编译原理引论
(一)认识编译程序
什么是编译程序?
这要从翻译程序、解释程序以及编译程序的联系与区别说起:
翻译程序:把一种语言程序(称为源语言程序)等价地转换成另一种语言程序(称为目标语言程序)的程序。

编译程序是一种特殊的翻译程序,编译程序特指把某一种高级语言程序等价地转换成另一种低级语言程序(如汇编语言或者机器语言程序)的程序。

在翻译程序中,有一种方式和编译程序不太一样,即解释程序:把源语言写的源程序作为输入、但不产生目标程序,而是边解释边执行源程序本身。
根据不同的用途和侧重,编译程序还可进一步分类。
- 诊断编译程序:专门用于帮助程序开发和调试的编译程序称为诊断编译程序
- 优化编译程序:着重于提髙目标代码效率的编译程序
- 如果一个编译程序产生不同于其宿主机的机器代码, 则称它为交叉编译程序
- 如果不需重写编译程序中与机器无关的部分就能改变目标机,则称该编译程序为可变目标编译程序
编译程序运行的平台叫做
宿主机
编译后产生的目标代码运行的平台叫做目标机
通常这两种平台在同一台机器上。
(二)编译过程概述
1、阶段划分
编译过程是一种语言的翻译过程,它的工作过程类似于外文的翻译过程。
比如英文句子翻译成中文句子的大致过程是:
- 词法分析:根据英语的词法规则,从由字母、空格字符和各种标点符号所组成的字符串中识别出一个一个的英文单词。
- 语法分析:根据英语的语法规则,对词法分析后的单词串进行分析、识别,并做语法正确性检查,看其是否组成一个符合英语语法的句子。
- 语义分析:对正确的英文句子分析其含义并用汉语表示出来.
- 根据上下文的关系以及汉语语法的有关规则对词句做必要的修饰工作。
- 最后翻译成中文。
编译过程一般分为以下五个阶段(与自然语言翻译过程对比):
- 词法分析
- 语法分析
- 语义分析与中间代码产生
- 优化
- 目标代码生成
(1)词法分析(扫描器)
-
任务:源程序 → 单词符号串 (线性分析)。 即输人源程序,对构成源程序的字符串进行扫描和分解,识别出一个个的单词(亦称单词符号或简称符号),如基本字、标识符、常数、算符和界符(标点符号、左右括号等等)。
-
依据:语言的词法规则
-
描述词法规则的工具:正则式、正则文法、有限自动机
(2)语法分析
- 任务:单词符号串 → 各类语法范畴 (层次结构分析)。 即在词法分析的基础上,根据语言的语法规 则,把单词符号串分解成各类语法单位(语法范畴),如“短语”、“子句”、“句子”(“语句”)、 “程序段”和“程序”等。通过语法分析,确定整个输人串是否构成语法上正确的“程序”
- 依据:语言的语法规则
- 描述语法规则的工具:上下文无关文法、确定的下推自动机
(3)语义分析与中间代码产生
- 任务:语法范畴 → 初步翻译、产生中间代码。 即对语法分析所识别出的各类语法范畴,分析其含义,并进行初步翻译(产生中间代码)。这一阶段通常包括两个方面的工作。首先,对每种语法范畴进行静态语义检查,例如,变量是否定义、类型是否正确等等。如果语义正确,则进行另一方面工作,即进行中间代码的翻译。
- 中间代码:独立于具体硬件的记号系统,四元式、三元式、逆波兰式等。(介于高级语言和低级语言之间)
- 依据:语言的语义规则
- 描述语义规则的工具:属性文法
(4)优化
- 任务:中间代码 → 高效的中间代码。 即在于对前段产生的中间代码进行加工变换,以期在最后阶段能产生出更为髙效(省时间和空间)的目标代码。优化的主要方面有:公共子表达式的提取、循环优化、删除无用代码等等。有时,为了便于“并行运算”,还可以对代码进行并行化处理。
- 依据:等价变换规则
- 变换方法:公共子表达式的提取、循环优化、删除无用代码、并行处理等
(5)目标代码生成
- 任务:把中间代码(或经优化处理之后)变换成特定机器上的低级语言代码。这阶段实现了最后的翻译,它的工作有赖于硬件系统结构和机器指令含义。
这阶段工作非常复杂,涉及的主要问题:
- 指令的选择
- 内存的分配
- 寄存器的分配
- 目标代码的形式:
- 绝对指令代码:这种目标代码可立即执行
- 汇编指令代码:需汇编器汇编之后才能运行
