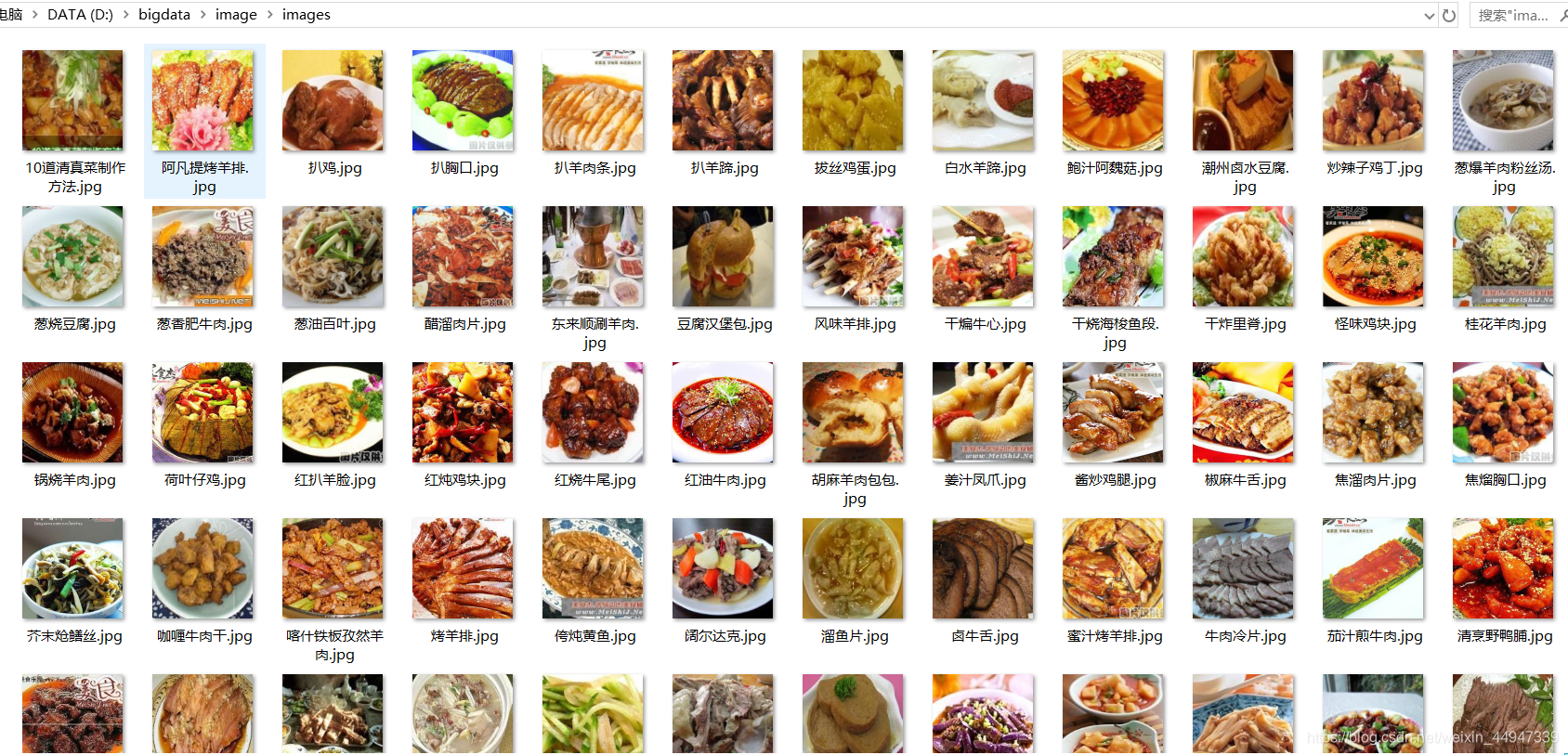
前言
Scrapy提供了一个 item pipeline ,来下载属于某个特定项目的图片。这条管道,被称作图片管道,在 ImagesPipeline 类中实现,提供了一个方便并具有额外特性的方法,来下载并本地存储图片。
开发环境及工具介绍
python 3.7
scrapy 1.7.3
xpath选择器
软件:pycharm
一、创建项目
在terminal里输入
scrapy startproject image #创建爬虫项目
scrapy genspider photo meishij.com #创建爬虫文件
这样项目就建好了。
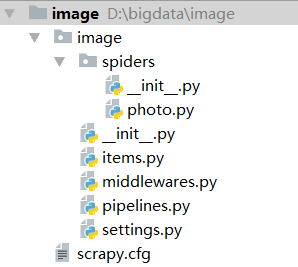
项目结构如下:
二、编写 item.py
Item使用简单的class定义语法以及 Field 对象来声明。
import scrapy
class ImageItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
image_name = scrapy.Field()
三、编写爬虫文件 photo.py
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
import scrapy
from image.items import ImageItem
class PhotoSpider(scrapy.Spider):
name = 'photo'
allowed_domains = ['meishij.net']
start_urls = ['https://www.meishij.net/china-food/caixi/qingzhencai/'
def parse(self, response):
item = ImageItem()
image_urls = response.xpath('//*[@id="listtyle1_list"]/div/a/img/@src').extract()
image_name = response.xpath('//*[@id="listtyle1_list"]/div/a/div/div/div[1]/strong/text()').extract()
for i in range(0, len(image_name)):
item['image_urls'] = image_urls[i]
item['image_name'] = image_name[i]
yield item
四、编写管道文件pipelines.py
import scrapy
import re
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
image_url = item['image_urls']
yield scrapy.Request(image_url,meta={'name':item['image_name']})
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
def file_path(self, request, response=None, info=None):
name = request.meta['name'] # 接收上面meta传递过来的图片名称
