-
电脑先预装MongoDB和数据库可视化软件robo3t,python下载pymongo库
-
预先启动数据库
可以自己写一个小脚本文件方便启动
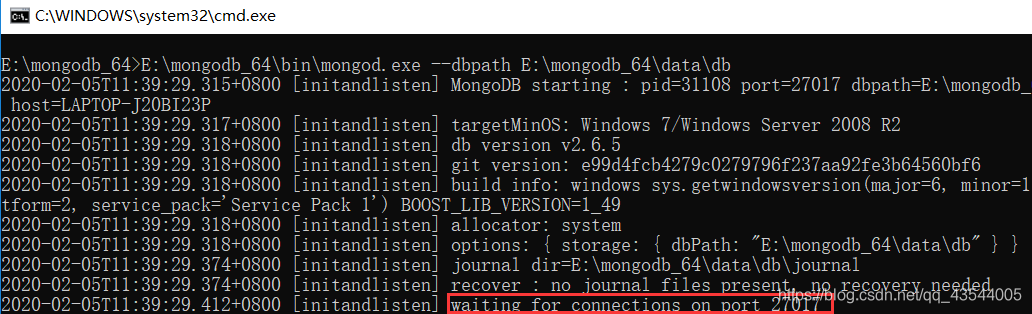
内容:E:\mongodb_64\bin\mongod.exe --dbpath E:\mongodb_64\data\db

出现了等待连接的 27017端口时,说明启动成功
-
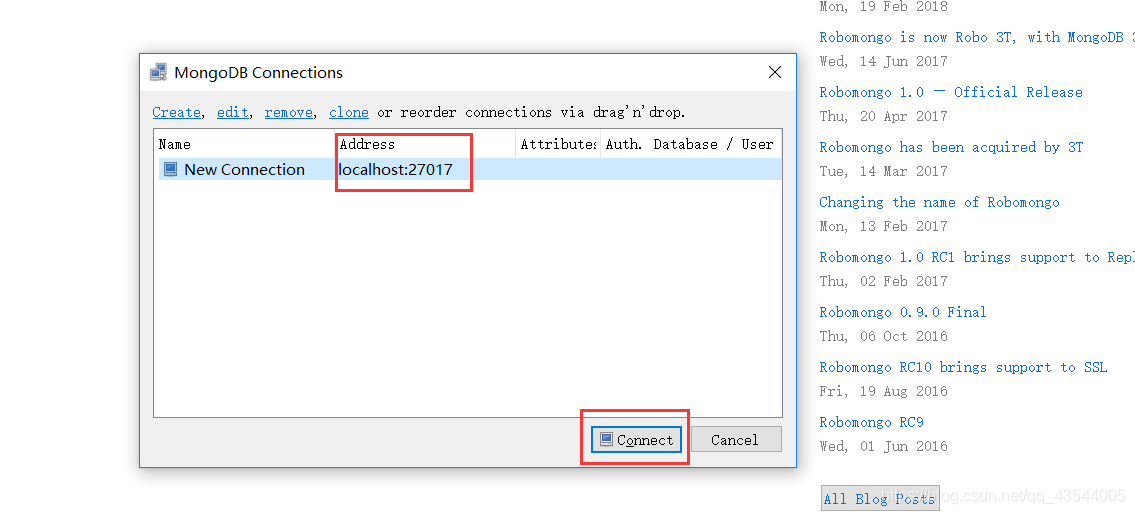
打开可视化软件 robo3t 并连接数据库
-
打开自己的pycharm编写代码, 实现python与MongoDB交互
from pymongo import MongoClient
