形象的解释神经网络激活函数的作用是什么?]
激活函数是用来加入非线性因素的,解决线性模型所不能解决的问题。
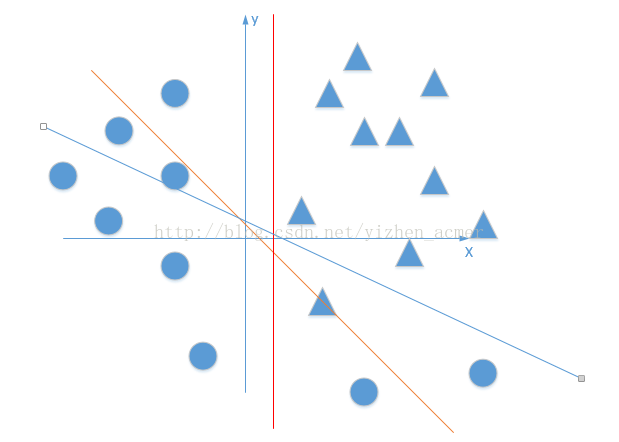
首先我们有这个需求,就是二分类问题,如我要将下面的三角形和圆形点进行正确的分类,如下图:

利用我们单层的感知机, 用它可以划出一条线, 把平面分割开:

上图直线是由 得到,那么该感知器实现预测的功能步骤如下,就是我已经训练好了一个感知器模型,后面对于要预测的样本点,带入模型中,如果y>0,那么就说明是直线的右侧,也就是正类(我们这里是三角形),如果
得到,那么该感知器实现预测的功能步骤如下,就是我已经训练好了一个感知器模型,后面对于要预测的样本点,带入模型中,如果y>0,那么就说明是直线的右侧,也就是正类(我们这里是三角形),如果 ,那么就说明是直线的左侧,也就是负类(我们这里是圆形),虽然这和我们的题目关系不大,但是还是提一下~
,那么就说明是直线的左侧,也就是负类(我们这里是圆形),虽然这和我们的题目关系不大,但是还是提一下~
好吧,很容易能够看出,我给出的样本点根本不是线性可分的,一个感知器无论得到的直线怎么动,都不可能完全正确的将三角形与圆形区分出来,那么我们很容易想到用多个感知器来进行组合,以便获得更大的分类问题,好的,下面我们上图,看是否可行:

好的,我们已经得到了多感知器分类器了,那么它的分类能力是否强大到能将非线性数据点正确分类开呢~我们来分析一下:
我们能够得到
哎呀呀,不得了,这个式子看起来非常复杂,估计应该可以处理我上面的情况了吧,哈哈哈哈~不一定额,我们来给它变个形.上面公式合并同类项后等价于下面公式:
啧啧,估计大家都看出了,不管它怎么组合,最多就是线性方程的组合,最后得到的分类器本质还是一个线性方程,该处理不了的非线性问题,它还是处理不了。
就好像下图,直线无论在平面上如果旋转,都不可能完全正确的分开三角形和圆形点:
既然是非线性问题,总有线性方程不能正确分类的地方~
那么抛开神经网络中神经元需不需要激活函数这点不说,如果没有激活函数,仅仅是线性函数的组合解决的问题太有限了,碰到非线性问题就束手无策了.那么加入激活函数是否可能能够解决呢?
在上面线性方程的组合过程中,我们其实类似在做三条直线的组合,如下图:

下面我们来讲一下激活函数,我们都知道,每一层叠加完了之后,我们需要加入一个激活函数(激活函数的种类也很多,如sigmod等等~)这里就给出sigmod例子,如下图:

通过这个激活函数映射之后,输出很明显就是一个非线性函数!能不能解决一开始的非线性分类问题不清楚,但是至少说明有可能啊,上面不加入激活函数神经网络压根就不可能解决这个问题~
同理,扩展到多个神经元组合的情况时候,表达能力就会更强~对应的组合图如下:(现在已经升级为三个非线性感知器在组合了)

跟上面线性组合相对应的非线性组合如下:

