笔记目录:
【Spark实战】慕课网日志分析(一):数据初步清洗
【Spark实战】慕课网日志分析(二):数据二次清洗之日志解析
【Spark实战】慕课网日志分析(三):清理后数据的存储、统计和入库
【Spark实战】慕课网日志分析(四):将数据清洗的作业提交到YARN上运行
【Spark实战】慕课网日志分析(五):将数据统计和入库的作业提交到YARN上运行
一、通过maven打包项目
1.环境中已有模块的不需要打包
2.pom.xml要添加如下plugin
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
3.控制台打包。执行命令:mvn assembly:assembly
打包成功:
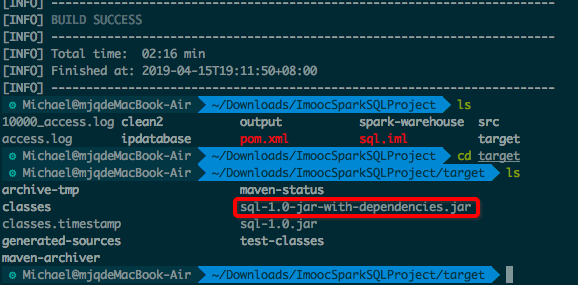
将上述jar包复制到虚拟机:

将日志文件access.log复制到hdfs:
hadoop fs -mkdir -p /imooc/input
hadoop fs -put access.log /imooc/input
二、使用spark-submit提交作业
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-submit \
--class com.imooc.log.SparkStatCleanJobYARN \
--name SparkStatCleanJobYARN \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
/home/hadoop/lib/sql-1.0-jar-with-dependencies.jar \
hdfs://hadoop001:8020/imooc/input/* hdfs://hadoop001:8020/imooc/clean
网页上显示执行成功:

可以看到输出的文件结果已经保存到hdfs中:

接下来,进入spark控制台,读取数据,验证日志是否清晰正确
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-shell --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
进入spark控制台后,执行:
spark.read.format("parquet").load("hdfs://hadoop001:8020/imooc/clean/day=20170511/part-00000-e24e8ede-4f27-4328-a8d7-f51726d2f829.snappy.parquet").show(false)
结果如下:

这里遇到了city字段全部为“未知”的错误。
原因:YARN上面缺少地址解析所需要的两个文件:
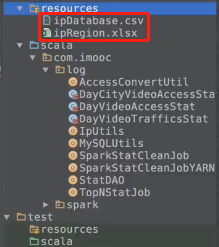
解决方案:
第一步:先将两个文件上传到YARN:

第二步:在命令中加上--files,重新使用spark-submit提交作业:
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-submit \
--class com.imooc.log.SparkStatCleanJobYARN \
--name SparkStatCleanJobYARN \
--master yarn \
--executor-memory 1G \
--num-executors 1 \
--files /home/hadoop/lib/ipDatabase.csv,/home/hadoop/lib/ipRegion.xlsx \
/home/hadoop/lib/sql-1.0-jar-with-dependencies.jar \
hdfs://hadoop001:8020/imooc/input/* hdfs://hadoop001:8020/imooc/clean
运行成功:

接下来,进入spark控制台,读取数据,验证日志是否清晰正确
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-shell --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
进入spark控制台后,执行:
spark.read.format("parquet").load("hdfs://hadoop001:8020/imooc/clean/day=20170511/part-00000-248ad663-d26b-4dd0-a1b4-a207ff3d29d2.snappy.parquet").show(false)
成功得到正常的city字段:
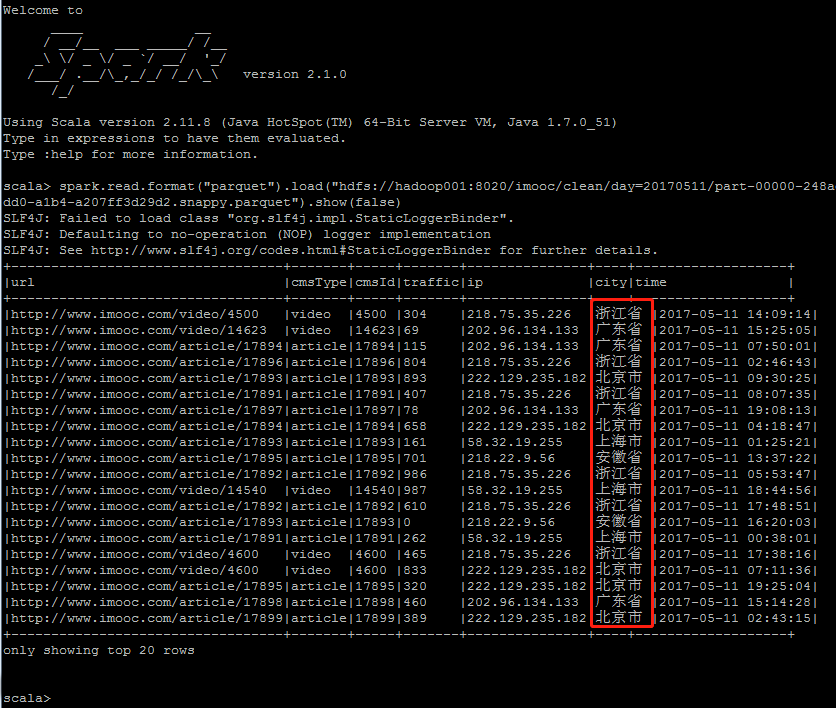

至此,之前再本地IDEA上的数据清洗的作业,已经成功提交到YARN上运行。