Python正则_整理
(声明:本教程仅供本人学习使用,如有人使用该技术触犯法律与本人无关)
正则的规则:
字符串:re 模块
patter:写的是规则’ ’
str : 要验证的字符串
flags=0 : 匹配模式 re.I L M S U X
re.match( )

re.search( )

findall( )

单个匹配
. : 代表的是除了换行符(\n)以外的任意一个字符
[内容]:匹配中括号中任意一个字符
[a-z] : 匹配小写字母
[A-Z] :匹配大写字母
[0-9]:匹配数字
[a-zA-Z0-9 .] :匹配 字母数字空格点
***{注}***: “ ^ ” 在 [ ] 中写代表非,不匹配 [ ] 的字符

\d : 匹配所有的数字,同[0-9]
\D : 匹配非数字,同[^0-9]
\w : 匹配数字字母下划线
\W:匹配除数字字母下划线以外的
\s:匹配所有的空白符,\t,\n,\r,空格
\S:匹配所有的非空白符
\ : 可以转义,不让他有特殊意义
边界字符
内容:在中括号外部,必须以后面的东西开头
内容$:必须以‘内容’结尾
(只能匹配整个字符串的,re.M失效)
\A内容 : 开头
内容\Z : 结尾
内容\b 或者 r’\b’ : (有边界可以匹配成功)匹配一个单词
\B :(没有边界才可以匹配成功)
多个匹配
() :组,一组数据,作为整体去匹配
| :或,
- :匹配0个或任意多个字符(贪婪匹配)
?:匹配0个或任意1个字符(非贪婪匹配)
+:匹配1个或者多个字符(贪婪匹配)
{x}:一次匹配x个字符
{x,y}:匹配为x-y内的字符数 都可以(y不写,默认无上限)
在* + 后加?可以解决贪婪匹配,即能尽量少匹配就少
正则表达式–字符串
(可以将字符串封装成一个对象)
re.compile(规则,匹配模式)(正则规则对象)
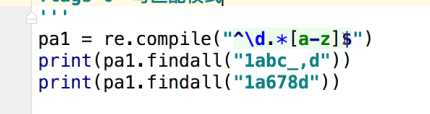
对应的方法
group() 返回被 RE 匹配的字符串。
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
拆分替换

正则分组
| 字符 | 含义 | 示例 | 结果 | 注意 |
|---|---|---|---|---|
| (…) | 括号内为一组;分组有编号,从1开始算起;分组作为一个整体只在分组内部有效 | re.findall('(ab+?)(bb)','abbb') |
[('ab', 'bb')] |
|
| (?P…) | 除编号外的另一个分组名 | |||
| (<number>) | 引用编号为的分组匹配的字符串,通常指分组的下标 | |||
| (?P) | 给分组起别名 | re.match('(?P<dwl>ab+?)','abbb').group('dwl') |
ab |
|
| (?: …) | 非分组模式的匹配 | re.findall('(?:ab+?)(?:bb)','abbb') |
['abbb'] |
|
| (?P=name) | 对指定的组反向的引用,以前面的以name为名称的组匹配的文本为分组内容,匹配后面的内容 | (示例:‘[email protected]’)'(?P<number>[1-9]){5}@(?P<letters>[a-z])+\.(?P=letters)+') |
'[email protected]' |
|
| (?=…) | 当该表达式匹配成功的时候,它的前面的表达式才会匹配. | re.match('\w+@(?=\d+)','abcds@123456').group() |
abcds@ |
|
| (?!..) | 当该表达式不匹配的时候,它的前面的表达式都会匹配成功 | re.match('\w+@(?!\d+)','abcds@dfa').group() |
abcds@ |
|
| (?<=…) | 匹配以…开始的后面部分的字串,只能是固定的长度,也就是一个明确的表达式. | re.match('(?<=abc)def', 'abcdef') / re.search('(?<=abc)def', 'abcdef') |
None / <_sre.SRE_Match object; span=(3, 6), match='def'> |
说明:该模式不能于一个字符串的开始 |
| (?<!..) | 匹配不是以…开始的后面部分的字串.只能是固定的长度 | re.match('(\w+)(?<!zhang)san', 'mylisan').group() |
mylisa |
|
| (?(id/name)yes | no) | 如果给定的 id 或 name 存在,将会尝试匹配 yes-pattern ,否则就尝试匹配 no-pattern,no-pattern 可选,也可以被忽略。比如, (<)?(\w+@\w+(?:.\w+)+)(?(1)>|$) 是一个email样式匹配,将匹配 ‘[email protected]’ 或’[email protected]’ ,但不会匹配 ‘<[email protected]’ ,也不会匹配 ‘[email protected]>’ | re.search(r'(\d){0,}abc(?(1)\d|abc)','abcabc') / re.searcj(r'(?P<lefg_bracket>\()?\w+(?(lefg_bracket)\)|$)', '(abdcd') |
abcabc / None |
| (?P#…) | 注释,#后面的东西会被注释 | |||
| (?aiLmsux) | ( ‘a’, ‘i’, ‘L’, ‘m’, ‘s’, ‘u’, ‘x’ 中的一个或多个) 这个组合匹配一个空字符串;这些字符对正则表达式设置以下标记 re.A (只匹配ASCII字符), re.I (忽略大小写), re.L (语言依赖), re.M (多行模式), re.S (点dot匹配全部字符), re.U (Unicode匹配), and re.X (冗长模式) | (re.findall('((?a)\d+)','a232') |
['232'] |