这看起来厉害多了,是不是~最后再通过最优化损失函数的做法,我们能够学习到不断学习靠近能够正确分类三角形和圆形点的曲线,到底会学到什么曲线,不知道到底具体的样子,也许是下面这个~

那么随着不断训练优化,我们也就能够解决非线性的问题了~
所以到这里为止,我们就解释了这个观点,加入激活函数是用来加入非线性因素的,解决线性模型所不能解决的问题。
常用激活函数
激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。
(1) 线性函数 ( Liner Function )

(2) 斜面函数 ( Ramp Function )

(3) 阈值函数 ( Threshold Function )


图2 . 阈值函数图像
以上3个激活函数都是线性函数,下面介绍两个常用的非线性激活函数。
(4) S形函数 ( Sigmoid Function )

该函数的导函数:

(5) 双极S形函数

该函数的导函数:

S形函数与双极S形函数的图像如下:

图3. S形函数与双极S形函数图像
双极S形函数与S形函数主要区别在于函数的值域,双极S形函数值域是(-1,1),而S形函数值域是(0,1)。
由于S形函数与双极S形函数都是可导的(导函数是连续函数),因此适合用在BP神经网络中。(BP算法要求激活函数可导)
(5) 双曲正切函数
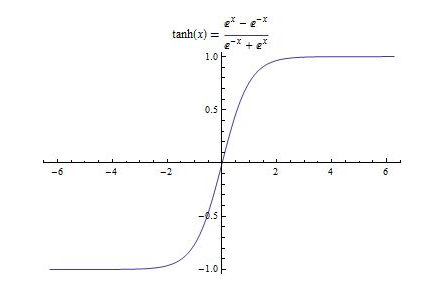
该函数的导函数:
(6)ReLu(Rectified Linear Units)函数
- Noise ReLU max(0, x+N(0, σ(x)).
该函数的导函数:
g(x)'=0或1

(7)maxout 函数


这里的W是3维的,尺寸为d*m*k,其中d表示输入层节点的个数,m表示隐含层节点的个数,k表示每个隐含层节点对应了k个”隐隐含层”节点,这k个”隐隐含层”节点都是线性输出的,而maxout的每个节点就是取这k个”隐隐含层”节点输出值中最大的那个值。因为激发函数中有了max操作,所以整个maxout网络也是一种非线性的变换。

补充:在ImageNet Classification with Deep Convolutional Neural Networks的论文中其解释了
RELU取代sigmoid 和tanh函数的原因是在求解梯度下降时RELU的速度更快,在大数集下会节省训练的时间
在这里指出sigmoid和tanh是饱和非线性函数,而RELU是非饱和非线性函数。
对于这个概念我不是很明白,有兴趣的童鞋可以去google一下,百度上是没有的。。。
20160515补充
PRELU激活函数
PReLU激活
PReLU(Parametric Rectified Linear Unit), 顾名思义:带参数的ReLU。二者的定义和区别如下图:

如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。 有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
PReLU的几点说明
(1) PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
(2) BP更新ai时,采用的是带动量的更新方式,如下图:
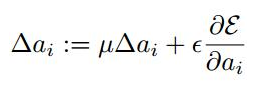
上式的两个系数分别是动量和学习率。
需要特别注意的是:更新ai时不施加权重衰减(L2正则化),因为这会把ai很大程度上push到0。事实上,即使不加正则化,试验中ai也很少有超过1的。
(3) 整个论文,ai被初始化为0.25。
参见《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》.
这篇蛮好:http://blog.csdn.net/cyh_24/article/details/50593400
日常 coding 中,我们会很自然的使用一些激活函数,比如:sigmoid、ReLU等等。不过好像忘了问自己一()件事:
- 为什么需要激活函数?
- 激活函数都有哪些?都长什么样?有哪些优缺点?
- 怎么选用激活函数?
本文正是基于这些问题展开的,欢迎批评指正!

