偏差与方差详解
1 问题背景
NFL(No Free Lunch Theorem)告诉我们选择算法应当与具体问题相匹配,通常我们看一个算法的好坏就是看其泛化性能,但是对于一个算法为什么好为什么坏,我们缺乏一下认识,”Bias-Variance-Decomposition”就是从偏差,方差的角度来解释一个算法的泛化性能
2 一点点数学
期望:体现了随机变量取值的平均水平
方差:随机变量取值在其平均值附近的离散程度

“Bias-Variance-Decomposition”是以测试集上误差的平方为基础的,假设我们的预测值为g(x)
,真实值为f(x),则均方误差为E[(g(x)-f(x))2]+噪声
实际意义:均方误差就可以理解为对算法(模型)泛化性能的一种度量,所以我们要做的就是找到均方误差的最小值.
补充:
为了让世界更加美好,我们这里不考虑样本的噪声
(噪声的存在是学习算法所不能解决的问题,数据的质量决定了学习的上限,假设数据在已经给定的情况下,此时上限已定,我们要做的就是尽可能的接近这个上限)
并且使用g代表测试集的预测值(这里我们把它看成是随机变量,即模型对测试集中不同样本的预测结果),f代表测试集的真实结果,E(g)代表算法的预测期望.
有K个样本,对应就有K个g(x), K个f(x)相同
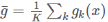
回过来我们要计算均方误差的最小值:
E[(g(x)-f(x))2]中g(x)是一个随机数,取值可为g1(x),g2(x)…gk(x),概率都为1/k,f(x)是一个常数
对均方误差的公式做简化:
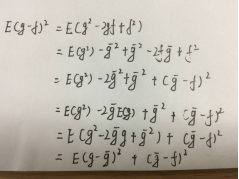
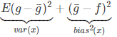
3 偏差与期望
由以上公式可知,
偏差:度量了学习算法的预测期望与真实结果的偏离程度,即刻画了学习算法本身对数据集的拟合能力
方差:度量了同样大小的训练集的变化所导致的学习性能的变化,即刻画了数据扰动所造成的影响.
噪声:表示任何算法的泛化能力下界,描述了学习问题本身的难度
偏差与方差的形象如下图所示:
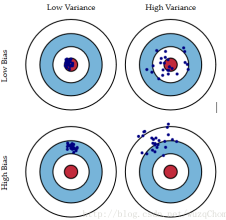
图中的红色部分是真实值所在位置,蓝色部分是算法每次预测的值
可以看出:偏差越高则离红色部分越远,而方差越大则算法每次的预测之间的波动会比较大
4 偏差方差窘境
下图:给出了方差偏差和总体泛化误差的示意图

由图知:偏差与方差两者是有冲突的,称之为偏差方差窘境
假设我们学习算法训练不足(欠拟合)时,此时学习器的拟合能力不够强,此时数据的扰动不会对结果产生很大的影响(可以想象成训练的程度不够,此时学习器指学习到了一些所有数据都有的一些特征),这个时候偏差主导了算法的泛化能力,随着训练的进行,学习器的拟合能力逐渐增强,变差逐渐减小,但此时学习器对不同数据的学习可能会有较大的方差,即此时方差主导模型的泛化能力(过拟合),若学习进一步进行,学习器就可能学到数据集所独有的特征,而这些特征对于其他的数据时不适用的,这个时候就发生了过拟合现象
5 Bagging与Boosting
Bagging与Boosting是集成学习当中比较常用的两种方法,刚好分别对应了降低模型的方差与偏差.
Bagging是通过重采样(所以是方差)的方式来得到不同的模型,假设模型独立则有:

所以从这里我们可以看出Bagging主要可以降低的是方差
Bagging是并行算法,算法步骤如下:
1基于BootStrap自助采样过程,保证63.2%样本能被采样得到(可重复的采样)
2数据集分成了t1,t2…tm(重复采样了m次)
3通过决策树或其他算法结合数据训练模型
4测试集测试所有的模型,按照举手表决(少数服从多数),决定分类
而Boosting每次关注都使得整理的loss少了,很显然可以降低bias,这里的模型之间并不独立,所以不能显著减少variance,而Bagging假设模型独立则可以减少variance
补充:正则化降低模型的方差.
补充:集成学习算法除了上述两种之外,还有stacking算法:将上一个模型的输出作为下一个模型的输入. 代表用法是排序模型中的GBDT+LR
为什么说bagging是减少variance,而boosting是减少bias? 回答的很精彩:
https://www.zhihu.com/question/26760839