name = re.sub(r'[?\\*|“<>:/]', '', name) # 过滤windows字符串,不经过这么一个步骤,你会发现有乱码或无法下载
filename= name +'.jpg' #添加图片后缀名
return filename
方法解析:
- get_media_requests(item, info)
在工作流程中可以看到,管道会得到图片的URL并从项目中下载。为了这么做,你需要重写 get_media_requests() 方法,并对各个图片URL返回一个Request。 - item_completed(results, items, info)
当一个单独项目中的所有图片请求完成时, ImagesPipeline.item_completed() 方法将被调用。默认情况下, item_completed() 方法返回item。 - file_path(self, request, response=None, info=None)
通过重写file_path方法,可以将图片以原来的格式和原图片名称进行保存。
说明:我这里是爬取了网页中与图片对应的名字!
五、配置文件 settings.py
IMAGES_STORE ='images'#保存图片的路径,这里保存在项目里的images文件夹(自动创建)
ITEM_PIPELINES = {
'image.pipelines.ImagePipeline': 300, #开始pipelines
}
六、启动项目
scrapy crawl photo
我们就可以看到项目里多了一个images的文件夹
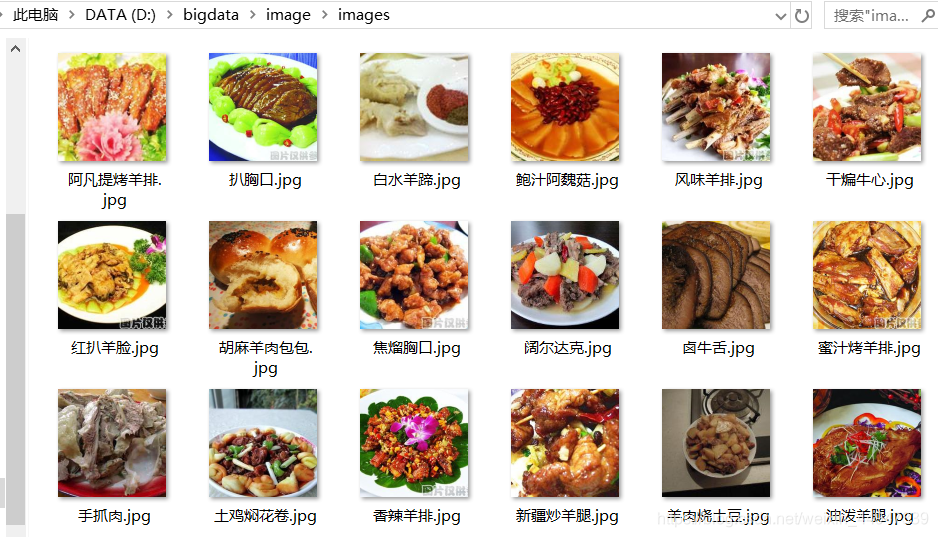
爬取图片的全过程就结束了!
当然你也可以爬取多页的图片
只需要修改pohot.py文件就可以了
import scrapy
from image.items import ImageItem
class PhotoSpider(scrapy.Spider):
name = 'photo'
allowed_domains = ['meishij.net']
start_urls = ['https://www.meishij.net/china-food/caixi/qingzhencai/']
page = 1
def parse(self, response):
item = ImageItem()
image_urls = response.xpath('//*[@id="listtyle1_list"]/div/a/img/@src').extract()
image_name = response.xpath('//*[@id="listtyle1_list"]/div/a/div/div/div[1]/strong/text()').extract()
for i in range(0, len(image_name)):
item['image_urls'] = image_urls[i]
item['image_name'] = image_name[i]
yield item
self.page +=1
if self.page<5: #只爬前5页
url="https://www.meishij.net/china-food/caixi/qingzhencai/?&page="+str(self.page)
yield scrapy.Request(url,callback=self.parse)
运行项目
scrapy crawl photo