- 可重定位的指令代码(现代多数的情况):在运行前必须借助于一个连接装配程序把各个目标模块(包括系统提供的库模块)连接在一起,确定程序变量(或常数)在主存中的位置, 装入内存中指定的起始地址,使之成为一个可以运行的绝对指令代码程序。
、
目标代码形式为可重定位的指令代码的背后其实支撑的是源代码的模块化。
2、编译程序的结构
(1)编译程序总框
上述编译过程的五个阶段是编译程序工作时的动态特桩。编译程序的结构可以按照这五个阶段的任务分模块进行设计
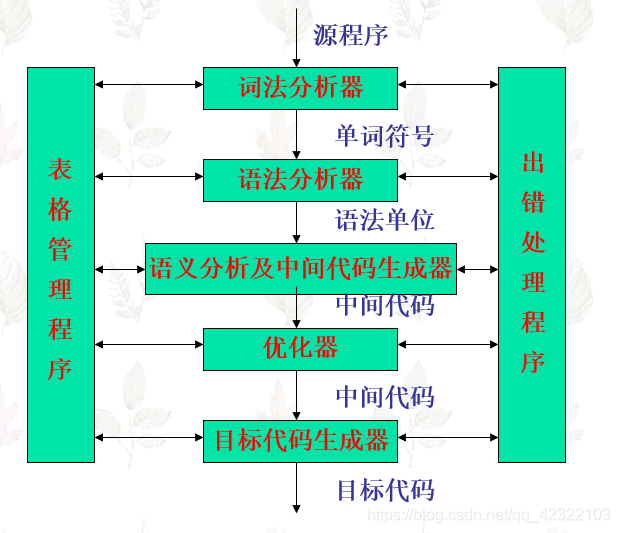
- 词法分析器,又称扫描器,输人源程序,进行词法分析,输出单词符号。
- 语法分析器,简称分析器,对单词符号串进行语法分析(根据语法规则进行推导或归约),识别出各类语法单位,最终判断输入串是否构成语法上正确的“程序”
- 语义分析与中间代码产生器,按照语义规则对语法分析器归约出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间代码。
有的编译程序在识别出各类语法单位后,构造并输出一棵表示语法结构的语法树,然后,根据语法树进行语义分析和中间代码产生。还有许多编译程序在识别出语法单位后并不真正构造语法树,而是调用相应的语义子程序。在这种编译程序中,扫描器、分析器和中间代码产生器三者并非是截然分开的,而是相互穿插的。 - 优化器,对中间代码进行优化处理。
- 目标代码生成器,把中间代码翻译成目标程序
除了上述五个功能模块外,一个完整的编译程序还应包括“表格管理”和“出错处理”两部分
(2)表格与表格管理
本质是一个数据结构,编译程序在工作过程中需要保持一系列的表格,以査记源程序的各类信息和编译各阶段的进展状况。
在编译程序使用的表格中,最重要的是符号表。它用来登记源程序中出现的每个名字以及名字的各种属性。
此外,还有与管理、构造、查找、更新有关的表格。
(3)出错处理
任务:发现并向用户指出源程序中错误的性质和位置。如果可以的话,自动校正错误。
错误有以下类型:
词法错误:不符合词法规则
语法错误:不符合语法规则
- 非法字符、括号不匹配、缺少 ;、…
语义错误:不符合语义规则
- 说明错误、作用域错误、类型不一致、…
(4)遍(pass):
遍:就是对源程序或源程序的中间结果从头至尾扫描一次,并作有关的加工处理,生成新的中间结果或目标程序的处理过程。
比如小明一天五节课(对应五个阶段),其中有一节是劳动课,课程内容是将垃圾运到垃圾处理区,第一次的路程(对应第一遍),将可回收垃圾运过去了,第二次的路程(对应第二遍)将不可回收垃圾运过去了。小明做这件事有了两次路程(对应两遍)
如果小明一次性都运过去了,那么这一节课就只有一次路程(对应一遍)。
可以把一个阶段分为若干遍,也可以把多个阶段合为一遍,通常有一遍和多遍编译程序。
一个编译程序究竟应分成几遍,如何划分,是与源语言、设计要求、硬件设备等诸因素有关的,因此难于统一划定。遍数多一点有个好处,即整个编译程序的逻辑结构可能清晰点(也可能有更多的优化)。但遍数多势必増加输人/输出所消耗的时间。因此,在主存可能的前提下,一般还是遍数尽可能少一点为好。应当注意的是,并不是每种语言都可以用单遍编译程序实现。
(5)编译的前端与后端:
前端(front end) :由与源语言有关但与目标机无关的部分组成。
后端(back end) :包括与目标机有关的部分。而一般不依赖于源语言,只与中间代码有关的编译阶段。

3、编译程序的生成
这个地方书写的非常拗口,其实理解很简单,就是我现在有一个简易的编译器A,它可以编译A语言,A语言的语法虽然简单,但是只要符合语法,编写出来的代码就能通过A编译器的编译,并能在计算机上执行。
这个时候,我希望语法更丰富点,我就用A语言写了一个编译器B,编译器B支持的语法更加丰富些,可以抽象成B语言,只要符合B语言的语法,编写出来的代码就能通过B的编译,最终能够在计算机上执行(本质上还是A的作用,只不过抽象了一层,编译过程做了更多转换的事情)。
这个就引出来一个方式、即自编译方式:先实现语言的内核编译再进行自编译扩展,先实现某语言的编译再用该语言实现另一语言的编译,即编译—>编译程序。
参考:陈火旺、刘春林等,《程序设计语言编译原理》,国防工业出版社,第三版
