涉及知识:requests模块,Xpath,json模块,“ ”.join(str)等
一、分析网页(https://movie.douban.com/review/best/?start=0)
打开网页,按F12,打开“检查”:
(1)Network中返回的响应HTML代码如下图:
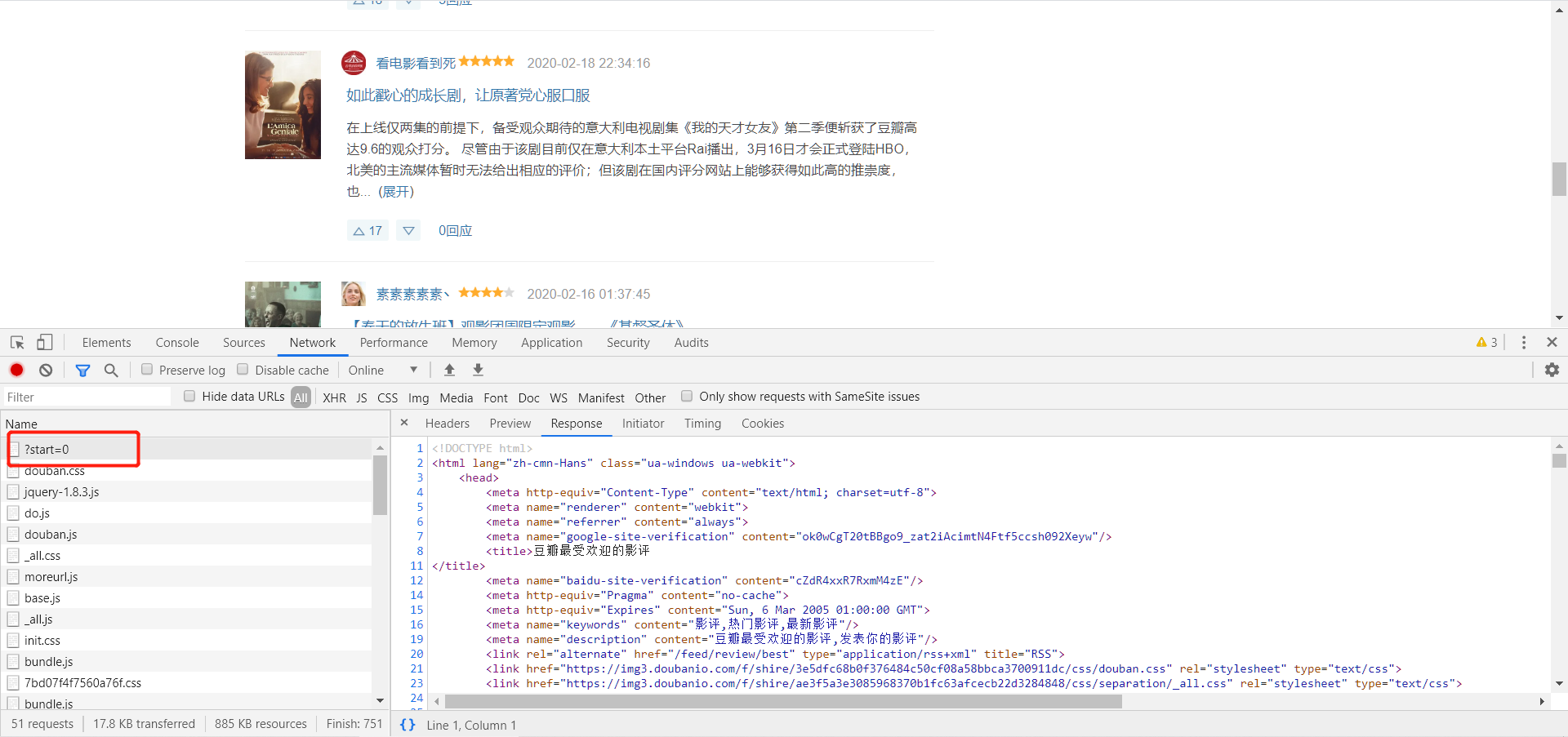
(2)Element中HTML代码如下图:
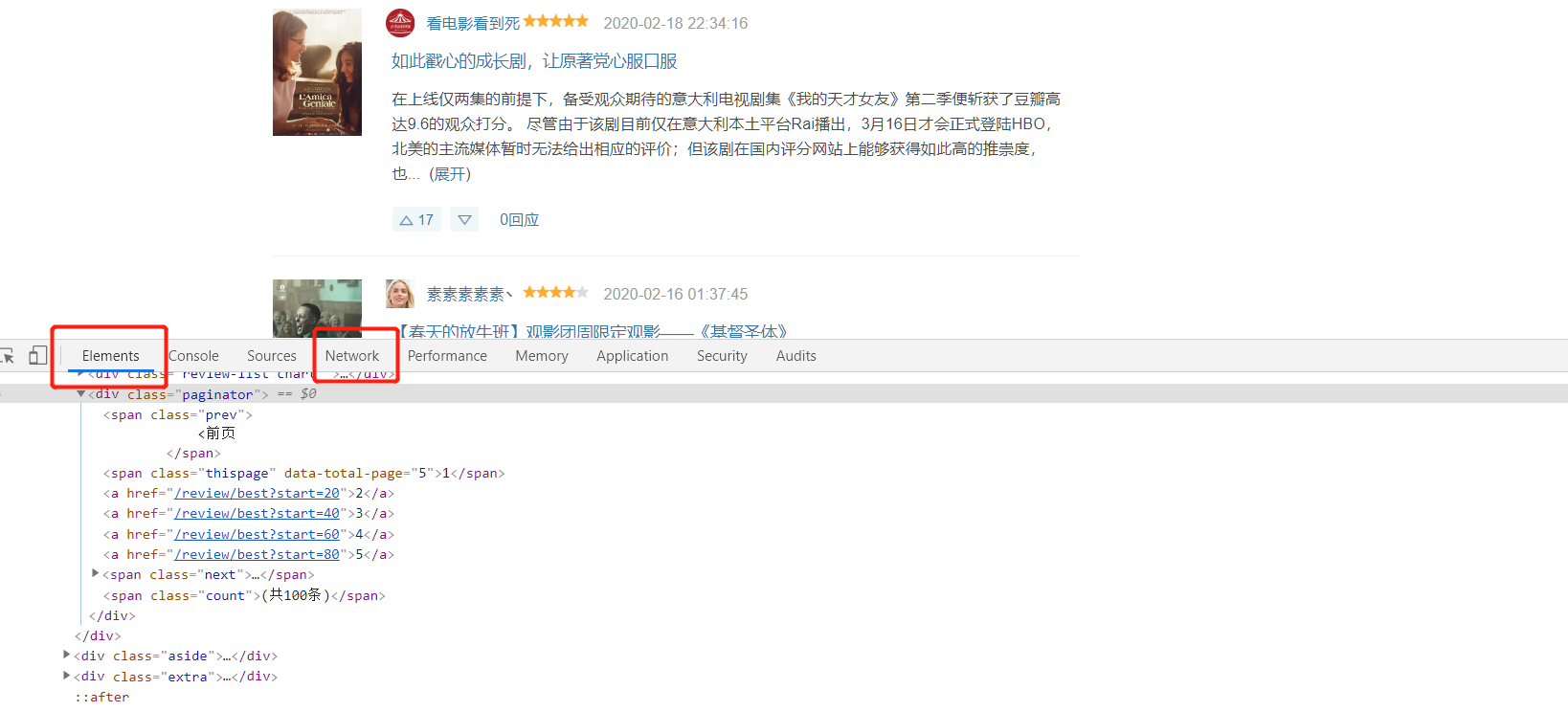
经过分析对比,发现Network中返回的HTML与Element中的相同,所以后边抓取数据时,可以根据Element中的HTML来写Xpath。
二、代码
代码逻辑:
1. 获取第一页的url地址:first_page_url
2. 发送请求,获取响应:def parse_url():pass
3. 提取目标数据:def get_content():pass
4. 保存数据:def save_content():pass
5. 构造下一页url地址,循环2-5步 while True:…… if ……:break
附上具体代码,与诸贤探讨,请来者不吝赐教。。。


1 """ 2 获取豆瓣影评上的每条影评名字,推荐人,影评内容,所有图片 3 """ 4 import requests 5 from lxml import etree 6 import json 7 8 9 class DoubanYingpingSpider(object): 10 def __init__(self): 11 self.url_temp = "https://movie.douban.com" 12 self.headers = { 13 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36"} 14 15 def parse_url(self, url): # 发送请求 16 print(url) 17 response = requests.get(url, headers=self.headers) 18 return response.content.decode() 19 20 def get_content_list(self, html_str):# 提取数据 21 22 html = etree.HTML(html_str) 23 div_list = html.xpath("//div[@class='review-list chart ']/div") 24 page_url_list = html.xpath("//div[@class='paginator']/a/@href") 25 # print(page_url_list) 26 content_list = [] 27 for div in div_list: 28 item = {} 29 item["title"] = div.xpath(".//div[@class='main-bd']/h2/a/text()") 30 item["content_url"] = div.xpath(".//div[@class='main-bd']/h2/a/@href") 31 item["author"] = div.xpath(".