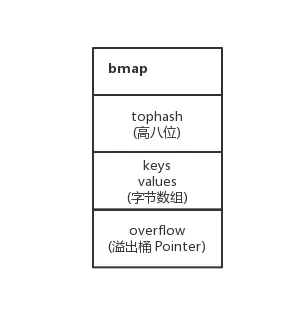
// A bucket for a Go map.
type bmap struct {
//tophash通常包含此存储桶中每个键的哈希值的最高字节。
//如果tophash [0] <minTopHash,则tophash [0]而是铲斗疏散状态。
tophash [bucketCnt]uint8
}
1.tophash用于记录8个key哈希值的高8位,这样在寻找对应key的时候可以更快,不必每次都对key做全等判断。
2.bucket并非只有一个tophash,而是后面紧跟8组kv对和一个overflow的指针,这样才能使overflow成为一个链表的结构。但是这两个结构体并不是显示定义的,而是直接通过指针运算进行访问的。
3.kv的存储形式为key0key1key2key3…key7val1val2val3…val7,这样做的好处是:在key和value的长度不同的时候,节省padding空间。如上面的例子,在map[int64]int8中,4个相邻的int8可以存储在同一个内存单元中。如果使用kv交错存储的话,每个int8都会被padding占用单独的内存单元(为了提高寻址速度)。
map内存增长
golang的map会自动增加容量,增加原理:
每个map的底层结构是hmap,是有若干个结构为bmap的bucket组成的数组,每个bucket可以存放若干个元素(通常是8个),那么每个key会根据hash算法归到同一个bucket中,当一个bucket中的元素超过8个的时候,hmap会使用extra中的overflow来扩展存储key。
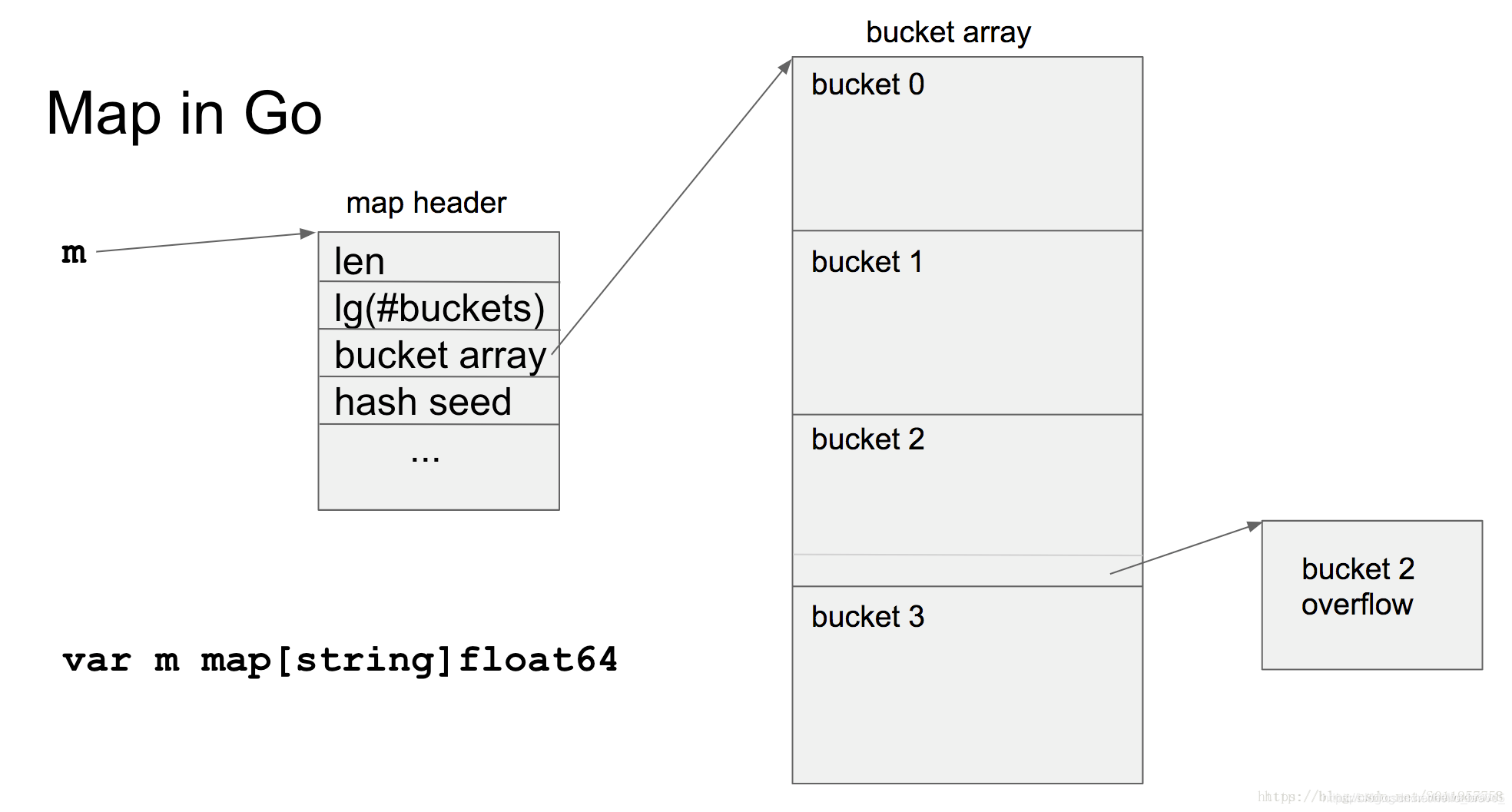
map的增长有两种方式
1.增加桶的数目,新的为旧桶数目的二倍
2.横向增长一个桶后面的链表(golang使用链地址法解决hash冲突)
map的增长方式是增量增长,所以有一个旧的一个新的
func hashGrow(t *maptype, h *hmap) {
// 若达到了负载因子6.5*2^B,则增大桶的数目
// 否则,说明桶的数目足够,增大桶的指针
bigger := uint8(1)
// overLoadFactor报告放置在1 << B个存储桶中的计数项目是否超过loadFactor。
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
参考:
https://blog.csdn.net/xiangxianghehe/article/details/78790744
https://www.jianshu.com/p/aa0d4808cbb8
https://blog.csdn.net/wade3015/article/details/100149338
https://www.jianshu.com/p/8ea1bf5058c7
https://www.jianshu.com/p/71ef92fc34d9
https://blog.csdn.net/weixin_42506905/article/details/96176336
