想要学会算法时间复杂度,那么就要先弄清楚几个概念。
- 什么是算法时间复杂度?
- 它有什么用呢?
- 写法记作 T(n)=O(f(n))
- T(n):语句执行的总次数关于n的函数
- n:问题规模
- f(n):问题规模n的某个函数
- 用O()来体现算法时间复杂度的记法
时间复杂度的定义是:如果一个问题的规模是n,解决这一问题所需算法所需要的时间是n的一个函数T(n),则T(n)称为这一算法的时间复杂度。
所谓算法时间复杂度就是一句话:算法中基本操作的执行次数。既然是T(n)的函数,随着模块n的增大,算法执行的时间的增长率和T(n)的增长率成正比,所以T(n)越小,算法的时间复杂度越低,算法的效率越高。
那么它有什么用呢?刚才也说了,可以通过f(n)的函数关系来评估算法的效率问题,说白了就是通过时间复杂度来看算法的好坏。
值得注意的是:有的算法中基本操作执行次数不仅仅跟初始输入的数据规模(n)有关,还和数据本身有关。例如一些排序算法,同样n个待处理数据,数据初始有序性不同,基本操作执行次数也会不同。如果算法中有特殊要求,一般依照使得基本操作执行次数最多的输入来计算时间复杂度,即将最坏的情况最为算法时间复杂度的度量。
常见的是按复杂度的大小
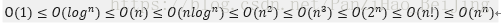
常见的时间复杂度
有的人会对log2 n与log n做对比,不理解这里为什么不一样,其实这两个是一样的也就是图中第2个和第4个都是可以替换以2为底的对数形式。
对数时间
主条目:对数时间
若算法的T(n) = O(log n),则称其具有对数时间。由于计算机使用二进制的记数系统,对数常常以2为底(即log2 n,有时写作lg n)。然而,由对数的换底公式,loga n和logb n只有一个常数因子不同,这个因子在大O记法中被丢弃。因此记作O(log n),而不论对数的底是多少,是对数时间算法的标准记法。————维基
如何计算或者推导时间复杂度呢##
我们来分析一下常规做法:
- 确定算法中的基本操作以及问题的规模。
- 根据基本操作执行情况计算出规模n的函数f(n),并确定时间复杂度为T(n)=O( f(n)中增长最快的项/此项的系数 ).
那么是什么意思呢?记住这个利器,这三句话即可。
- 用常数1替换所有加法常数。
- 在修改后的运行次数的函数中,只保留最高阶项。
- 如果最高阶项不是1(例如O(1)),则把该项的系数除掉,得到O
开始实战##
这不是演戏,这不是演习,实战之后就可以完全掌握概念了。
第一类
看下面一对代码,进行分析:

int i=0,n=100; /*执行了一次*/
i=n/2+n; /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
那么不难分析出这段代码一共执行了3次,那么时间复杂度就是O(3),对吧?是不是很简单,如果真的是这样,那就错了,看我们的利器第一句,它是f(n)=3,所以应该把3改为1,即O(1)。那么看下面这个:
int i=0,n=100; /*执行了一次*/
i=n/2+n; /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
printf("i=%d",i); /*执行了一次*/
这段代码一共执行了7次,那么时间复杂度为多少呢,经过上面的坑,这个应该没问题了,对,f(n)=7,把7改为1,即O(1)。那么我们可以得知,这种代码是具有恒定的执行时间的,也就是代码不会因为问题规模n的变化而发生变化,所以我们都记为O(1).
第二类
void fun(int n)
{
int i=1,j=100;
while(i<n)
{
++j;
i+=2;
}
}
这个显然n确定以后,循环的开始结束都是与i有关的,且每次自增2,假设m次后结束循环,那么i应该等于1+2m,那么就有n=1+2m,因为我们要是执行次数,也就是解得m=(n-1)/2,此时我们可以看出n/2增长的是最快的项,根据我们的法宝,我们需要把前面的系数除掉即可得到O,即(n/2)/(1/2)=n,得O(n).
有的为了更严谨的推导,会对上面的式子进行修改,即1+2m+K=n ,K为一个常数,因为循环的结束的时候往往i是稍稍大于n的,所以用一个K来修正这个式子,m=(n-1-K)/2,当然因为K为常数,所以不会影响最终结果,毕竟有一个增长更快的家伙把它的影响干掉了。
做到这,是不是感觉很简单了呢?那么我们趁热打铁进行下一个。
int i=1;
while(i<n)
{
i=i*2;
}
推导时间复杂度,最重要的就是要分析算法的执行次数。那么这段程序怎么分析呢?试着自己分析一下,再来看吧。好啦,i起始值为1,每次都乘2,也就意味着每次都会距离n近一些,那么什么时候超过n而终止循环呢?很简单就是i22222...*2>n,那么假设k次之后大于n,就有2^k=n,得出k=logn(上面说了还有些log2 n,都是一样的,以后都写最简形。)
马上就要成功了,主要是练就分析算法和推导的思路。再来一个:
int i,j,x=0;
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
x++;
}
这段代码不用多想就知道,外循环执行n次,内循环也是执行n,则O(n^2).那么这段呢?
int i,j,x=0;
for(i=0;i<n;i++)
{
for(j=i;j<n;j++)
x++;
}
由于当i=0,时内循环执行了n次,i=1时,执行了n-1次,...i=n-1时,执行了1次,那么总次数为 n+(n-1)+(n-2)+..+1=n(n+1)/2,那么就是n2/2,即O(n2).
到这里基础的就结束了,我想大家也应该能看懂了吧,当然还有一些比较复杂的算法,大家可以去自行试试,对于该文章不懂得可以在文章下面留言,看到了我会回复的。
最后给大家做个练习吧。
i++;
function(n) /* 方法function(n)为时间复杂度O(n)*/
int k,m;
while(k<n)
{
function(n);
k++;
}
for(k=0;k<n;k++)
{
for(m=k;m<n;m++)
{
/*时间复杂度为O(1)的序列*/
}
}
小试牛刀,检验成果吧,大家联系完这个,函数调用的时间复杂度也被你征服了,对于这个题可以在评论区留下你的答案,并和大家分享吧!