//header/a[@class='name']/text()") 32 item["img"], item["content"] = self.get_img_and_content_list(item["content_url"][0]) 33 content_list.append(item) 34 # print(item) 35 return content_list, page_url_list 36 37 def get_img_and_content_list(self, detail_url): # 获取单条影评内的数据 38 # 3.1当前影评的url地址 39 # 3.2 发送请求,获取响应 40 detail_html_str = self.parse_url(detail_url) 41 html = etree.HTML(detail_html_str) 42 43 # 3.3 提取数据 44 img = html.xpath("//div[@class='image-wrapper']/img/@src") 45 content = html.xpath("//div[@class='review-content clearfix']//text()") 46 content = "".join(content).replace('\n ', '').replace('\n ', '') # list转换为str 47 # print(type(content),content) 48 return img, content 49 50 def save_content_list(self, content_list): # 保存 51 52 with open("豆瓣最受欢迎的影评.txt", "a", encoding='utf-8') as f: 53 for content in content_list: 54 f.write(json.dumps(content, ensure_ascii=False, indent=4)) 55 f.write('\n\n') 56 f.write('*' * 50 + '\n') 57 print("保存成功!") 58 59 def run(self): # 实现主要逻辑 60 break_signal = 0 61 page_url_temp = '/review/best/?start=0' 62 while True: 63 # 1.page_url 64 page_url = self.url_temp + page_url_temp 65 66 # 2.发送请求,获取响应 67 html_str = self.parse_url(page_url) 68 69 # 3.提取数据 70 content_list, page_url_list = self.get_content_list(html_str) 71 # 3.1 当前影评的url地址 72 # 3.2 发送请求,获取响应 73 # 3.3 提取数据 74 # 4.保存 75 self.save_content_list(content_list) 76 77 # 5. 构造下一页的url地址,循环1-5 78 if break_signal < len(page_url_list): 79 page_url_temp = page_url_list[break_signal] 80 break_signal += 1 81 else: 82 break 83 84 85 if __name__ == '__main__': 86 douban_spider = DoubanYingpingSpider() 87 douban_spider.run()