目录
ROUTING NETWORKS: ADAPTIVE SELECTION OF NON-LINEAR FUNCTIONS FOR MULTI-TASK LEARNING
总结
问题:多任务虽然能彼此受益,但也会产生串扰(task inferference)。
解决思路:让网络自主决定共享或独立的结构。和cross-stitch(对比算法之一)很像。
具体方案:本文提出的routing network paradigm:一个self-organizing network及其训练方法。
效果:训练代价不随任务数增长而增长,而是几乎恒定。在CIFAR-100和20个任务上,训练时间比cross-stitch少85%。
不足:
- 虽然作者提供了定性实验结果(qualitative results),但对routing结果仍然无法解释。
- 仍然有很多超参数需要设置,例如block的数量。作者简单处理:有多少任务,就设置多少block(每层)。
动机
根据Caruana,MTL的优势是:利用多任务之间的共性来提升泛化能力。作者解释:
This means a model must leverage commonalities in the tasks (positive transfer) while minimizing interference (negative transfer).
因此,作者就提出了一个面向MTL的routing network,包括两个组分:router和多个function block。Router在固定的循环深度下,规划(指定)若干block参与。不参与的block即被跳过,前后状态保持不变。
理想情况下,positive transfer由共享的function block实现,而negative transfer可以通过独立的block避开。
相关工作
传统MTL结构:Caruana介绍的传统多任务深度学习方法,需要合理地设计网络结构。例如让底层特征共享。但routing networks更进一步,让整个网络全动态、可组装,可以根据不同的任务自主调整结构。
Transfer learning:在一些transfer learning工作中,这种自动化的选择机制也被广泛研究。例如有用attention的,有学习gating机制的。但我们不仅考虑2个任务,而是考虑多达20个任务。并且我们将其中一个工作作为对比实验。
Mixtures of experts architectures:输入多个专家模型,得到多个输出加权。这种soft mixture decision和hard routing decision不同。它们也没有刻意去建模一些重要的效应。
Dynamic representations:生成一些权重系数,来得到一个最优的神经网络。但它们普遍无法承受深度模型和大量参数。而routing可以实现轻量化dynamic network。
Minimizing computational costs for single-task problem:包括REINFORCE,Q Learning和actor-critic methods。本文更强调MTL,因此采用了multi-agent reinforcement learning训练算法和一个递归决策过程。
准确地说,我们的工作是automated architecture search。文本是第一篇MTL+hard routing decision。
Routing networks
Routing:重复地使用router,来选择一系列function block,组装在一起服务于输入。
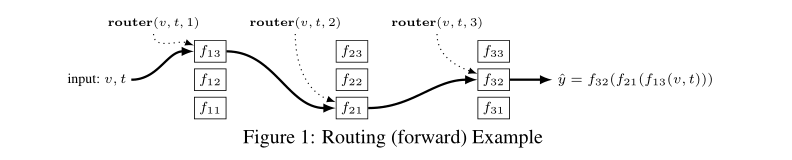
如图,输入一个向量v,其为待分类的一个样本,类别是t(也就是任务序号)。Router分别选择了f13,f21和f32(应该是一个分类层),因此最终的预测就是\(\hat{y}\)。
具体算法如下表,很简单。

注意:
- 输入参数:最大递归深度\(n\)和任务序号(得已知)。
- router可以选择跳过某一深度。
- router需要输入当前状态,不一定是输入x。
- 这里每一层的blocks数目一样。若不一样,我们可以让每一层的router,即decision function独立。
任何一个神经网络都可以改造成routing networks,方法:将每一层的layer复制多份,作为function blocks。
训练
采用collaborative multi-agent reinforcement learning(MARL),共同训练router和function block。
Reward有两种:在每一层(每一次动作)提供的immediate action reward和一个final reward。
- Final reward鼓励网络的高性能。对于分类任务中的一个训练样本,如果分类正确,则加1,否则减1。
- Immediate reward鼓励网络用更少的blocks。作者有两个策略:(1)历史上(迭代前)该block被选择的平均次数;(2)平均概率。作者发现二者没有显著区别,并选择了(2)。该reward要乘以一个系数\(\rho\)。如果只考虑性能,如图12,该系数肯定是越小越好(最好为0)。
RL算法的选择有很多:
- 单agent,即所有任务共享一个policy。
- Multi-agent,每个任务都有一个agent,学习各自的policy。这是本文的实验最佳方案。
- 在multi-agent的基础上,再增加一个dispatching agent,专用于分配agent。即,我们不再要求每个任务对应各自的agent,而是由dispatching agent来决定。
block和router policy在同时更迭,而作者发现效果不佳。而Weighted policy learner (WPL)可以解决这种MARL的非静态环境的不稳定问题。WPL可以抑制振荡,加快agent的收敛。其做法是放缩梯度,当policy远离纳什均衡时减小学习率,反之增大学习率。
WPL算法如文中算法表3。
实验
作者将Optimization as a model for few-shot learning中的convnet改造为routed版本,并在3个图像分类数据集上实验。一个标签相当于一个任务。
对比算法就是cross-stitch networks和Caruana介绍的joint training strategy with layer sharing。
数值结果我们就不说了。我们看一看qualitative experiments中的一个。通过对MNIST实验的可视化,我们得到如下routing:
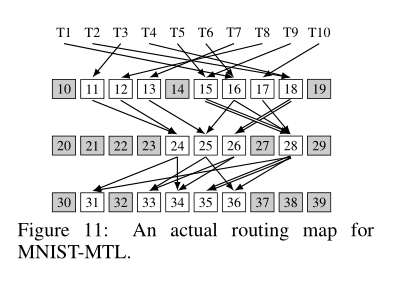
也就是说,传统MTL鼓励低层特征共享,但在routing networks中呈现出7-4-5的梨形。作者不知道为什么这是最佳MTL方案,但实验证实这比静态的baseline效果更好。
其余略。