第一个Scrapy框架爬虫
我要爬取的网站是一个网课网站http://www.itcast.cn/channel/teacher.shtml,爬取内容是所有老师的基本信息。
1.创建一个基于Scrapy框架的爬虫项目
进入自定义的项目目录中,运行下列命令:
**ITCast为项目名字**
scrapy startproject ITCast
2. 结构化所获取数据字段
打开项目目录找到items.py,这个模块,我觉得就像java中的对象实体类的定义,但是所有类都必须是scrapy.Item的子类,这里我定义一个ItCastItem类,用于保存每一位老师的基本信息。
import scrapy
class ItCastItem(scrapy.Item):
name = scrapy.Field() # 教师名字
title = scrapy.Field()# 教师职称
info = scrapy.Field() # 教师履历
3.制作爬虫
1.我们必须创建一个爬虫(可以在pycharm下的terminal下输入该命令)
scrapy genspider itcast "itcast.cn"
创建的爬虫会自动生成在你的项目的spiders目录下,并且自动生成文件itcast .py,里面还自动添加了一些基本代码
每个爬虫都强制要求拥有三个属性
- name :爬虫的名字,由常见爬虫的时候指定
- allowed_domains:是搜索的域名范围,即爬虫的作用域,一般指定该域名之后,爬虫则只会爬取该域名下的网页,不存在的URL将会被忽略
- start_urls:爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
2.修改parse()方法,解析页面数据
# -*- coding: utf-8 -*-
import scrapy
from ITCast.items import ItCastItem
from lxml import etree
class ItCastSpider(scrapy.Spider):
name = 'itcast' # 这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allowed_domains = ['itcast.cn'] # 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始
# 解析的方法
def parse(self, response):
'''
解析返回的网页数据(response.body),提取结构化数据(生成item)
:param response:
:return:
'''
print(response.body)
filename = "teacher.html"
with open(filename,'wb') as f:
f.write(response.body)
context = response.xpath('/html/head/title/text()')
# print(context)
# 提取网站标题
title = context.extract_first()
print(title)
html = etree.HTML(response.text)
print("===============\n\n\n\n\n\n")
#print(text.xpath("//div[@class='li_txt']"))
print("===============\n\n\n\n\n\n")
items = [] # 存放老师信息对象的列表
# print(response.xpath("//div[@class='li_txt'][1]"))
# print(html.xpath("//div[@class='li_txt']"))
# 获取每一个教师对象,进行封装
for each in html.xpath("//div[@class='li_txt']"):
# 将得到的数据封装到一个'ItcastItem'对象中
item = ItCastItem()
name = each.xpath(".//h3/text()")
title = each.xpath(".//h4/text()")
info = each.xpath(".//p/text()")
# 封装,xpath返回的是包含一个元素的列表,所以用name[0]
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 返回结果集
return items
5.运行爬虫并保存数据
运行爬虫有简单的主要几种方式模式(还有其他的没列出来)
scrapy crawl itcast //单纯的运行爬虫,结果会在终端打印出来
scrapy crawl itcast -o teachers.json //运行虫,并保存为json文件数据格式
scrapy crawl itcast -o teachers.jsonlines //运行爬虫,并保存为jsonlines文件数据格式
scrapy crawl itacst -o teachers.csv //运行爬虫,并保存为csv文件数据格式(可以使用Excel打开)
scrapy crawl itcast -o teachers.xml //运行爬虫,并保存为xml文件数据格式
6.查看结果
回到项目目录可以看到已经生成的文件,给大家看一下我的项目目录和生成的文件
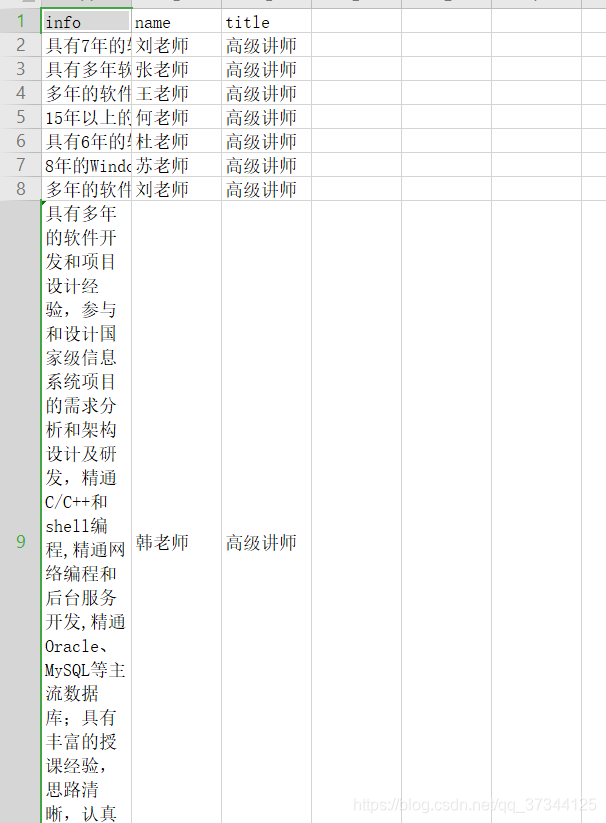
7. 错误总结
解析页面的时候,总是不能正确的拿到数据,每次拿到的数据都是空列表,因此用了chropath插件慢慢的在谷歌浏览器尝试,后来才发现,原来是在获取每个item的info,name,title的时候,使用错了xpath。
(错误的)我之前填写的是:
name = each.xpath("//h3/text()")
title = each.xpath("//h4/text()")
info = each.xpath("//p/text()")
这里的each是网页中的每一位教师的div外框,因此我想通过这种方式,然后直接获取该div下的第一个h3,h4 , p标签,但是一直获取的都是错误数据
我查询错误数据来源,发现竟然是页面的第一个h3,h4 , p标签的内容,我顿时醒悟。
(正确的)应该是这样:
name = each.xpath("./h3/text()")
title = each.xpath(".//h4/text()")
info = each.xpath(".//p/text()")
加个点后,就是取当前元素的子元素,否则它就从最开始查找了。
要是有些地方不对,请大家帮忙指出哦,欢迎大家留言。
一起共勉!!!
