环境配置
- Window 10专业版
- MongoDB 3.4
- Robomongo 1.0
- Python 3.6
- Scrapy 1.4.0 (pip install scrapy)
- pymongo 3.5.0 (pip install pymongo )
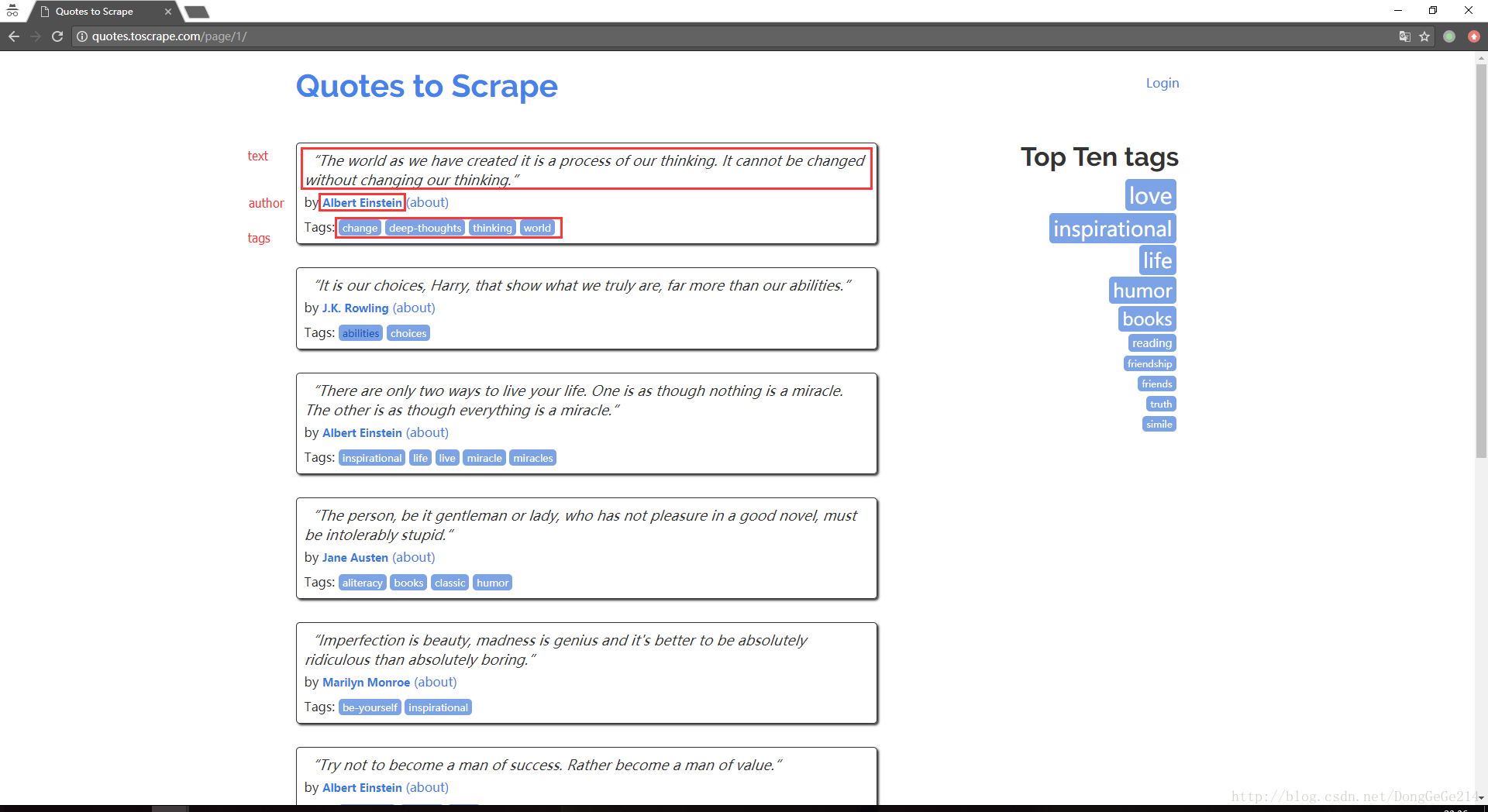
先看一下待爬页面,从而抽象出数据模式(text ,author,tags)
创建Scrapy示例项目
scrapy startproject tutorial在tutorial/spiders目录下新建爬虫脚本quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes" # 爬虫名称须要唯一,scrapy需要通过名称确定启动哪个爬虫。
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('small.author::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
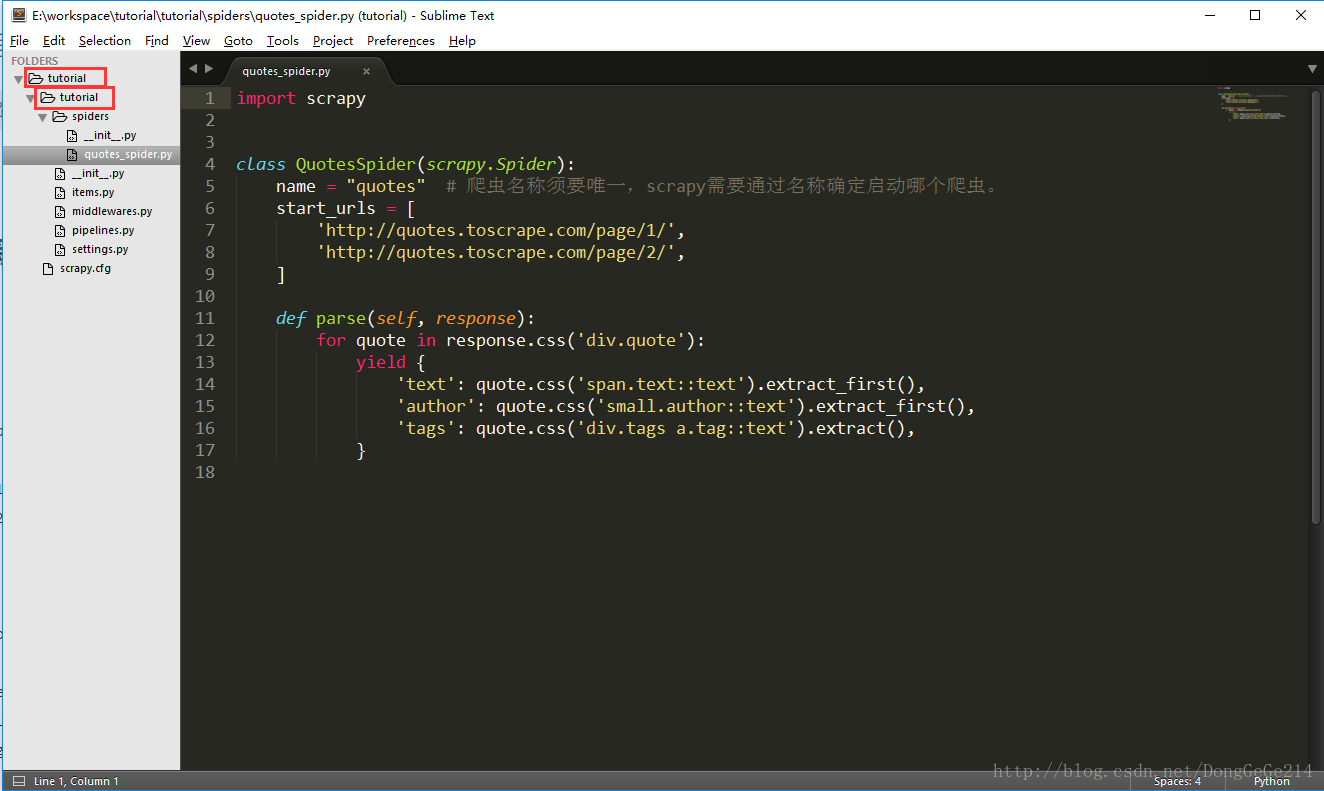
}完整的项目结构图如下
在settings.py文件下底部,追加数据库配置
MONGO_HOST = "127.0.0.1" # 主机IP
MONGO_PORT = 27017 # 端口号
MONGO_DB = "tutorial" # 库名
