前刚接触python,看了一下基本语法,照着网上的一篇博客写了个很简单的爬虫小demo,有兴趣的可以看下
实现,将一个网页中的所有jpg图片,及网页中所有.html格式的跳转链接中的jpg文件取出来保存到本地
主要用到一个urllib库,使用很简单,用于读取网页内容,和直接从网络下载图片(感觉这个库很屌的样子)
还有就是一些正则验证,用于筛网页中选想要的内容
直接贴代码:
#coding=utf-8
import urllib,threading
import re
x = 0
# 读取网页内容
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
# 获取html所有.html的跳转链接
def getHtmlUrl(html):
# 定义正则 href="任意数量的任意字符+ .html"
reg = r'href="(.+?\.html)"'
urlreg = re.compile(reg)
#提取所有.html链接
urllist = re.findall(urlreg,html)
return urllist
#取出每个链接中的 .jpg文件
def getImgs(urlList):
# 遍历数组中的所有链接
for url in urlList:
#获取每个链接html的内容
html=getHtml(url)
getImg(html)
#取出某个html页面的所有.jpg链接 并保存到本地
def getImg(html):
global x
# 定义正则 src="任意数量的任意字符+ .jpg"
reg = r'src="(.+?\.jpg)"'
imgre = re.compile(reg)
# 得到所有图片链接
imglist = re.findall(imgre,html)
for imgurl in imglist:
# 将文件下载到本地
urllib.urlretrieve(imgurl,'D:\images\%s.jpg' % x)
x+=1
html = getHtml("http://news.baidu.com/")
#先取出当前页的图片
getImg(html)
# 再取出所有链接html中的图片
urlList = getHtmlUrl(html)
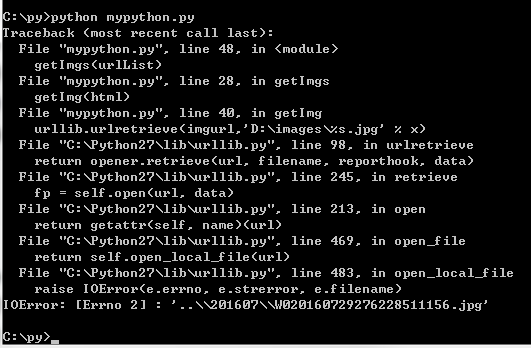
getImgs(urlList)然后执行python文件(这里有报错,好像是取出的图片链接有几个取不到):
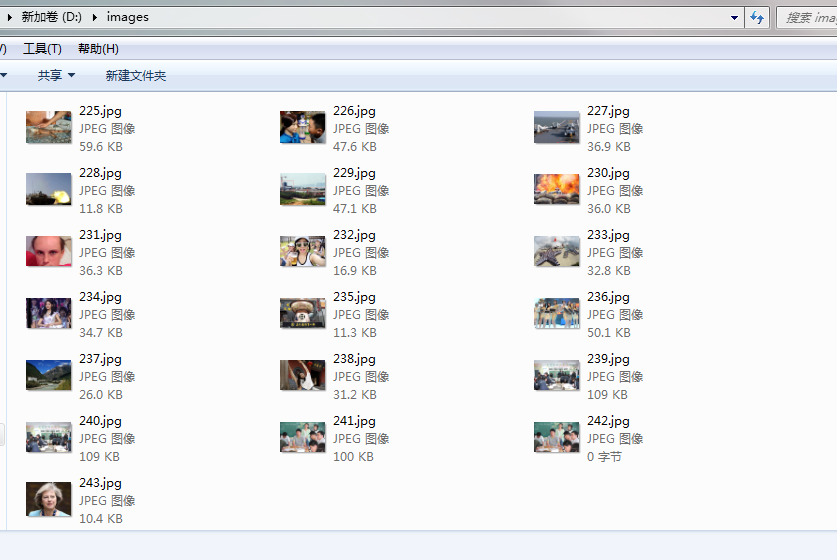
打开之前指定的文件夹,图片已经都下载下来了!