class RuanyunPipeline(object):
#开启爬虫时 连接 MongoDB数据库 并创建表名douluodalu
def open_spider(self,spider):
self.client=MongoClient()
self.db=self.client.douluodalu
self.collection=self.client.db.douluodalu
#将item里的内容 插入数据库
def process_item(self, item, spider):
self.collection.insert(item)
return item
#关闭爬虫与数据库
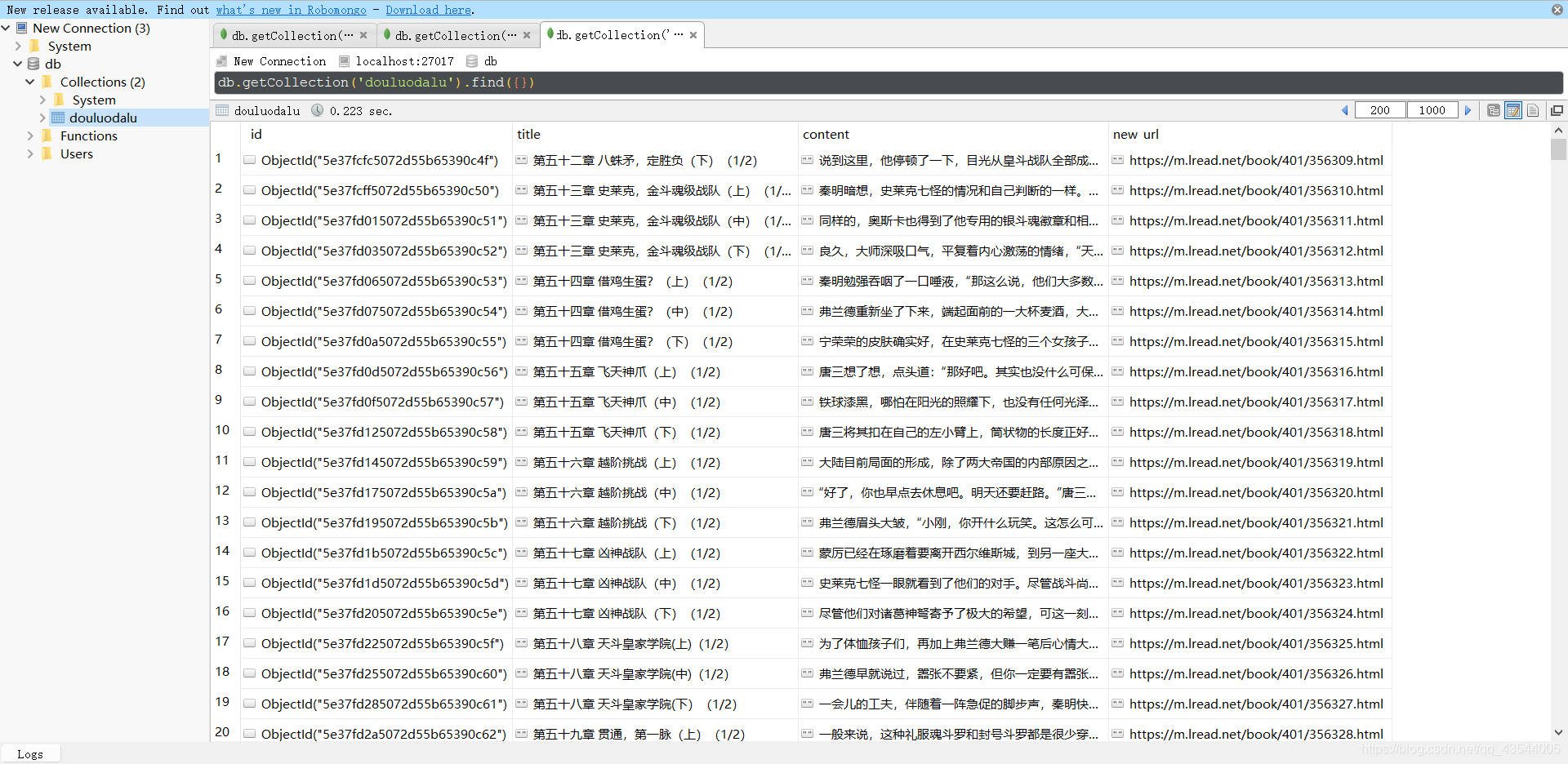
- 执行scrapy,查看保存到数据库的内容。