MONGO_COLL = "items" # 文档名(相当于关系型数据库的表名)将settings.py中的启用管道命令的封印(大概在67~69行的注释)解开
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300,
}
在items.py中添加文档定义(可以理解为定义关系型数据库的表结构)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
编辑piplines.py,存储爬取的数据(已做去除重复数据处理)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
class TutorialPipeline(object):
def __init__(self):
# 连接数据库
self.client = pymongo.MongoClient(
host=settings['MONGO_HOST'], port=settings['MONGO_PORT'])
# 数据库登录需要帐号密码的话,在settings.py底部追加
# MINGO_USER = "username"
# MONGO_PSW = "password"
# self.client.admin.authenticate(settings['MINGO_USER'], settings['MONGO_PSW'])
self.db = self.client[settings['MONGO_DB']] # 获得数据库的句柄
self.coll = self.db[settings['MONGO_COLL']] # 获得collection的句柄
def process_item(self, item, spider):
insert_item = dict(item) # 把item转化成字典形式
# 插入之前查询text是否存在,不存在的时候才插入。
self.coll.update({"text": insert_item['text']}, {
'$setOnInsert': insert_item}, True)
# self.coll.insert(insert_item) # 向数据库插入一条记录
# return item # 会在控制台输出原item数据,可以选择不写
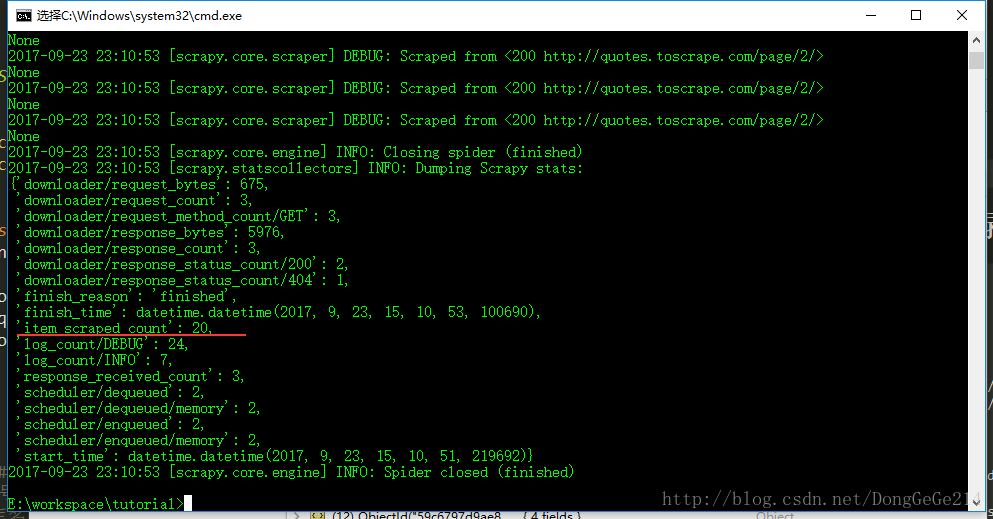
在tutorial目录下输入命令,运行爬虫
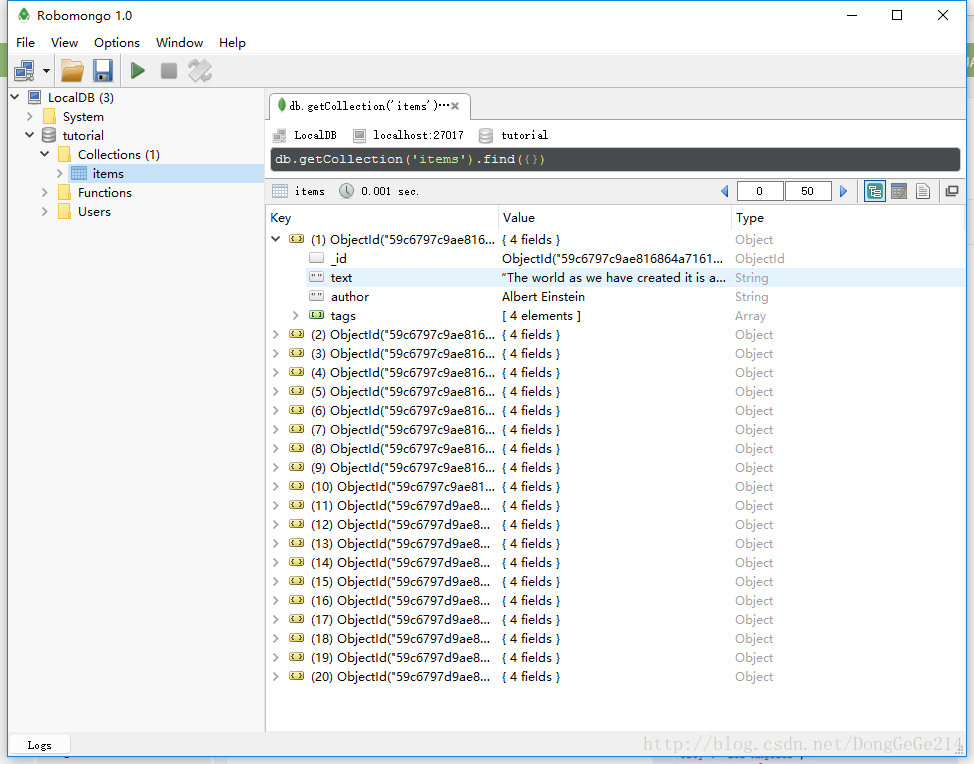
scrapy crawl quotes随着控制台日志的输出结束,20条数据就顺利入库了。
下载地址
http://download.csdn.net/download/donggege214/9992382
参考官网内容:
https://docs.scrapy.org/en/latest/intro/tutorial.html
https://docs.scrapy.org/en/latest/topics/item-pipeline.html#write-items-to-mongodb