我们已经知道一些方法可以用来估计(可避免的)偏差和方差可以导致多少误差。这些方法包括估计最佳的错误率和计算算法的训练集和开发集误差。下面我们将讨论一种可以获得更多信息的方法:绘制学习曲线。
学习曲线绘制了开发集错误率和训练样本数量之间的关系。为了绘制学习曲线,需要在不同的训练集大小上运行算法。例如,如果有1000个样本,可以在100,200,300,…,1000个样本上分别运行算法。这样就可以画出关于开发集错误率和训练样本数量的学习曲线。举例如下:

随着训练集的增大,开发集错误率应该减少。
我们通常为算法设置一个期望错误率。比如:
- 如果期望人类水平的性能,则人类水平错误率就是期望错误率
- 如果算法作为某种产品(例如识别有猫的图片),我们可能会直观的知道什么样的性能才能给用户一个好的体验。
- 如果你在一个重要的应用上工作了很长的时间,你可能已经形成了一种直观的感觉:明年我可能在这个应用上取得多少成果。
为学习曲线添加期望的性能:
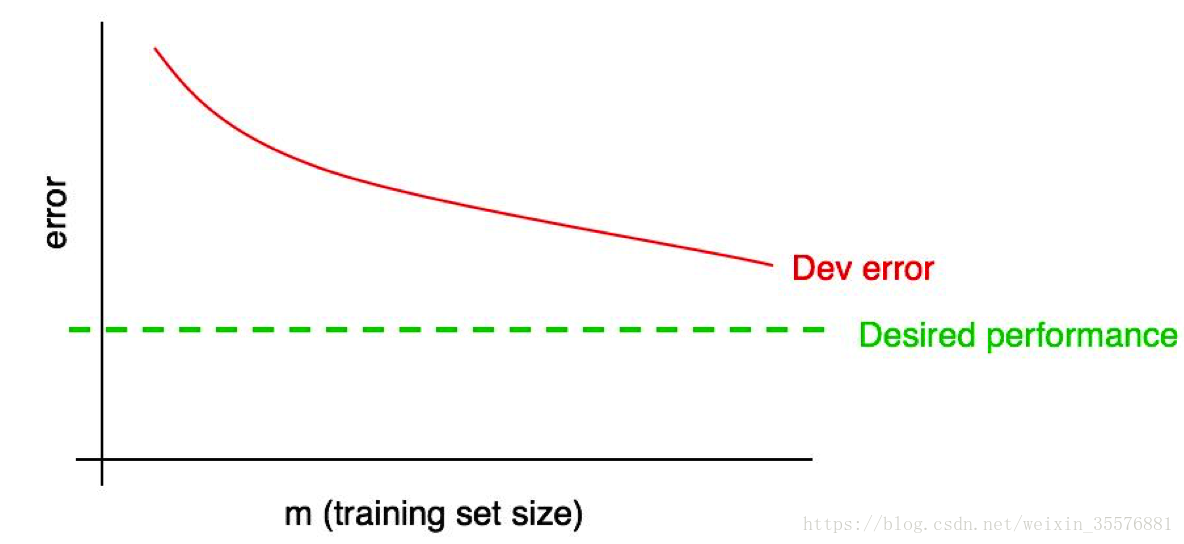
可以从图中猜出增加训练集样本数量之后,红色的“开发集错误率”可以在多大程度上靠近期望值。上面的例子中,看起来增加一倍的训练样本可能达到期望的性能。
但是如果开发集错误率已经是稳定状态(例如:曲线变平了),那么可以立即肯定增加训练样本没什么用处。
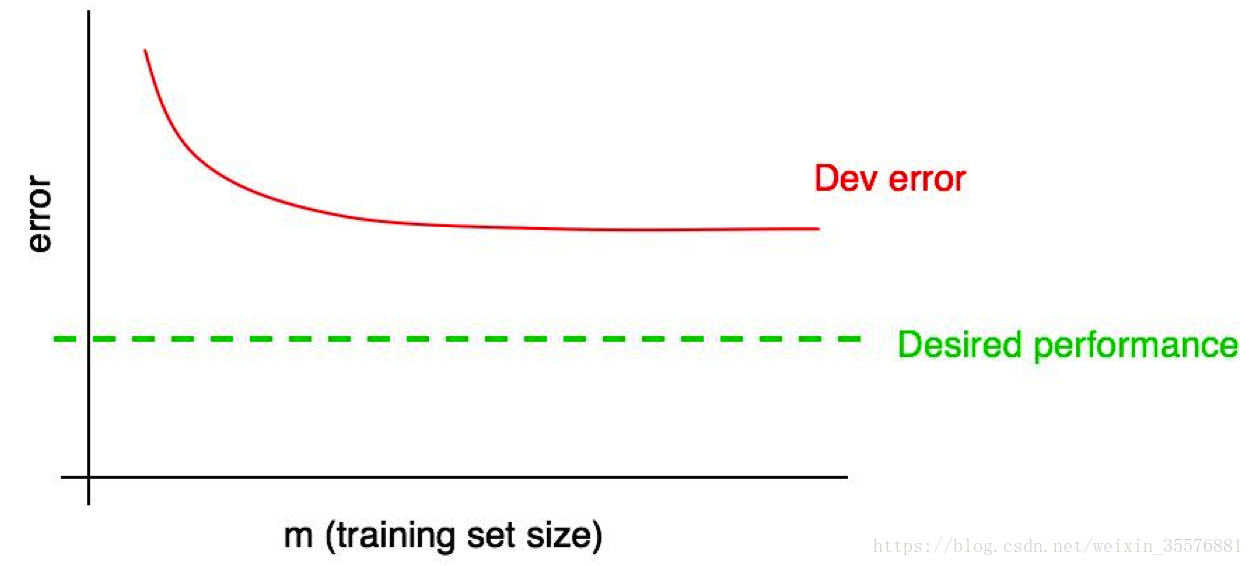
分析上图的学习曲线,可以避免你花费数月时间,收集大量数据到最后发现没有什么用处。
只分析开发集错误率也有其不利的一面,因为即使增加更多训练数据也很难推断红色曲线将会是什么趋势。额外绘制训练集错误率曲线将会有利于估计增加训练数据所产生的效果。