(此图并没有什么卵用,纯属为了装x …)
Why use activation functions?
激活函数通常有如下一些性质:
- 非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
- 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
- : 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
- 输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
这些性质,也正是我们使用激活函数的原因!
Activation Functions.
Sigmoid

Sigmoid 是常用的非线性的激活函数,它的数学形式如下:
正如前一节提到的,它能够把输入的连续实值“压缩”到0和1之间。
特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
sigmoid 函数曾经被使用的很多,不过近年来,用它的人越来越少了。主要是因为它的一些 缺点:
- Sigmoids saturate and kill gradients. (saturate 这个词怎么翻译?饱和?)sigmoid 有一个非常致命的缺点,当输入非常大或者非常小的时候(saturation),这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。
- Sigmoid 的 output 不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. elementwise in ),那么 计算出的梯度也会始终都是正的。
当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
tanh
tanh 是上图中的右图,可以看出,tanh 跟sigmoid还是很像的,实际上,tanh 是sigmoid的变形:
与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好(毕竟去粗取精了嘛)。

ReLU
近年来,ReLU 变的越来越受欢迎。它的数学表达式如下:
很显然,从图左可以看出,输入信号<0时,输出都是0,输入信号大于0的情况下,输出等于输入。w是二维的情况下,使用ReLU之后的效果如下:

ReLU 的优点:
- Krizhevsky et al. 发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多(看右图)。有人说这是因为它是linear,而且 non-saturating
- 相比于 sigmoid/tanh,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。
ReLU 的缺点: 当然 ReLU 也有缺点,就是训练的时候很”脆弱”,很容易就”die”了. 什么意思呢?
举个例子:一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。
如果这个情况发生了,那么这个神经元的梯度就永远都会是0.
实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。
当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
Leaky-ReLU、P-ReLU、R-ReLU
Leaky ReLUs: 就是用来解决这个 “dying ReLU” 的问题的。与 ReLU 不同的是:
这里的 是一个很小的常数。这样,即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。

关于Leaky ReLU 的效果,众说纷纭,没有清晰的定论。有些人做了实验发现 Leaky ReLU 表现的很好;有些实验则证明并不是这样。

Parametric ReLU: 对于 Leaky ReLU 中的,通常都是通过先验知识人工赋值的。
然而可以观察到,损失函数对的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?
Kaiming He的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》指出,不仅可以训练,而且效果更好。
公式非常简单,反向传播至未激活前的神经元的公式就不写了,很容易就能得到。对的导数如下:
原文说使用了Parametric ReLU后,最终效果比不用提高了1.03%.
Randomized ReLU:
Randomized Leaky ReLU 是 leaky ReLU 的random 版本 ( 是random的).
它首次试在 kaggle 的NDSB 比赛中被提出的。
核心思想就是,在训练过程中, 是从一个高斯分布 中 随机出来的,然后再测试过程中进行修正(有点像dropout的用法)。
数学表示如下:

在测试阶段,把训练过程中所有的 取个平均值。NDSB 冠军的 是从 中随机出来的。那么,在测试阶段,激活函数就是就是:
看看 cifar-100 中的实验结果:

Maxout

Maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start-of-art的识别率。
Maxout 公式如下:
假设 是2维,那么有:
可以注意到,ReLU 和 Leaky ReLU 都是它的一个变形(比如, 的时候,就是 ReLU).
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。作者从数学的角度上也证明了这个结论,即只需2个maxout节点就可以拟合任意的凸函数了(相减),前提是”隐隐含层”节点的个数可以任意多.

所以,Maxout 具有 ReLU 的优点(如:计算简单,不会 saturation),同时又没有 ReLU 的一些缺点 (如:容易Go die)。不过呢,还是有一些缺点的嘛:就是把参数double了。
还有其他一些激活函数,请看下表:


How to choose a activation function?
怎么选择激活函数呢?
我觉得这种问题不可能有定论的吧,只能说是个人建议。
如果你使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让你的网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
友情提醒:最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
还有,通常来说,很少会把各种激活函数串起来在一个网络中使用的。
Reference
[1]. http://www.faqs.org/faqs/ai-faq/neural-nets/part2/section-10.html
[2]. http://papers.nips.cc/paper/874-how-to-choose-an-activation-function.pdf
[3]. https://en.wikipedia.org/wiki/Activation_function
[4]. http://cs231n.github.io/neural-networks-1/
在人工神经网络(ANN)中,Softmax通常被用作输出层的激活函数。这不仅是因为它的效果好,而且因为它使得ANN的输出值更易于理解。同时,softmax配合log似然代价函数,其训练效果也要比采用二次代价函数的方式好。
1. softmax函数及其求导
softmax的函数公式如下:
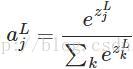
其中,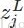
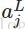
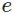
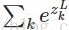
softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
另外,softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
由于softmax在ANN算法中的求导结果比较特别,分为两种情况。希望能帮助到正在学习此类算法的朋友们。求导过程如下所示:
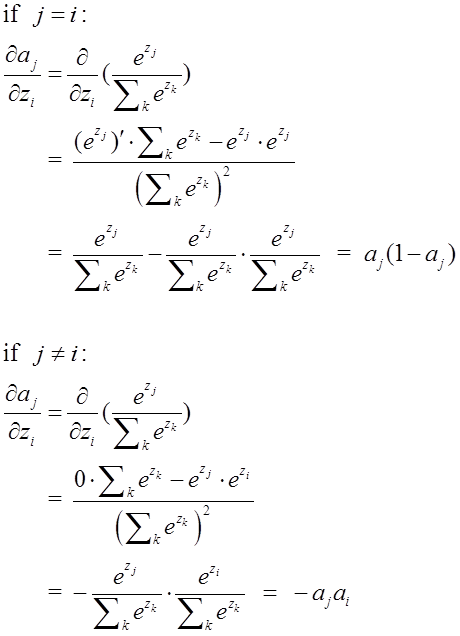
2. softmax配合log似然代价函数训练ANN
在上一篇博文“交叉熵代价函数”中讲到,二次代价函数在训练ANN时可能会导致训练速度变慢的问题。那就是,初始的输出值离真实值越远,训练速度就越慢。这个问题可以通过采用交叉熵代价函数来解决。其实,这个问题也可以采用另外一种方法解决,那就是采用softmax激活函数,并采用log似然代价函数(log-likelihood cost function)来解决。
log似然代价函数的公式为:
其中,
我们来简单理解一下这个代价函数的含义。在ANN中输入一个样本,那么只有一个神经元对应了该样本的正确类别;若这个神经元输出的概率值越高,则按照以上的代价函数公式,其产生的代价就越小;反之,则产生的代价就越高。
为了检验softmax和这个代价函数也可以解决上述所说的训练速度变慢问题,接下来的重点就是推导ANN的权重w和偏置b的梯度公式。以偏置b为例:

