深入浅出MySQL索引(一)常见的索引模型
一、为什么需要索引?
MySQL的数据存放在数据表中,数据表会被保存在磁盘上,例如下面我们创建一个数据表,那么在磁盘上就会有一个数据表文件来存放数据
create table users(
id int,
name varchar(16)
) engine=innodb;
接下来我们往数据表中添加数据
insert into users(
id,
name
)
values(
10,
"小明"
),(
2,
"小红"
),(
5,
"小白"
)
# ...
;
如果在没有索引的情况下,假如数据以追加的形式添加到数据表中,那么它的存储形式如下

那么这样会出现什么问题呢?
如果我要查询在users表中查询id=100的所有记录,对于上述的情况,只能做一次全表扫描,就是将数据表的记录从磁盘中读出来,然后一条一条的判断记录的id是否等于100,这会带来两个问题
-
如果users表中有一百万行数据,那么每次读取都要扫描一百万行
-
另外如果users表非常大,那么我们不可能一次将所有的数据读到内存,需要分多次读取磁盘,而操作磁盘相对于内存来说是一个非常耗时的操作
我们可以通过建立索引来解决问题,那么什么是索引?

打个比方,我们在查找书中的内容的时候,一般都会先从目录开始查找,可以简单地理解索引就相当于书的目录,所谓的索引就是以特定的数据结构来组织这个目录
在介绍具体的索引模型之前,我们先通过一个例子来看索引的重要性
首先创建一个没有索引的数据表users,然后创建一个存储过程idata,调用idata插入一百万行数据
create table users(
id int,
name varchar(16)
) engine=innodb;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000000)do
insert into users values(i, "name");
set i=i+1;
end while;
end;;
delimiter ;
call idata();
接下来我们查找id=989999的记录
mysql> select * from users where id=989999;
+--------+------+
| id | name |
+--------+------+
| 989999 | name |
+--------+------+
1 row in set (0.25 sec)
可以看到,这个操作花费了0.25 sec
接下来我们在id上建立索引
alter table users add index on id;
接下来继续执行查询语句
mysql> select * from users where id=989999;
+--------+------+
| id | name |
+--------+------+
| 989999 | name |
+--------+------+
1 row in set (0.00 sec)
可以看到,这次查询花费了0.00 sec
通过这个列子可以看出索引多么的强大,接下来我们就来讨论什么样的数据结构适合做索引
二、常见的索引模型
2.1 有序数组
我们指定一个列为索引,然后按照这个列的值排序,以有序数据存放入数据表中,如下所示
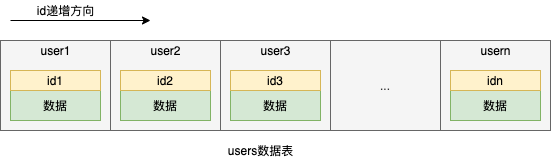
这样,我们在查找数据的时候,就可以通过id这个列,在数据表中进行二分查找,二分查找的时间复杂度为O(logn),这是非常快的
另外由于数据是有序存放的,所以支持范围查找,只要找到起始值然后往后扫描判断,就可以检索出范围内的值
但是使用有序数组的情况,如果是插入或者删除数据,就会非常的麻烦。可以想象,插入数据需要将后半部数据往后挪动一个位置,删除数据需要将后半部数据往前挪动一个位置,这样的代价是非常大的,所以这也是没有使用有序数组来组织索引的原因
2.2 哈希表
我们指定一个列为索引,然后将这个列的值作为key,将数据放到哈希表其中的一个bucket中,如下所示

你可能会好奇,如何在文件中组织哈希表呢?
其实主要的问题是在文件中怎么表示指针,指针是指向一个地址的,在文件中这个地址是由数据在文件的偏移量表示,弄清楚这一点后,我们来看一下哈希表组织索引的特点
我们在查找数据的时候,就可以通过id这个列作为key,在哈希表中查找,理论上哈希表的时间复杂度是O(1),所以查找数据会非常快
但是哈希表是无序的,所以我们无法利用索引进行范围查找,只能利用索引来进行等值查询
2.3 二叉搜索树
我们指定一个列为索引,然后将这个列的值作为key,来组织一棵二叉搜索树,如下所示

对于平衡二叉树来说,查找的时间复杂度为O(logn),所以查找速度也非常快
二叉搜索树是有序的,所以也支持范围查找
这么一说,其实二叉搜索树来做索引是个不错的选择,其实非也
首先我们要明确的一点是,这棵树是存在于磁盘中,每次我们都要从磁盘中读取出相应的节点,然而二叉搜索树的节点在文件中是随机存放的,所以可能读取一个节点就需要一个磁盘IO,恰恰二叉搜索树都会比较高,如一棵一百万个元素的平衡二叉树就有十几层高度了,也就是大部分情况下检索一次数据就需要十几次磁盘IO,这个代价太高了,所以一般二叉搜索树也不会被用来作索引
其实用二叉搜索树作为索引,从功能上来讲已经非常优秀,我们可以改进它,不就是树太高吗,那我们想办法使其高度降低。这就可以使用多路搜索树,也就是B Tree,当每个节点的分支多了,这棵树的高度自然就降低了,每次读取需要的磁盘IO也就减少了
2.4 B-Tree
B-Tree的每个节点都是一个页,可以存放多个数据节点,每页中的节点都是有序的,左子树的节点小于当前节点,右子树节点大于当前节点,InnoDB中规定一个页大小为16K,使用B-Tree作为索引如下所示

B-Tree的查找过程是,因为每个页中的节点都是有序的,所以在每个页中都可以使用二分查找,而B-Tree的高度又会很低,所以查找效率会很快
一个页有16k,假设平均一条数据大小为100,那么一个页就可以放160条记录,三层高度的B-Tree就可以存放400多万条记录,四层高度就可以存放6亿多条记录,B-Tree的高度一般为3-5层。而根节点一般都是缓存在内存中的,所以一般只需要2-4次磁盘IO就可以查询到指定的数据
2.5 B+Tree
B+Tree相对于B-Tree,有两个区别
- 非节点只存放索引key,不存放数据,数据只存在于叶子节点
- 叶子节点页之间使用链表连接
如下所示

因此带来的几个好处
- B+Tree的磁盘读写代价更低:由于非叶子节点只存放索引不存放数据,所以每个节点可以存放更多的索引,一次读取查找的关键字更多,树的高度更低
- B+Tree的查询效率更加稳定,因为只有叶子节点存在数据,所以每次查询的路径长度都是相同的
- B+Tree更适合范围查询,因为B-Tree的非叶子节点存放数据,所以需要使用中序遍历来查询,而B+Tree只有叶子节点有数据,叶子节点之间使用链表连接,所以只要顺序扫描进行,更加方便
基于上述的原因,B+Tree比B-Tree更适合做数据库索引
本篇文章介绍了为什么需要索引,以及常见的索引模型,后续文章我们将来介绍MySQL的InnoDB存储引擎的索引
