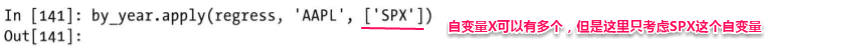数据的聚合与分组运算—进阶
使用分组的值填充数据缺失值
pandas中,缺失值可以使用较为粗鲁的dropna方法去除,但是更多时候想用一个定值或者数据集本身衍生出来的值去填充缺失值,此时使用fillna方法,这两个方法的使用具体可见先前笔记。
首先回顾一般情况下的缺失值填充,


一般的在数据未分组的情况下可以直接对Series和Dataframe使用fillna方法,但是如果数据已经被分组,要针对每一组进行缺失值的填充,这个过程就相对比较复杂了,需使用apply方法和fillna方法的组合。比如下例,
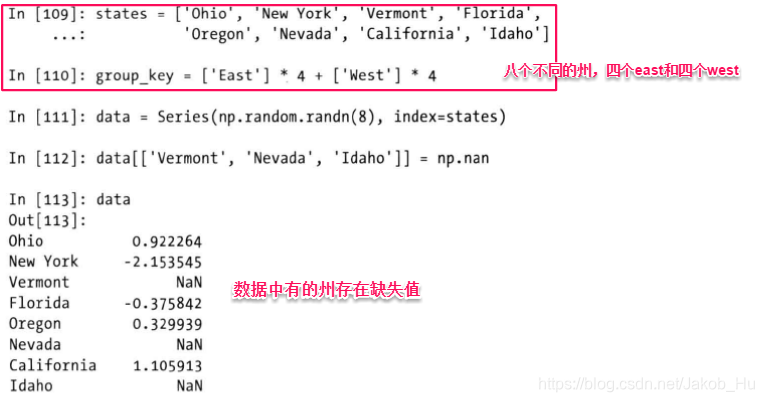

为了便于理解,下面两行代码用于注释,

也可以设置固定值对缺失值进行填充,比如设置使用0.5填充East组,-1填充West组,
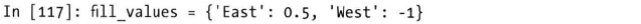

随机采样和排列
进行随机采样的一个较高效的方法是选取np.random.permutation(N)的前K个元素,其中N为完整数据的样本量,K是选取的子集。下面的代码构造出一副扑克牌(不含大猫小猫),A-10的点数对应[ 1, 10 ],J、Q、K的点数设定均为10,


1)整体随机采样—numpy库permutation方法
从上面这副扑克牌中随机抽5张出来,

2)分组采样
如果想从每个花色中随机抽两张,则必须使用到分组和apply方法,

分组加权平均数和相关系数
Dataframe的列与列之间,两个Series之间的运算是经常会用到的,首先构建一组数据集,

这组数据有分组,有权重,还有每条记录的一个数据,

利用category列进行分组,根据每个样本的权重值,对每组求加权平均数,

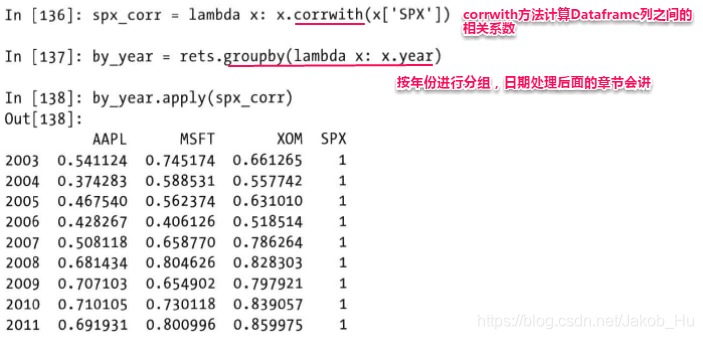
一个比较实用的例子是使用Yahoo的finance数据集进行分析,数据集中有标准普尔500指数(SPX)和几个股票的收盘价格,

需求是计算日收益率与SPX之间的年度相关系数,首先计算得到收盘价较前一天的增长率,
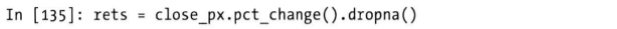
分组数据线性回归
对分组数据进行线性回归是更为复杂的操作,定义一个regress方法对各组进行线性回归(使用最小二乘法),还是使用上面的股票数据进行分析,

计算AAPL和SPX之间的线性关系,