同理可得:
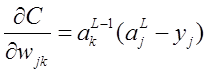
从上述梯度公式可知,softmax函数配合log似然代价函数可以很好地训练ANN,不存在学习速度变慢的问题。
补充一份ELU,因为我发现我的实际检测架构中,暂时不能 实现BN因此,替换ReLU为ELU
blog.csdn.net/mao_xiao_feng/article/details/53242235?locationNum=9&fps=1
转自:
论文下载:
一、简介
ELU的表达式:
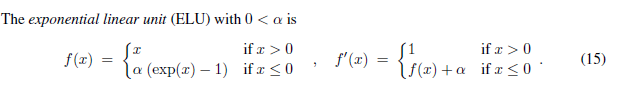
四种激活函数(ELU,LReLU,ReLU,SReLU)比较图:
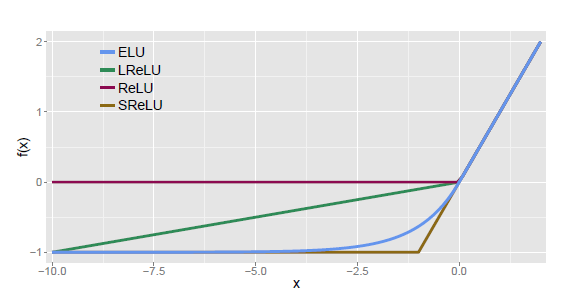
ELU通过在正值区间取输入x本身减轻了梯度弥散问题(x>0区间导数处处为1),这一点特性这四种激活函数都具备。四者当中只有ReLU的输出值没有负值,所以输出的均值会大于0,当激活值的均值非0时,就会对下一层造成一个bias,如果激活值之间不会相互抵消(即均值非0),会导致下一层的激活单元有bias shift。如此叠加,单元越多时,bias shift就会越大。相比ReLU,ELU可以取到负值,这让单元激活均值可以更接近0,类似于Batch Normalization的效果但是只需要更低的计算复杂度。虽然LReLU和PReLU都也有负值,但是它们不保证在不激活状态下(就是在输入为负的状态下)对噪声鲁棒。反观ELU在输入取较小值时具有软饱和的特性,提升了对噪声的鲁棒性。
二、自然梯度
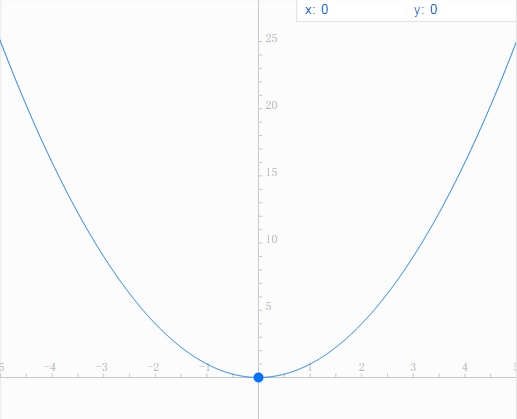
在描述自然梯度之前,让我们先来看普通梯度,设f(x)=x^2
参数x的变化量和f的变化量可以在一个二维平面坐标系下度量,在这种情形下,可以求得普通的梯度。
但是上述情况基于一个事实:x的变化所引起的f的变化是在一个度量系下的,我们使用了一组正交并且平直坐标系去描述这种变化,数学上把这样的空间称作欧几里德空间,以往我们接触的问题都可以在欧几里德空间下解决(函数优化、求解平面几何等等)
但是在概率分布问题下,欧几里德空间就不好解决了,来举个例子:
在神经网络当中,给定一组数据{x1,x2,x3,……,xN}和一个概率分布模型p(x;W),其中xi={样本zi,标签yi}两部分构成,我们最后要做的就是估计一个W',使得p(x;W')和p(x;W)尽可能的相近。假设对于单个样本x而言,它的概率服从W的一个函数,这个问题是在欧几里德空间可解的
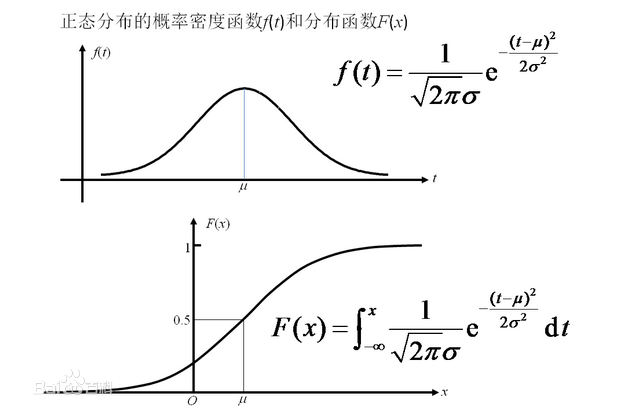
如下图:当我们确定了正态分布的μ和σ时,可以对单个样本给出它的分布函数和概率密度函数
但是我们要求解的并不是这个样本,而是整个数据集的概率分布,这个概率分布随着参数的变化实际上并不能用一个函数来表达,说得更专业一点就是无法在欧几里德空间解这个问题。两个概率分布的距离,在统计学中,是以KL散度来表达的,了解KL散度需要涉及到信息熵和相对熵的问题。http://www.cnblogs.com/hxsyl/p/4910218.html已经给了详细的介绍。
因此可以写出一个分布参数变化前后,相对应的KL散度
最终问题就变成最小化这个KL散度的问题。(当我们不停的迭代到参数接近模型自身参数的时候,KL散度就达到最小了)
KL散度随着参数变化有最大的变化率,这样决定的梯度,就称为自然梯度了
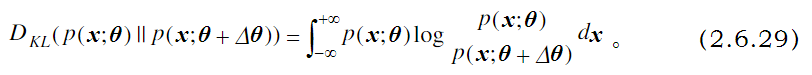
三、黎曼流形空间
上述KL散度随参数变化的问题,是在黎曼流形空间上的问题。
流形(Manifold)可以理解为受一定约束的某个(一维或多维)变量所有可能状态的集合。其数学定义是:流形是一类拓扑空间,其中每个点都有邻域,而这种邻域与R^n中的单位开球在拓扑上同胚。简单地说,流型从它每个点的邻域来看和 Euclid 空间没有不同;但从总体来看,流形可以是某种“弯曲”的空间,和“平直”的 Euclid 空间不一定相同。三维空间中的球面是流形的一个例子。球面上任何一条经线或纬线是一个子流形。基于球面建立的几何学与 Euclid 几何学是不同的。
事实上,我们不一定要关注流形是什么,我们只需要一个可以表示自然梯度的公式。(以下的推导细节都不重要,你只需要知道最后的形式)

通过这一步,可以进而推导出自然梯度的普通梯度表示:
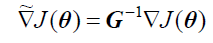
最后的公式是我们关注的,它居然和普通梯度仅仅相差了一个矩阵!!
四、fisher信息矩阵
从矩阵的表达形式上来看,它表示了对数似然函数一阶导数的二阶矩。我们希望似然函数的导数更偏离均值,对应的似然函数就越陡峭,这是有利于我们做似然估计的,于是fisher信息又有一种更直观的表达:它对应于我们对于参数估计的准确度,换句话说,就是在一次似然估计中,并不是所有的样本可以全部被这次估计所用,fisher信息,代表了可以用于似然估计的那部分信息。
把所有推理连贯一下:
自然梯度意味着使KL散度变化率最大=>KL散度的变化代表了似然估计的变化=>假设参数的改变,导致了似然函数发生了某一个改变=>这个改变仅仅导致了对于似然估计有用的那部分信息在似然函数里产生的变化。
不看数学的推导,这个公式在实际当中的意义似乎也说得通!
五、ELU的提出
再回到论文,文中提出bias shift就是激活值均值在权重更新的时候的改变(因为普通梯度的更新不会考虑数据的分布)而自然梯度会对这种bias shift进行纠正,如何纠正的,文中用了一个例子以及一系列的数学推导证明了,大致过程就是在原网络上增加了一个bias单元,用自然梯度求解时,发现新增单元会导致fisher信息矩阵上增加一行(用b表示),最终这一行b会影响bias权重和原始权重的更新。
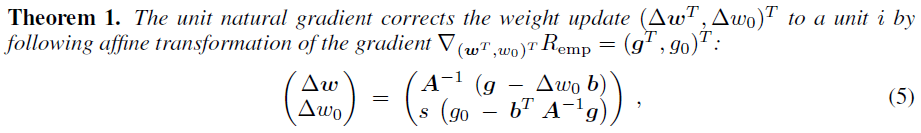
这种影响作者把它称作bias shift correction,它校正了所有的权值更新,去抵消这种bias shift
作者基于这个又提出了一种想法:既然要让激活值的均值不变,是否可以一直让激活函数的均值保持在0,这样就不会发生bias shift,即可以用普通梯度代替自然梯度,最终其效果等同于使用了自然梯度?
最后ELU诞生了,它的形式是
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
ELU实现了两个优点:
1、将前面单元输入的激活值均值控制在0
2、让激活函数的负值部分也可以被使用了(这意思应该是之前的激活函数,负值部分几乎不携带信息,特别是ReLU)